




我们可以通过 Ollama 实现私有化部署大模型,并完成对话与 API 访问的基本功能。然而,此时的大模型还无法访问私有知识库。本文将介绍如何通过 AnythingLLM 与 Ollama 结合,搭建一个具备私有知识库能力的 AI 应用。
AnythingLLM 简介
AnythingLLM 是一款开箱即用的一体化 AI 应用,支持 RAG(检索增强生成)、AI 代理等功能。它无需编写代码或处理复杂的基础设施问题,适合快速搭建私有知识库和智能问答系统。
主要特性:
- 多种部署方式:支持云端、本地和自托管部署。
- 多用户协作:支持团队协作,适用于企业知识管理和客户支持。
- 多模型支持:兼容 OpenAI、Anthropic、LocalAI 等主流大模型。
- 多向量数据库支持:支持 Pinecone、Weaviate 等向量数据库。
- 多文件格式处理:支持 PDF、TXT、DOCX 等文件格式。
- 实时网络搜索:结合 LLM 响应缓存与对话标记功能,提供高效的文档管理和智能问答能力。
下载与安装Ollama
首先,我们需要下载 Ollama 以及配置相关环境。
Ollama 的 GitHub仓库 (https://github.com/ollama/ollama)中提供了详细的说明,简单总结如下:
Step1:下载 Ollama
下载(https://ollama.com/download)并双击运行 Ollama 应用程序。
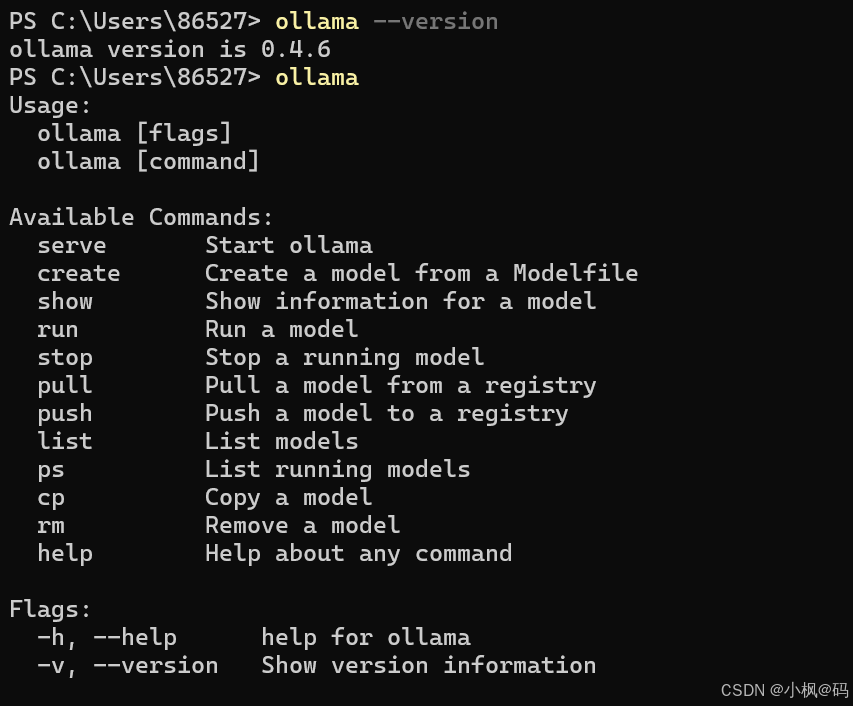
Step2:验证安装
在命令行输入 ollama,如果出现以下信息,说明 Ollama 已经成功安装。
Step3:拉取模型
deepseek-r1:1.5b 模型的大小为1.1g
ollama run deepseek-r1:1.5b
-
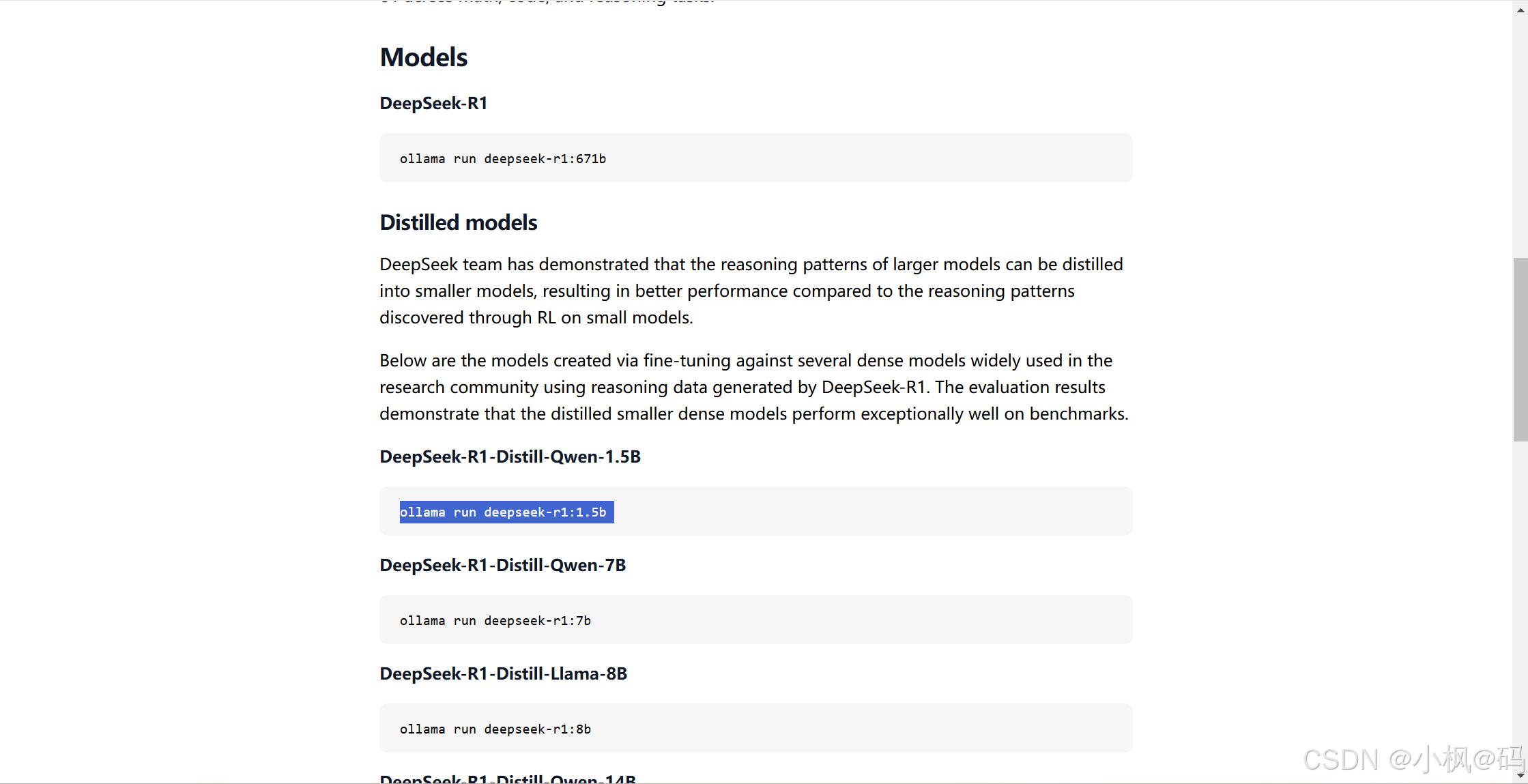
