






由于LLaMA没有使用RLHF,后来有一个初创公司 Nebuly AI使用LangChain agent生成的数据集对LLaMA模型使用了RLHF进行学习,得到了ChatLLaMA模型,详情请参考:Meta开源的LLaMA性能真如论文所述吗?如果增加RLHF,效果会提升吗?,其实RLHF未必是必须的,主要是高质量的标注数据获取成本比较高,RLHF是一个trade-off。
StackLLaMA模型介绍
今天分享的StackLLaMA是按照InstructGPT论文的方法获得的,它的目的是,在算法流程上和ChatGPT类似,大致流程如下:
-
监督微调 (SFT)
-
奖励/偏好建模 (RM)
-
从人类反馈中强化学习 (RLHF)
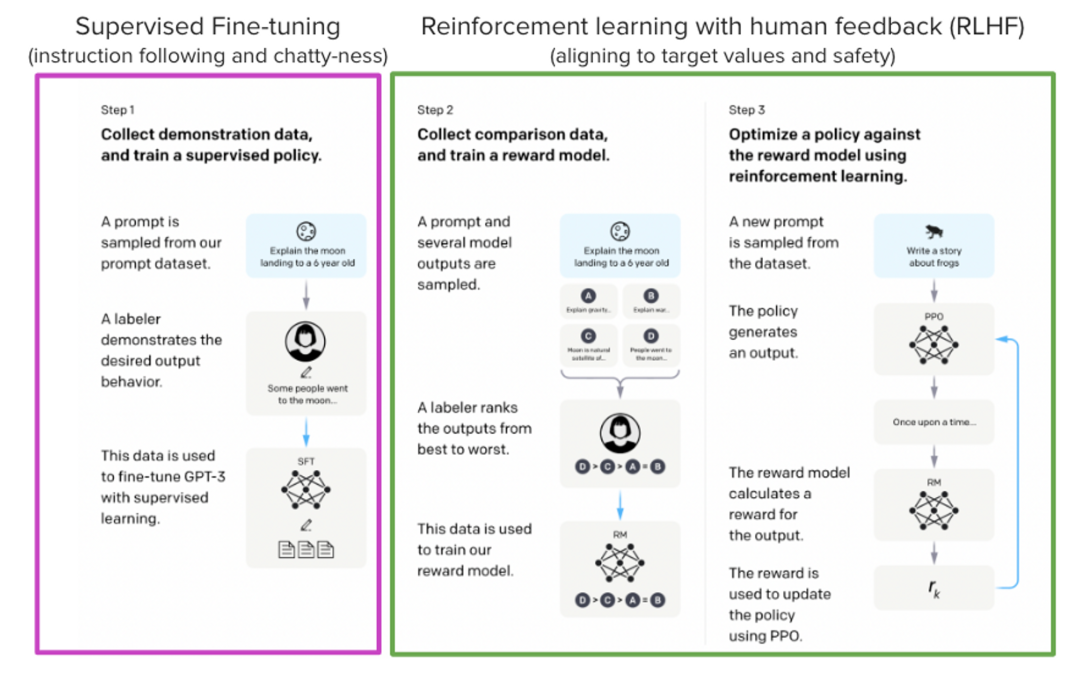
主要区别在于:
基础模型:ChatGPT使用的是GPT3.5,StackLLaMA使用的是LLaMA;
SFT阶段:StackLLaMA使用的是StackExchange 数据集
(https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences),而ChatGPT的简单数据没有公开;
StackLLaMA的主要共贡献
-
-
StackLLaMA模型开源了,并且在Huggingface Hub上可以使用,地址:https://huggingface.co/trl-lib/llama-7b-se-rl-peft;
-
集成到Hugging Face TRL库,为广大朋友提供了基础库使用,地址:https://huggingface.co/docs/trl/index;
-
开源了监督训练数据集StackExchange,地址:https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences;
-
开源了数据集和处理笔记本https://huggingface.co/datasets/lvwerra/stack-exchange-paired;
-
介绍了训练过程的细节以及解决方案;
-
RLHF库:https://github.com/lvwerra/trl
-
Stack Exchange数据集
该数据集包括来自 StackExchange 平台的问题及其相应的答案(包括针对代码和许多其他主题的 StackOverflow)
根据论文《https://arxiv.org/abs/2112.00861》介绍,给每个答案一个score,公式如下:
score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).
