







一、知识准备
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在客户分类中,RFM模型是一个经典的分类模型,利用通用交易环节中最核心的三个维度——最近消费(Recency)、消费频率(Frequency)、消费金额(Monetary)细分客户群体,从而分析不同群体的客户价值。
二、数据来源
RFM数据集为英国在线零售商在2010年12月1日至2011年12月9日间发生的所有网络交易订单信息。该公司主要销售礼品为主,并且多数客户为批发商。"This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail.The company mainly sells unique all-occasion gifts. Many customers of the company are wholesalers."
数据集特征说明:
InvoiceNo:订单编号,由六位数字组成,退货订单编号开头有字母C
StockCode:产品编号,由五位数字组成
Description:产品描述
Quantity:产品数量,负数表示退货
InvoiceDate:订单日期与时间
UnitPrice :单价(英镑)
CustomerID:客户编号,由5位数字组成
Country:国家
数据集来源:
UCI Machine Learning Repository
三、实验目的
探讨如何利用KMeans算法(EM聚类)对客户群体进行细分,以及细分后如何利用RFM模型对客户价值进行分析,并识别出高价值客户。主要希望实现以下三个目标:
1)对客户进行群体分类
2)对不同的客户群体进行特征分析,比较各细分群体的客户价值
3)对不同价值的客户制定相应的运营策略
四、实验步骤及结果
4.1 导入必要库
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D4.2 获取数据
# 读取数据
data = pd.read_csv('F:/数据分析/data.csv.csv',encoding='ISO 8859-1')#导入数据文件,并规定文件编码
4.3 数据预处理
#删除完全重复行
data.drop_duplicates(inplace=True)
#删除CustomerID列有缺失的行
data.dropna(subset=['CustomerID'],inplace=True)
4.4 去除退货单
# 去掉退货单
data = data[data['Quantity'] > 0]
4.5 转换格式
# 转换InvoiceDate为日期格式
data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate'])4.6 分别计算R/F/M的值
# 计算R(Recency):最近一次购买距离今天的天数
current_date = datetime.now()
data['Recency'] = (current_date - data.groupby('CustomerID')['InvoiceDate'].transform('max')).dt.days
# 计算F(Frequency):购买次数
frequency = data.groupby('CustomerID')['InvoiceDate'].nunique().reset_index()
frequency.columns = ['CustomerID', 'Frequency']
# 计算M(Monetary):购买金额
data['TotalPrice'] = data['UnitPrice'] * data['Quantity']
monetary = data.groupby('CustomerID')['TotalPrice'].sum().reset_index()