从命令行,参考 Ollama 模型列表 (https://ollama.com/library)和 文本嵌入模型列表 (https://python.langchain.com/v0.2/docs/integrations/text_embedding/)拉取模型。我们以 deepseek-r1:1.5b 和 nomic-embed-text 为例:
-
命令行输入 ollama pull deepseek-r1:1.5b,拉取通用的开源大语言模型 deepseek-r1:1.5b;(拉取模型时,可能比较缓慢。如果出现拉取错误,可以重新输入指令拉取)
-
命令行输入 ollama pull nomic-embed-text 拉取 文本嵌入模型 (https://ollama.com/search?c=embedding)nomic-embed-text。
-
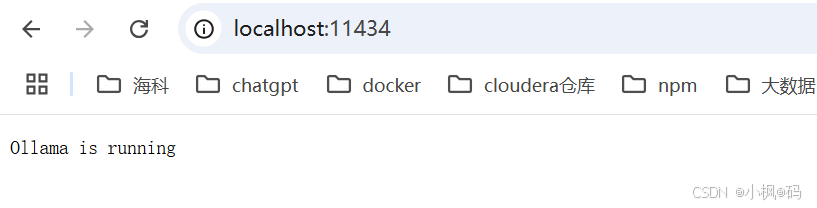
当应用运行时,所有模型将自动在 localhost:11434 上启动。
-
注意,你的模型选择需要考虑你的本地硬件能力,该教程的参考显存大小 CPU Memory > 8GB。
Step4:部署模型
命令行窗口运行以下命令,部署模型。
ollama run deepseek-r1:1.5b
下载与安装AnythingLLM
AnythingLLM 提供了 Mac、Windows 和 Linux 的安装包,用户可以直接从官网下载并安装。
安装完成后,首次启动时会提示配置偏好设置。用户可以根据需求进行设置,后续也可以随时修改。
配置 LLM 提供商
在 AnythingLLM 的设置页面,可以通过 LLM 首选项 修改 LLM 提供商。本文使用本地部署的 Ollama 和 deepseek-r1:1.5b 模型。配置完成后,务必点击 Save changes 按钮保存设置。