对于奖励模型,始终需要每个问题有两个答案进行比较。对每个问题最多采样 10 个答案对,以限制每个问题的数据点数量。最后,将 HTML 转换为 Markdown 来清理格式,使模型的输出更具可读性。
高效的训练策略
即使训练最小的 LLaMA 模型也需要大量内存,比如bf16,每个参数需要2个字节来存储,fp32需要4个字节,更多可以参考:https://huggingface.co/docs/transformers/perf_train_gpu_one#optimizer。对于一个 7B 参数的模型,只是参数就需要(2+8)*7B=70GB的内存,实际存储还包括计算注意力分数等中间值,可能需要更多内存。因此,即使是7B的模型也无法在单个 80GB A100 上训练模型。
使用参数高效微调 (PEFT) 技术,比如使用https://github.com/huggingface/peft库来实现,这种技术可以加载8-bit模型执行低秩自适应 (LoRA),如下图所示:
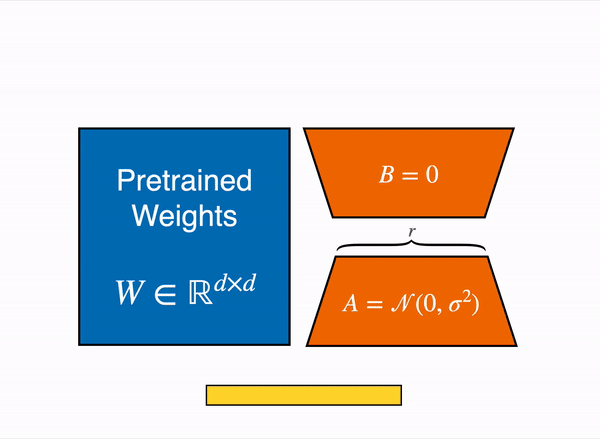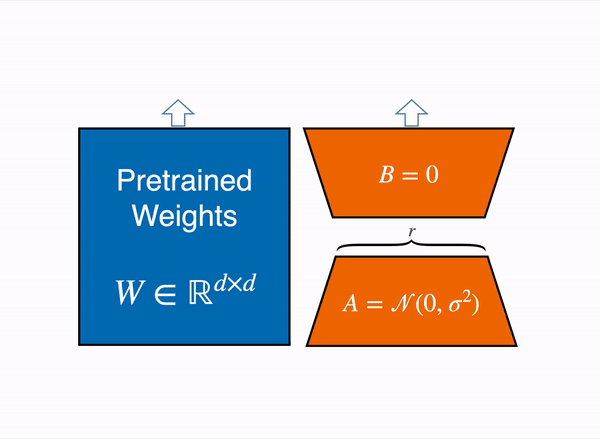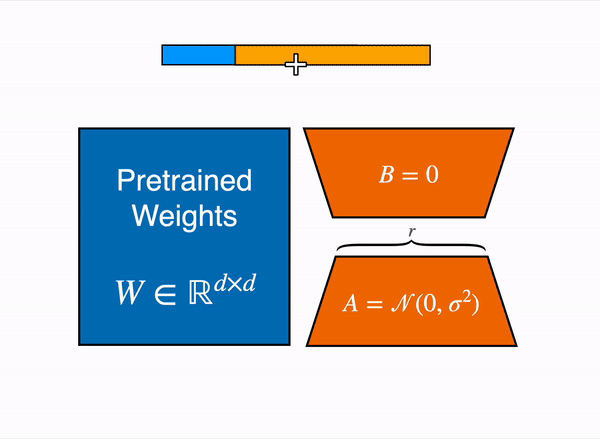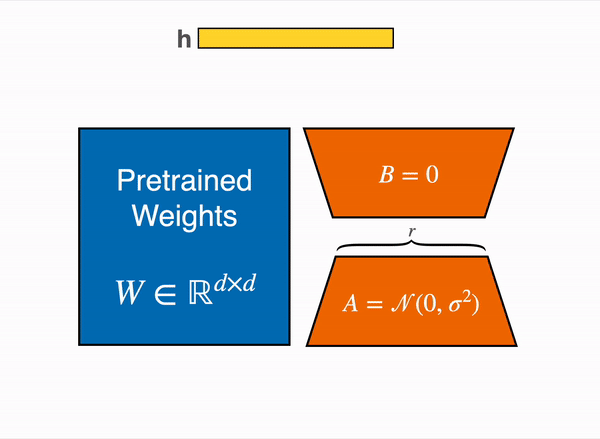
线性层的低秩自适应:在冻结层(蓝色)旁边添加额外参数(橙色),并将生成的编码隐藏状态与冻结层的隐藏状态一起添加。
8-bit模型,每个参数只需要一个字节(例如,7B LlaMa 的内存为 7GB)。LoRA 不是直接训练原始权重,而是在某些特定层(通常是注意力层)之上添加小的适配器层;因此,可训练参数的数量大大减少。
在这种情况下,根据batch大小和序列长度不同每十亿个参数大概需要1.2-1.4GB内存,这可以以低成本微调更大的模型(在 NVIDIA A100 80GB 上高达 50-60B 比例模型)。
这些技术可以在消费级设备和 Google Colab 上微调大型模型。比如:facebook/opt-6.7b(13GB in float16)和openai/whisper-largeGoogle Colab(15GB GPU RAM)。更多参考:https://github.com/huggingface/peft和https://huggingface.co/blog/trl-peft
将非常大的模型放入单个 GPU 中,如果训练速度仍然很慢,可以使用数据并行技术,如下图所示:
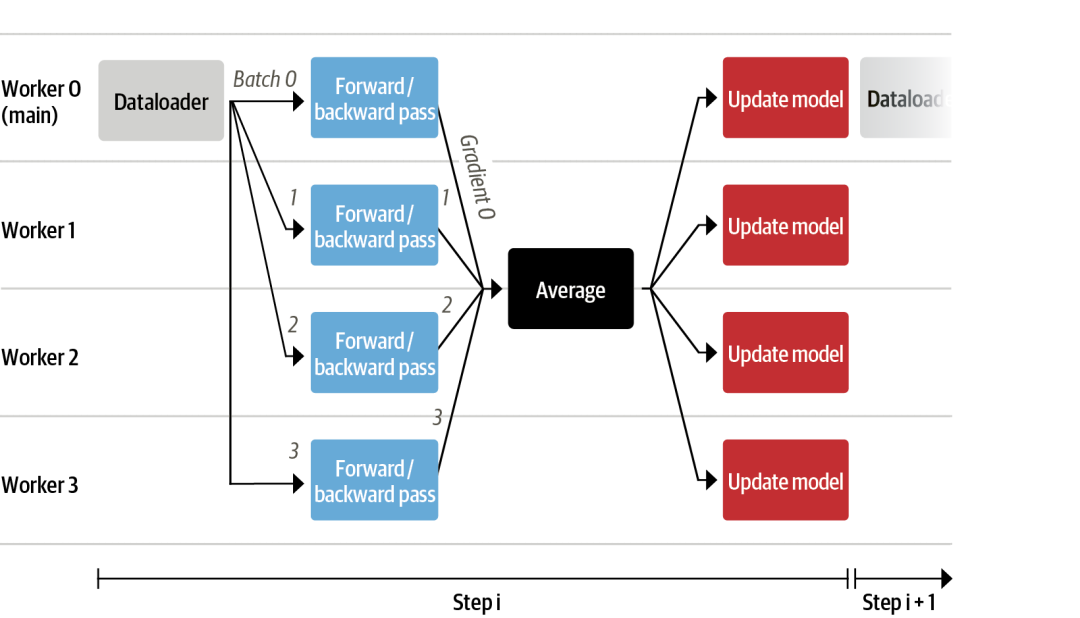
数据并行可以使用transformers.Trainer和accelerate,无需任何代码更改,只需在使用torchrunor调用脚本时传递参数即可accelerate launch。下面分别用accelerate和在单台机器上运行带有 8 个 GPU 的训练脚本torchrun。
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.pytorchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py
监督微调SFT
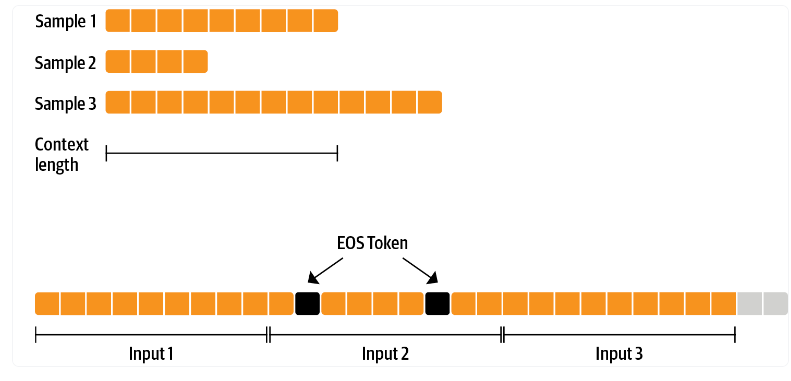
首先需要对监督数据做一些处理,传统方式通常是需要保证每个batch中序列长度是一样(采用填充或者截断),与传统的方式不同,GPT模型监督数据是把多个sentence通过EOS标记拼接到一起来使用,如下图所示:
使用peft加载模型之后就可以使用Trainer训练模型了。具体是:首先
首先导入int8模型,然后加入到训练准备,最后再添加LoRA adapters,代码如下所示:
# load model in 8bitmodel = AutoModelForCausalLM.from_pretrained(args.model_path,load_in_8bit=True,device_map={"": Accelerator().local_process_index})model = prepare_model_for_int8_training(model)# add LoRA to modellora_config = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.05,bias="none",task_type="CAUSAL_LM",)model = get_peft_model(model, config)
Note:最终预测的时候需要把LoRA adapters的模型参与与LLaMA模型参数加起来使用。
通过运行脚本(https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py)将它们转换为 🤗 Transformers 格式。
奖励建模和人类偏好