monetary.columns = ['CustomerID', 'Monetary']4.7 合并RFM数据
# 合并RFM数据
rfm = data[['CustomerID', 'Recency']].drop_duplicates().merge(frequency, on='CustomerID').merge(monetary, on='CustomerID')4.8 对RFM做描述性统计分析并绘制直方图、三维散点图
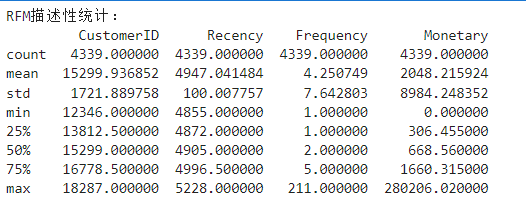
# R、F、M的描述性信息和可视化
print("RFM描述性统计:")
print(rfm.describe())
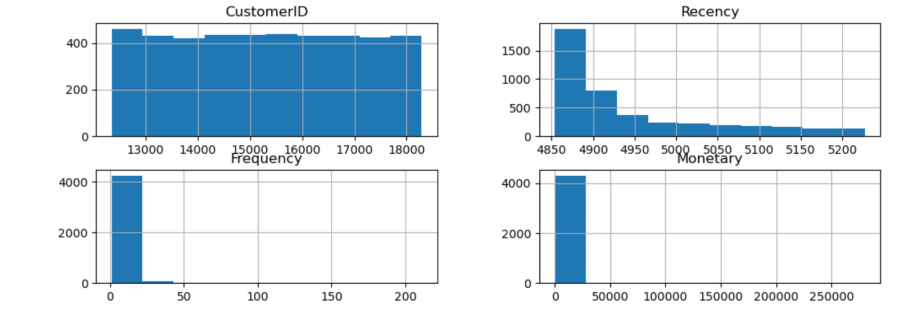
# 直方图
rfm.hist(figsize=(12, 4))
plt.show()
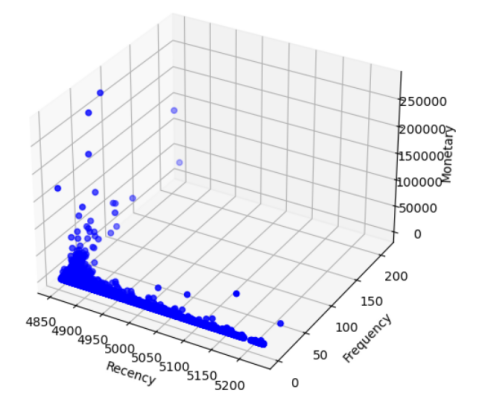
# 三维散点图
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(rfm['Recency'], rfm['Frequency'], rfm['Monetary'], c='blue', marker='o')
ax.set_xlabel('Recency')
ax.set_ylabel('Frequency')
ax.set_zlabel('Monetary')
plt.show()
4.9 对RFM进行标准化处理
# R、F、M标准化处理
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm[['Recency', 'Frequency', 'Monetary']])4.10 检查离群点并绘制箱型图
# 检查离群点
# 使用箱线图(Boxplot)来可视化离群点
import seaborn as sns
# 将标准化后的数据转换为DataFrame以便可视化
rfm_scaled_df = pd.DataFrame(rfm_scaled, columns=['Recency', 'Frequency', 'Monetary'], index=rfm.index)
# 绘制箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(data=rfm_scaled_df)
plt.title('Boxplot of Scaled RFM Data')
plt.show()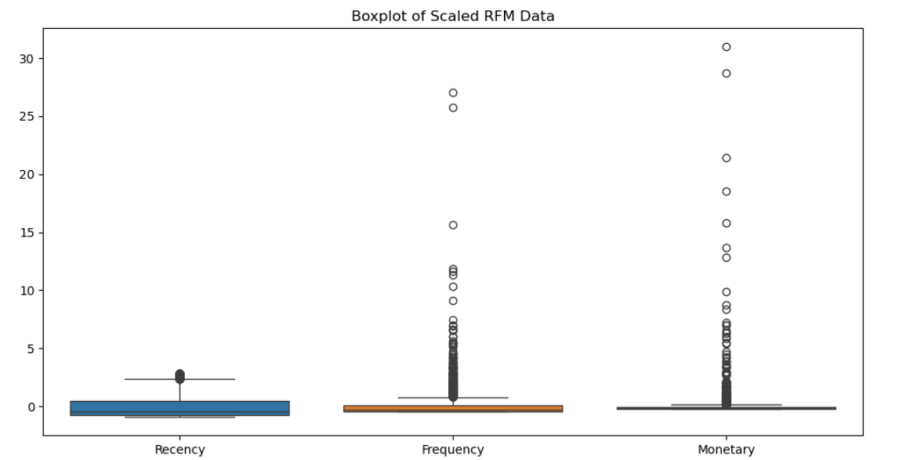
4.11 使用轮廓系数确定K值
# 使用轮廓系数确定最佳K值
silhouette_scores = []
for k in range(2, 10):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(rfm_scaled)
silhouette_scores.append(silhouette_score(rfm_scaled, kmeans.labels_))
plt.plot(range(2, 10), silhouette_scores, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Silhouette Score')
plt.show()
# 选择轮廓系数最高的K值
best_k = silhouette_scores.index(max(silhouette_scores)) + 2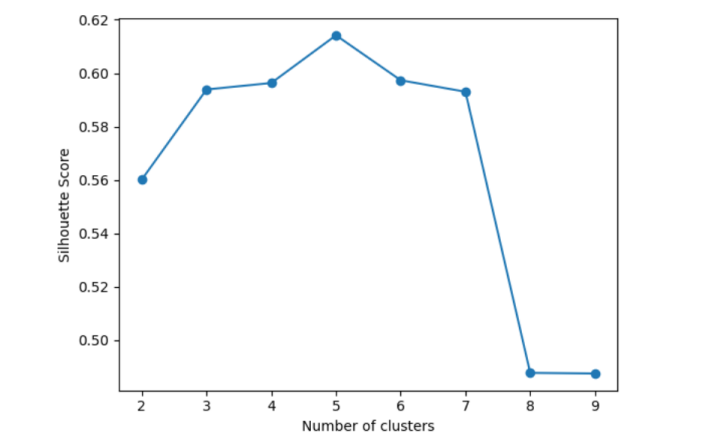
4.12 配置模型及训练模型