注意: 关于 Ollama 的部署与使用,请参考另外一篇博客。
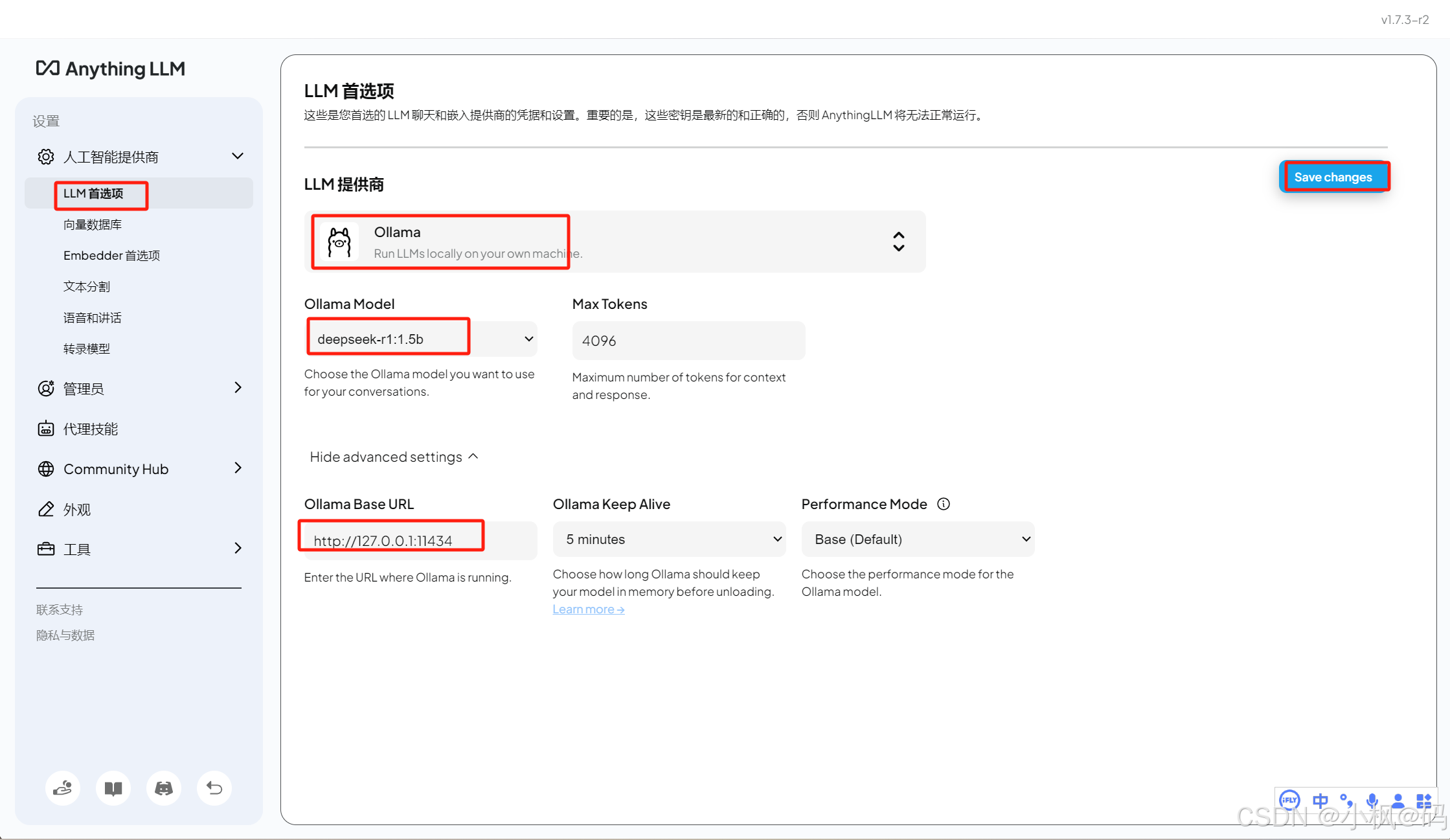
操作步骤如上:
1、点击 LLM 首选项
2、选择 Ollama 作为模型提供商
3、选择已安装的 DeepSeek 模型
4、注意下地址
5、保存
配置 Embedder首选项
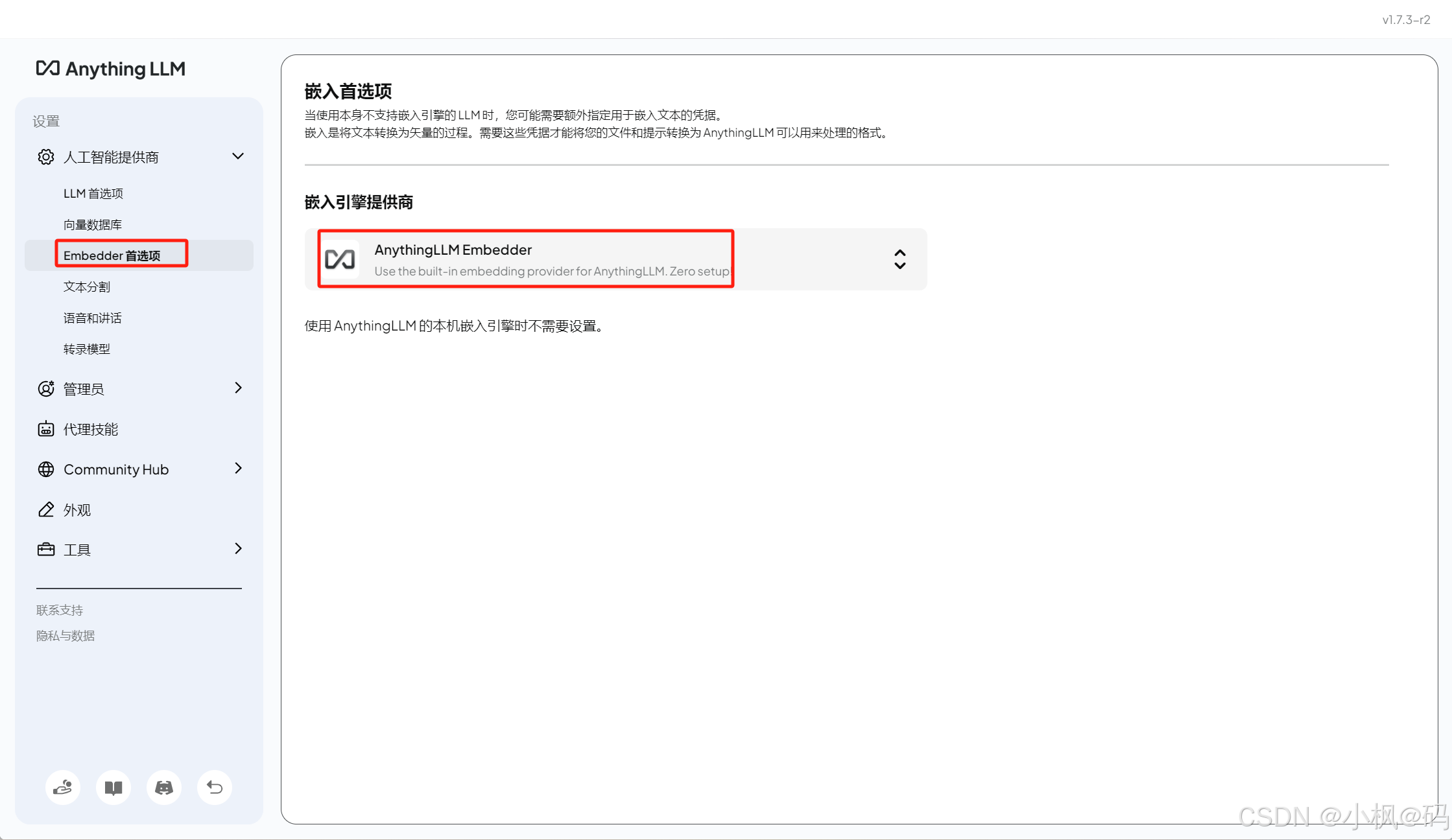
操作步骤如上:
1、向量数据库不用动即可,使用自带的(PS:如果没有选择安装目录,默认在C盘,如果后续有需要可以挪走)
2、嵌入模型配置
3、可以使用自带的,也可以使用 Ollama 安装好的
4、配置完点击左下角的返回即可
上传文档
在聊天界面中,用户可以创建多个工作区。每个工作区可以独立管理文档和 LLM 设置,并支持多个会话(Thread),每个会话的上下文也是独立的。
