







 本文通过RFM模型和KMeans聚类对电商用户进行价值分析,揭示用户行为模式。利用Python进行数据处理和分析,得出用户主要集中在18-30岁,消费用户集中于广东、上海、北京。KMeans聚类结果表明,用户可分为三类,重点在于一般挽留客户和重要客户群体。建议针对用户年龄和地区制定运营策略。
本文通过RFM模型和KMeans聚类对电商用户进行价值分析,揭示用户行为模式。利用Python进行数据处理和分析,得出用户主要集中在18-30岁,消费用户集中于广东、上海、北京。KMeans聚类结果表明,用户可分为三类,重点在于一般挽留客户和重要客户群体。建议针对用户年龄和地区制定运营策略。
电商用户价值分析——基于RFM模型、KMeans聚类
一、背景
通过对用户价值进行分层,并针对不同用户制定不同运营策略以达到用户精准营销的策略。
二、RFM模型、KMeans聚类
美国数据库营销研究所Arthur Hughes的研究发现,在客户数据分析中发现了三个重要的指标,即:最近一次消费(Recency近度)、消费频率(Frequency频度)、消费金额(Monetary额度),它们是衡量客户价值的重要标准。RFM分析是一种探索性分析方法。
k-means简介
1.聚类算法(clustering Algorithms)介绍
聚类是一种无监督学习—对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。
2.k-means原理详解
k-means是一种常见的聚类算法,也叫k均值或k平均。通过迭代的方式,每次迭代都将数据集中的各个点划分到距离它最近的簇内,这里的距离即数据点到簇中心的距离。
三、分析框架

四、具体分析
1. 导入所需的库
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
import cufflinks as cf
cf.set_config_file(offline=True) # 离线模式绘图
2. 导入数据
data = pd.read_csv(r"D:\Desktop\python code\python数据分析\用户分群KMeans+RFM\产品销售分析.csv")
data.head()
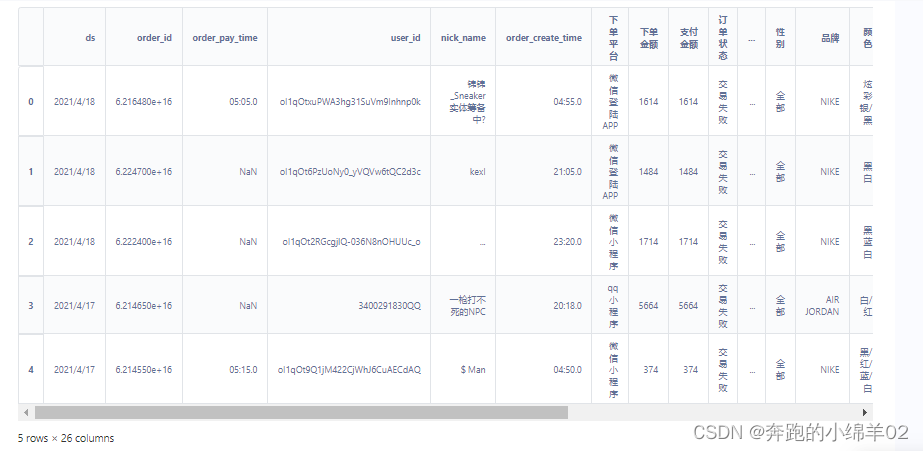
3. 数据清洗
缺失值处理
# 查看数据缺失
data.isnull().sum()
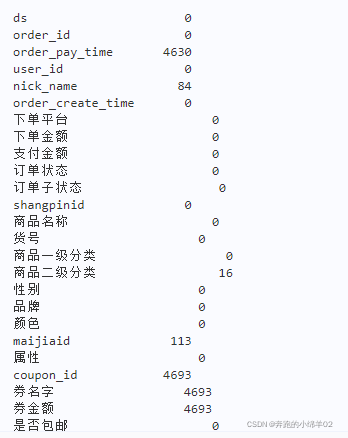
缺失值字段均为非核心字段,后续分析可直接提取有效字段。
重复值处理
#查看重复值
data.duplicated().sum()
0
异常值处理
#查找付款金额小于0的数据
abnormal=data[np.where(data['支付金额'] < 0,True,False)]
abnormal

4. 数据分析
4.1 核心数据分析
- 总GMV
#总GMV
GMV=round(data['支付金额'].sum(),ndigits=2)
4154205.04
- 每月GMV
#每月GMV
GMV_M=data.groupby(by='event_month',as_index=True).agg({
'支付金额':sum}).iplot(kind='line')
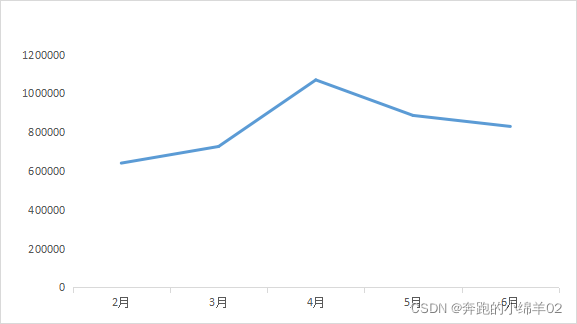
4月销售数据较大提升,可能是促销活动导致;
整体上销售数据趋势有所上升,但持续性无法得到保证
- 客单价
#客单价
price_uv=round(data['支付金额'].sum() / data['user_id'].nunique(),0)
88.59
- 笔单价
#笔单价
price_pv=round(data['支付金额'].sum() / data['order_id'].nunique(),0)
45.56
4.2 用户分析
年龄
# 先划分一下年龄
data['age_cut'] = pd.cut(data['age'],bins=[data.age.min(),20,30,40,data.age.max()],labels=['16-20' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1474
1474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