kmeans = KMeans(n_clusters=best_k, random_state=42)
kmeans.fit(rfm_scaled)4.13 模型结果
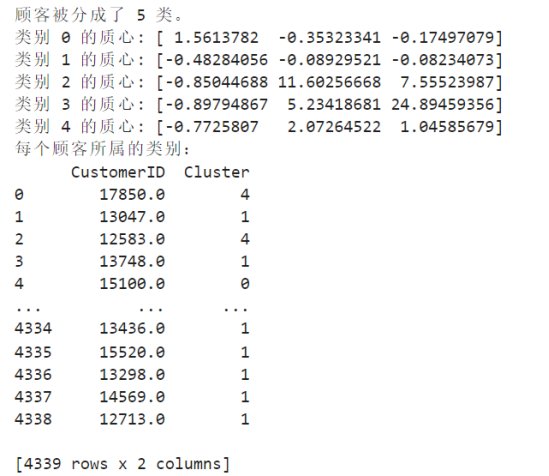
rfm['Cluster'] = kmeans.labels_
# 打印顾客被分成了几类
num_clusters = len(centroids)
print(f"顾客被分成了 {num_clusters} 类。")
# 打印每个类别的质心
for i, centroid in enumerate(centroids):
print(f"类别 {i} 的质心: {centroid}")
# 添加每个顾客属于哪一类的信息
rfm['Cluster'] = kmeans.labels_
print("每个顾客所属的类别:")
print(rfm[['CustomerID', 'Cluster']])
4.14 模型可视化
# 模型可视化
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
colors = ['r', 'g', 'b', 'y', 'c', 'm'] # 根据类别数量调整颜色
for i in range(best_k):
cluster_data = rfm[rfm['Cluster'] == i]
ax.scatter(cluster_data['Recency'], cluster_data['Frequency'], cluster_data['Monetary'], c=colors[i], label=f'Cluster {i}')
ax.scatter(centroids[:, 0], centroids[:, 1], centroids[:, 2], c='black', marker='x', s=100, label='Centroids')
ax.set_xlabel('Recency')
ax.set_ylabel('Frequency')
ax.set_zlabel('Monetary')
ax.legend()
plt.show()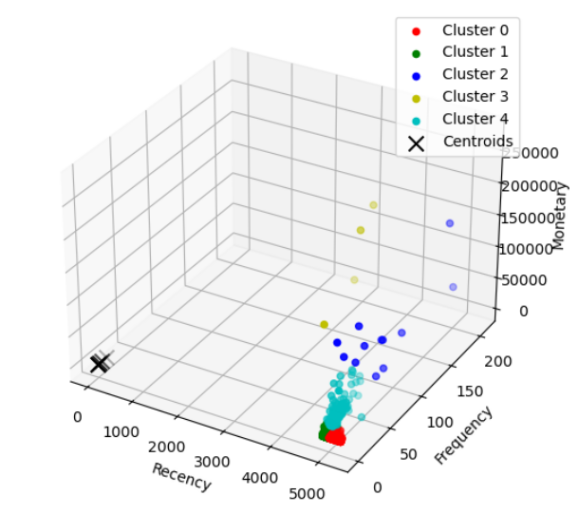
4.15 使用轮廓系数评价模型
# 使用轮廓系数评价聚类效果
final_silhouette_score = silhouette_score(rfm_scaled, kmeans.labels_)
print(f"最终的轮廓系数为: {final_silhouette_score:.4f}")轮廓系数(Silhouette Coefficient)是一种用于评估聚类算法性能的指标,它可以衡量每个样本与其所在聚类的紧密程度以及与其他聚类的分离程度,越接近1聚类效果越好。
4.16 结合RFM模型给各类贴标签
# 根据RFM的含义和质心位置,为每个类别定义标签
rfm['Customer_Segment'] = rfm['Cluster'].map({
0: 'High Value Customers',
1: 'Medium Value Customers',
2: 'Low Value Customers'
# 根据实际聚类结果调整标签
})
print("客户分类结果:")
print(rfm[['CustomerID', 'Cluster', 'Customer_Segment']])4.17 输出所有客户分类结果
rfm.to_csv('customer_segments.csv', index=False)本文不足及错误之处欢迎大家批评指正,感谢观看!

















 7112
7112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









