







写在前面:
前部分依旧是技术流的教程copy及相关笔记。但说实话,在复现这一部分中,遇到了很多问题,后面的QA我会把遇到的进行记录。
课程背景是XTuner 团队放出了基于 Llama3-8B 的 LLaVA 模型。然后机智流带领我们基于 Llama3-8B-Instruct 和 XTuner 团队预训练好的 Image Projector 微调多模态图文理解模型 LLaVA。
LLaVA模型,即文本单模型LLM和训练出来的Image Projector的组合。
| 训练阶段 | LLM+(文本与图像的问答对)----(显卡)---->Image Projector |
| 测试阶段 | Image Projector + LLM + 输入图像 ----(显卡)---->输出文字 |
这里附上机智流的Llama3教程链接:
1、环境配置
同上一章节(下载好模型、权重以及必要的依赖)
# 创建镜像并下载依赖
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
# 安装git
mkdir -p ~/model
cd ~/model
apt install git git-lfs -y
# 获取权重模型
git clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
# 下载llama3的机智流的教程工具包,里面有一些数据集和web的展示程序
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
# 安装XTuner
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .2、模型训练
训练Image Projector文件的过程主要有2个阶段:Pretrain和Finetune。
1)Pretrain阶段:
预训练阶段,此阶段会使用大量的(图片+文本标签)进行训练,使得LLM具有简单的理解图像能力。
但这只是预训练部分,所以对于用户的提问,只会回答图片的标题。
其阶段对硬件的要求很高,对于贫民的咱来说,主要还是进行Finetune微调阶段。
2)Finetune阶段
微调阶段,在这一阶段,会使用(图片+复杂文本),对预训练模型进一步训练。
为了快速学习,我这里还是使用的机智流的图片例子,后续会新出章节记录训练数据的构建至自定义模型的训练。
(1)查看并复制配置文件
# 查询xtuner内置配置文件
xtuner list-cfg -p llava_internlm2_chat_1_8b
# 拷贝配置文件到当前目录
xtuner copy-cfg \
llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune \
/root/tutorial/xtuner/llava
(2)修改配置文件
说其是配置文件,实际是训练的python代码,在其中修改相应的参数。
vi编辑修改文件llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py。
# Model(模型的路径,前一个是llm模型的地址,后一个是clip图文表征模型的地址,用于图文转换)
- llm_name_or_path = 'internlm/internlm2-chat-1_8b'
+ llm_name_or_path = '/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b'
- visual_encoder_name_or_path = 'openai/clip-vit-large-patch14-336'
+ visual_encoder_name_or_path = '/root/share/new_models/openai/clip-vit-large-patch14-336'
# Specify the pretrained pth(预训练模型的地址)
- pretrained_pth = './work_dirs/llava_internlm2_chat_1_8b_clip_vit_large_p14_336_e1_gpu8_pretrain/iter_2181.pth' # noqa: E501
+ pretrained_pth = '/root/share/new_models/xtuner/iter_2181.pth'
# Data(数据源信息)
# data_root:训练数据目录
# data_path:训练数据文件名
# image_folder:镜像文件夹路径
- data_root = './data/llava_data/'
+ data_root = '/root/tutorial/xtuner/llava/llava_data/'
- data_path = data_root + 'LLaVA-Instruct-150K/llava_v1_5_mix665k.json'
+ data_path = data_root + 'repeated_data.json'
- image_folder = data_root + 'llava_images'
+ image_folder = data_root
# Scheduler & Optimizer(每次训练批次数目)
# 这里不宜过大,除非对显卡有自信,不然容易爆显存
- batch_size = 16 # per_device
+ batch_size = 1 # per_device
# evaluation_inputs(训练过程中会根据给定的问题进行评估,便于观察训练状态)
- evaluation_inputs = ['请描述一下这张图片','Please describe this picture']
+ evaluation_inputs = ['Please describe this picture','What is the equipment in the image?']
(3)训练模型
cd /root/tutorial/xtuner/llava/
xtuner train /root/tutorial/xtuner/llava/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py --deepspeed deepspeed_zero2训练语句中,train后面为训练的一键式脚本py文件,即执行这个脚本。
这里使用了XTuner中的优化技术deepSpeed ZaRO来降低显卡消耗。
3)性能对比:
使用机智流的测试图像为下:

(1)Finetune之前
# 解决小bug
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
# pth转huggingface
xtuner convert pth_to_hf \
llava_internlm2_chat_1_8b_clip_vit_large_p14_336_e1_gpu8_pretrain \
/root/share/new_models/xtuner/iter_2181.pth \
/root/tutorial/xtuner/llava/llava_data/iter_2181_hf
# 启动!
xtuner chat /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \
--visual-encoder /root/share/new_models/openai/clip-vit-large-patch14-336 \
--llava /root/tutorial/xtuner/llava/llava_data/iter_2181_hf \
--prompt-template internlm2_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg参数说明:
前两行是设置环境变量,主要是防止pytorch做分布式训练时出现bug。(貌似只要设置一行就可以)。
xtuner convert pth_to_hf ${配置文件地址(也就是上面的py文件)} ${权重文件地址} ${转换后模型的保存地址}
除此之外,还可以添加两个额外的参数:
| fp32 | 代表以f32精度开启,默认为fp16 |
| max-shard-size{GB} | 代表每个权重文件最大大小,默认2GB |
xtuner chat为简单的模型对话指令,上述命令的参数含义为:
| visual-encoder | 编码器地址,这里是指定了clip的模型路径 |
| llava | 转换后的模型路径 |
| prompt-template | 提示词模板,如果指定错误可能会导致模型无法正确回复 |
| image | 指定分析的图片 |
执行上面的命令,并输入相应的问题,可以得到下面的输出:

(2)Finetune之后
# 解决小bug
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
# pth转huggingface
xtuner convert pth_to_hf \
/root/tutorial/xtuner/llava/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py \
/root/tutorial/xtuner/llava/work_dirs/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy/iter_1200.pth \
/root/tutorial/xtuner/llava/llava_data/iter_1200_hf
# 启动!
xtuner chat /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \
--visual-encoder /root/share/new_models/openai/clip-vit-large-patch14-336 \
--llava /root/tutorial/xtuner/llava/llava_data/iter_1200_hf \
--prompt-template internlm2_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg执行上面的命令,并输入相应的问题,可以得到下面的输出:
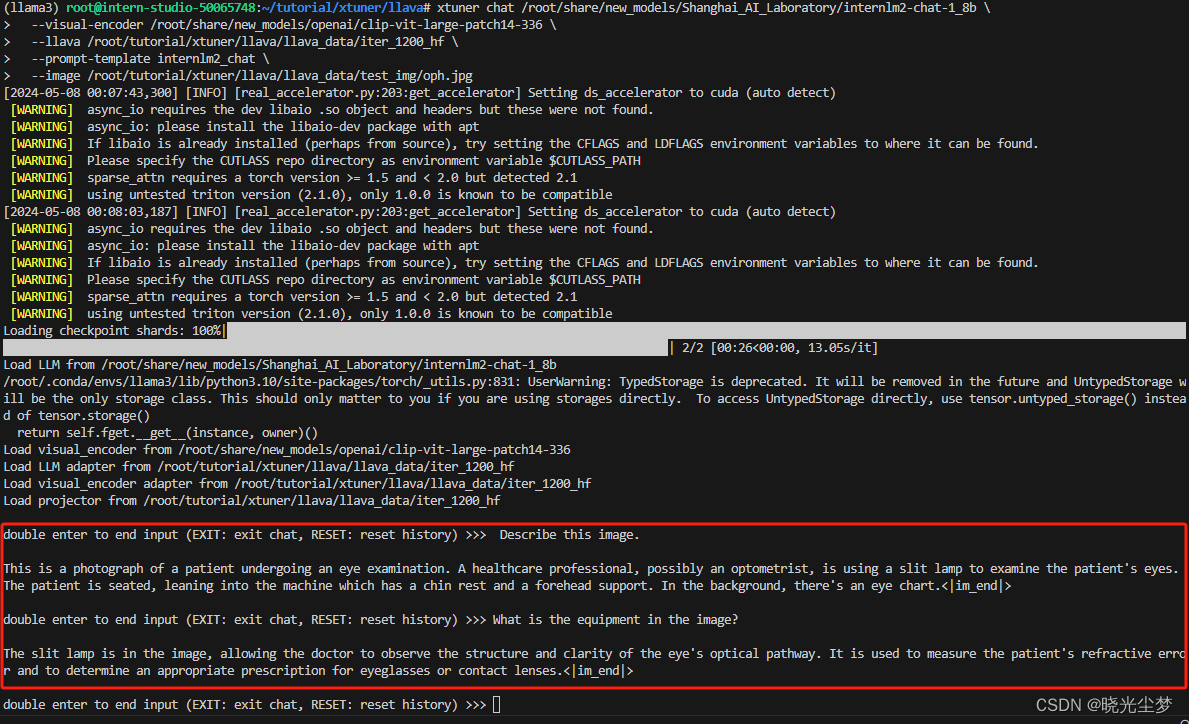
和前面微调相比,微调后的模型在回答问题时更加详细全面。
依旧挖坑,后续补章节自己训练数据并描述自定义图片。















 3439
3439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