奖励模型的目标是模仿人类如何评价文本。建立奖励模型有几种可能的策略:最直接的方法是预测注释(例如评分或“好”/“坏”的二进制值)。在实践中,更好的方法是预测两个例子的排名,奖励模型必须预测哪一个会被人类标注人员评分更高。
这可以转化为以下损失函数:
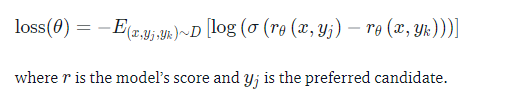
使用 StackExchange 数据集,我们可以根据分数推断用户更喜欢这两个答案中的哪一个。有了这些信息和上面定义的损失,就可以使用transformers.Trainer通过添加自定义损失函数来修改。
class RewardTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()if return_outputs:return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}return loss
训练集100000个样本的子集,评估集50000个样本,batch大小为4,采用LoRA adapter(bf16混合精度的Adam优化器)fine-tuning LLaMA模型。LoRA 配置如下:
peft_config = LoraConfig(task_type=TaskType.SEQ_CLS,inference_mode=False,r=8,lora_alpha=32,lora_dropout=0.1,)
在 8个A100 GPU 训练了几个小时,训练的Weights & Biases记录地址:https://wandb.ai/krasul/huggingface/runs/wmd8rvq6?workspace=user-krasul
模型最终达到了67% 的准确率。虽然这听起来分数很低,但任务也非常艰巨,即使对于人工标注者也是如此。
如下一节所述,生成的适配器可以合并到冻结模型中并保存以供下游进一步使用。
从人类反馈中强化学习RLHF
有了经过微调的语言模型和奖励模型,我们现在可以运行 RL 循环了。大致分为三个步骤:
-
根据提示生成响应
-
使用奖励模型对响应进行评分
-
使用评级运行强化学习策略优化步骤
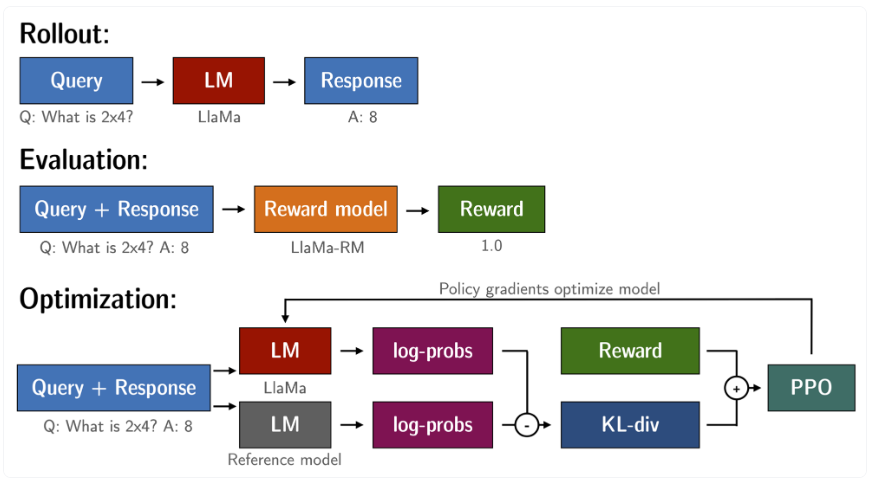
Query and Response模板如下:
Question: <Query>Answer: <Response>
SFT、RM 和 RLHF 阶段使用相同的模板。
使用 RL 训练语言模型的一个常见问题是,奖励模型为了得到高的reward,通常会生成一些完整的乱码序列。为了解决这个问题,在reward中增加了一个KL散度的惩罚,公式如下:
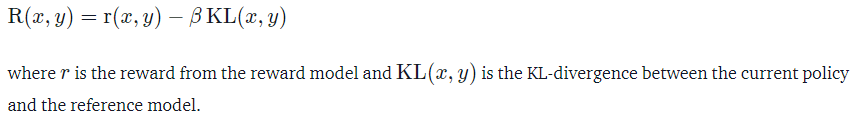
训练的时候,首先导入8-bit的SFT模型并且冻结参数,然后使用PPO优化LoRA参数,代码如下:
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):question_tensors = batch["input_ids"]# sample from the policy and generate responsesresponse_tensors = ppo_trainer.generate(question_tensors,return_prompt=False,length_sampler=output_length_sampler,**generation_kwargs,)batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)# Compute sentiment scoretexts = [q + r for q, r in zip(batch["query"], batch["response"])]pipe_outputs = sentiment_pipe(texts, **sent_kwargs)rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]# Run PPO stepstats = ppo_trainer.step(question_tensors, response_tensors, rewards)# Log stats to WandBppo_trainer.log_stats(stats, batch, rewards)
在 3x8 A100-80GB GPU 上训练了 20 小时,也可以使用更少的资料(例如,在 8 个 A100 GPU 上训练约 20 小时后)。训练过程每个step的reward变化如下图所示:
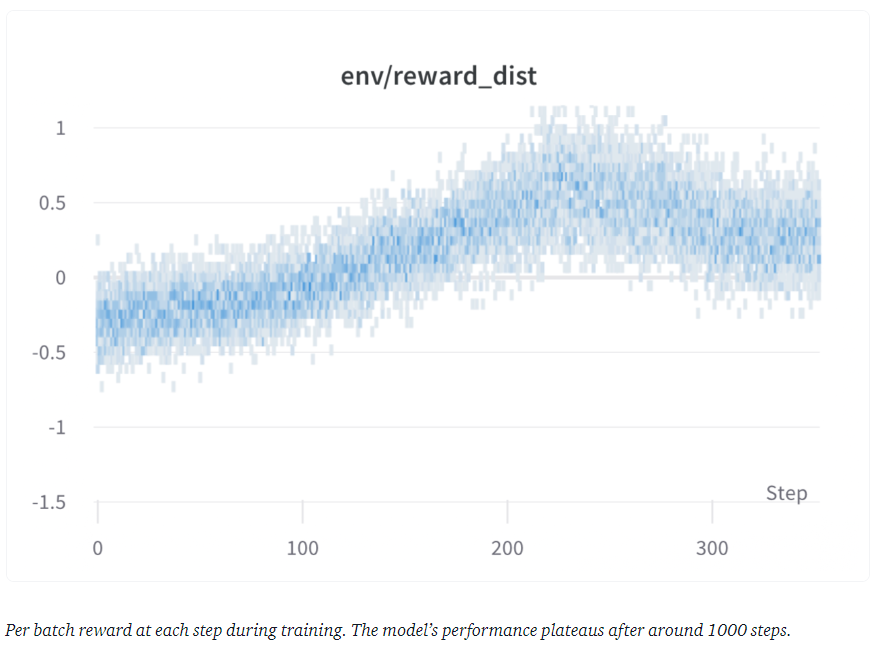
模型的性能在大约 1000 步后达到稳定状态。
StackLLaMA模型效果

答案看起来连贯,甚至提供了一个谷歌链接。让我们来看看接下来的一些训练挑战。
StackLLaMA模型训练的一些坑以及解决方案
-
更高的reward意味着更好的表现吗?
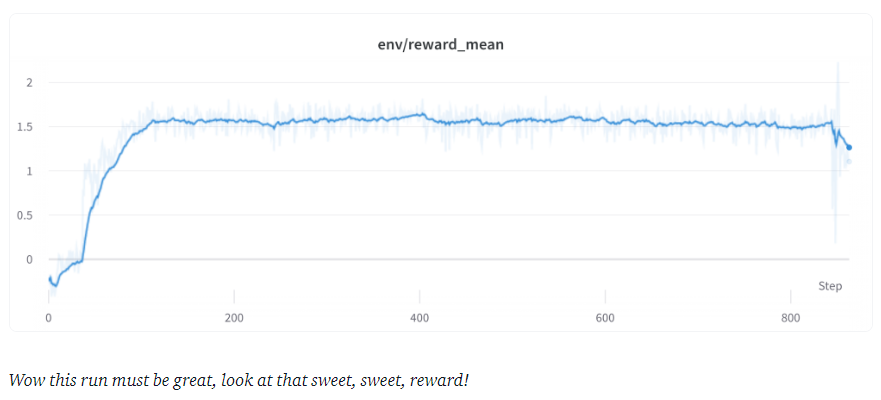
一般来说,在 RL 中希望获得最高的reward,但是在 RLHF 中,使用了一个不完美的奖励模型,PPO 算法将利用这些不完美,这可能表现为奖励的突然增加,但是当我们从策略中查看文本生成时,它们主要包含字符串 ``` 的重复,因为奖励模型发现包含代码块的stack exchange答案reward分数是最高的。幸运的是,这个问题很少被观察到,一般来说,KL 惩罚应该可以抵消这种攻击。
-
KL 总是一个正值,不是吗?
通常,KL 散度衡量两个分布之间的距离,并且始终为正数。然而,在trl库使用 KL 的估计值时,希望期望分布与实际分布尽可能接近。
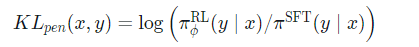
显然,当从概率低于 SFT 模型的策略中采样token时,这将导致负 KL 惩罚,但平均而言它将是正的,否则您将无法从策略中正确抽样。然而,一些生成策略可以强制生成一些token或者可以抑制一些token。例如,当批量生成完成的序列时,会填充序列,当设置最小长度时,EOS 令牌会被抑制。该模型可以为那些导致负 KL 的token分配非常高或低的概率。当 PPO 算法针对奖励进行优化时,它会追逐这些负面惩罚,从而导致不稳定,如下图所示:
在生成答案的时候,建议先使用简单的采用策略,后面再提高采用的复杂程度。
-
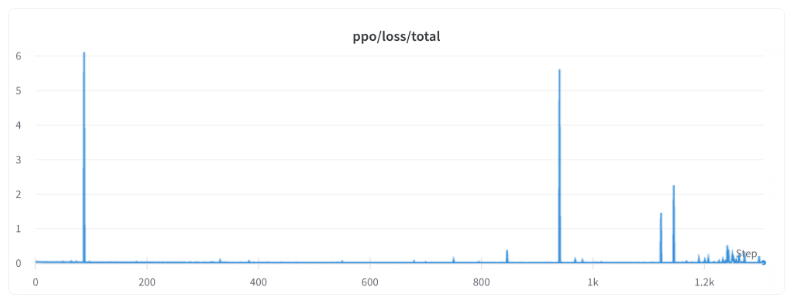
持续的问题
还有一些问题需要更好地理解和解决。例如,损失偶尔会出现峰值,这可能会导致进一步的不稳定性。
















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