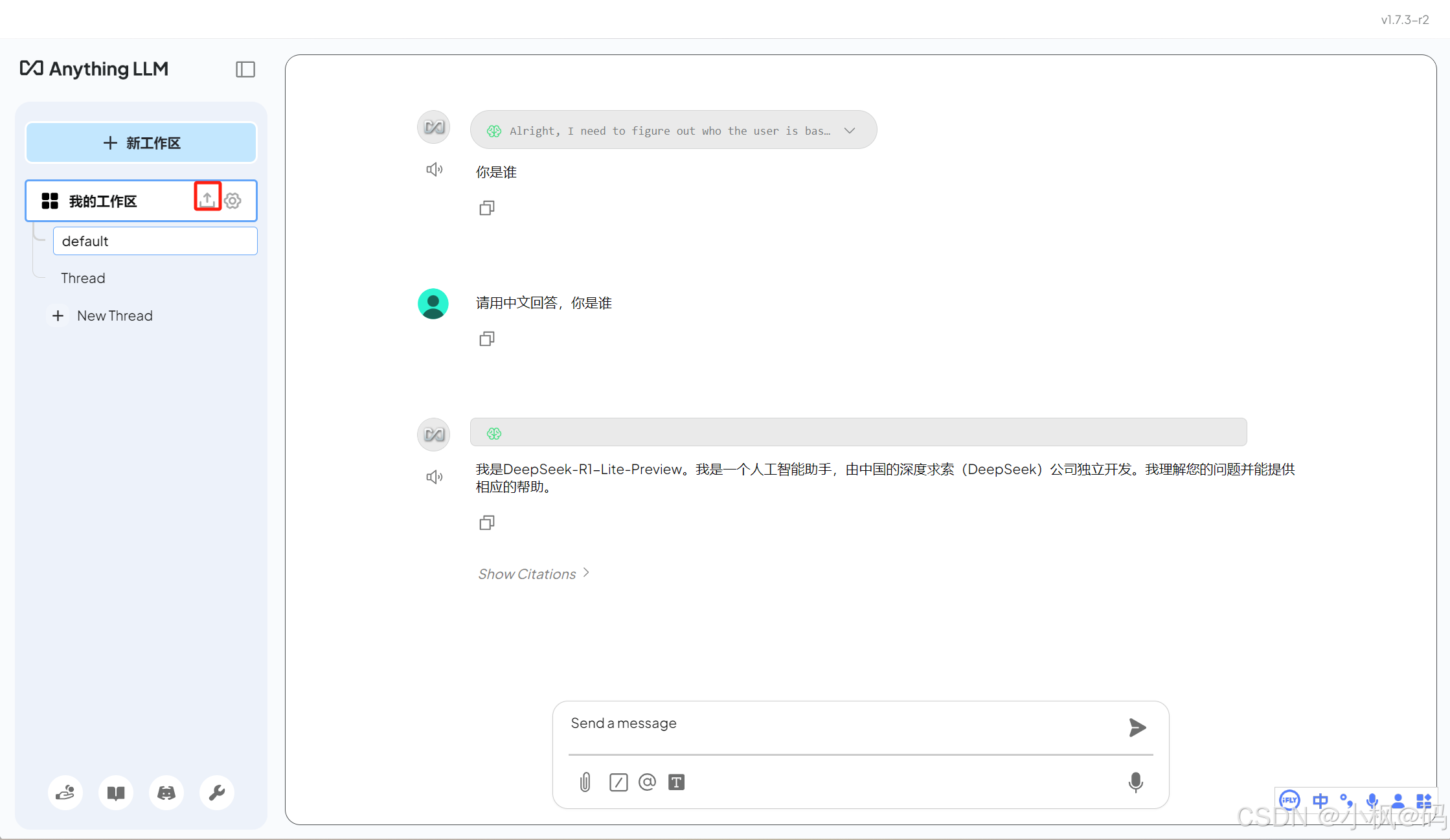
点击上传图标,可以管理当前工作区的知识库。AnythingLLM 支持以下三种方式上传文档:
- 本地文档上传:直接上传本地文件。
- Web 链接:通过 URL 上传网页内容。
- 数据链接:从 GitHub、GitLab 等平台导入数据。
Documents 界面
在 Documents 界面,用户可以管理已上传的文档,并通过下方的上传按钮或拖拽方式上传新文档。
提示: 如果需要上传整个目录及其子目录中的文档,直接将目录拖拽到上传按钮上即可。
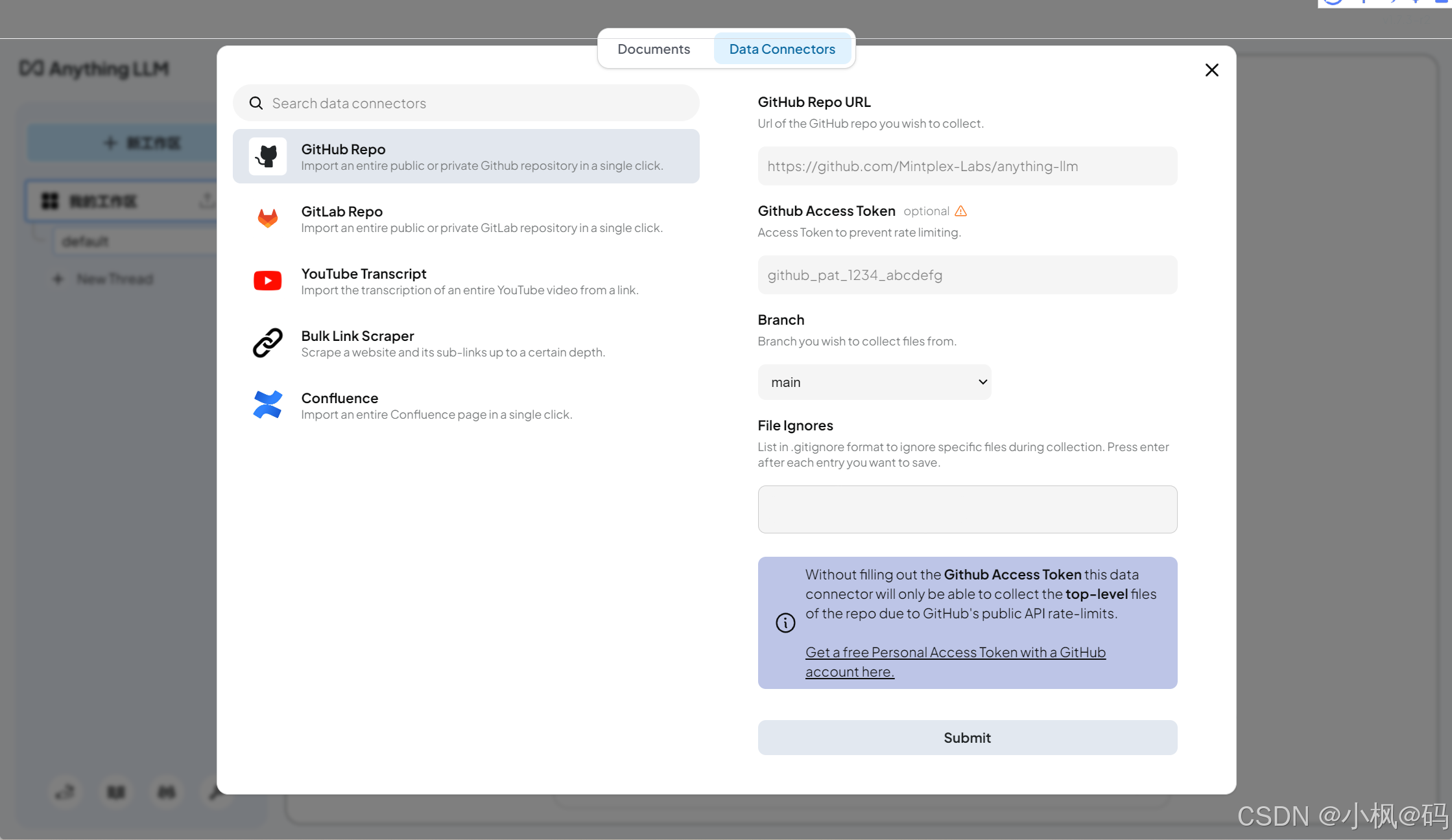
Data Connectors
Data Connectors 功能支持从 GitHub、GitLab 仓库或网站爬取数据。用户只需输入仓库地址和 Token,即可导入指定目录或网页内容。
上传示例
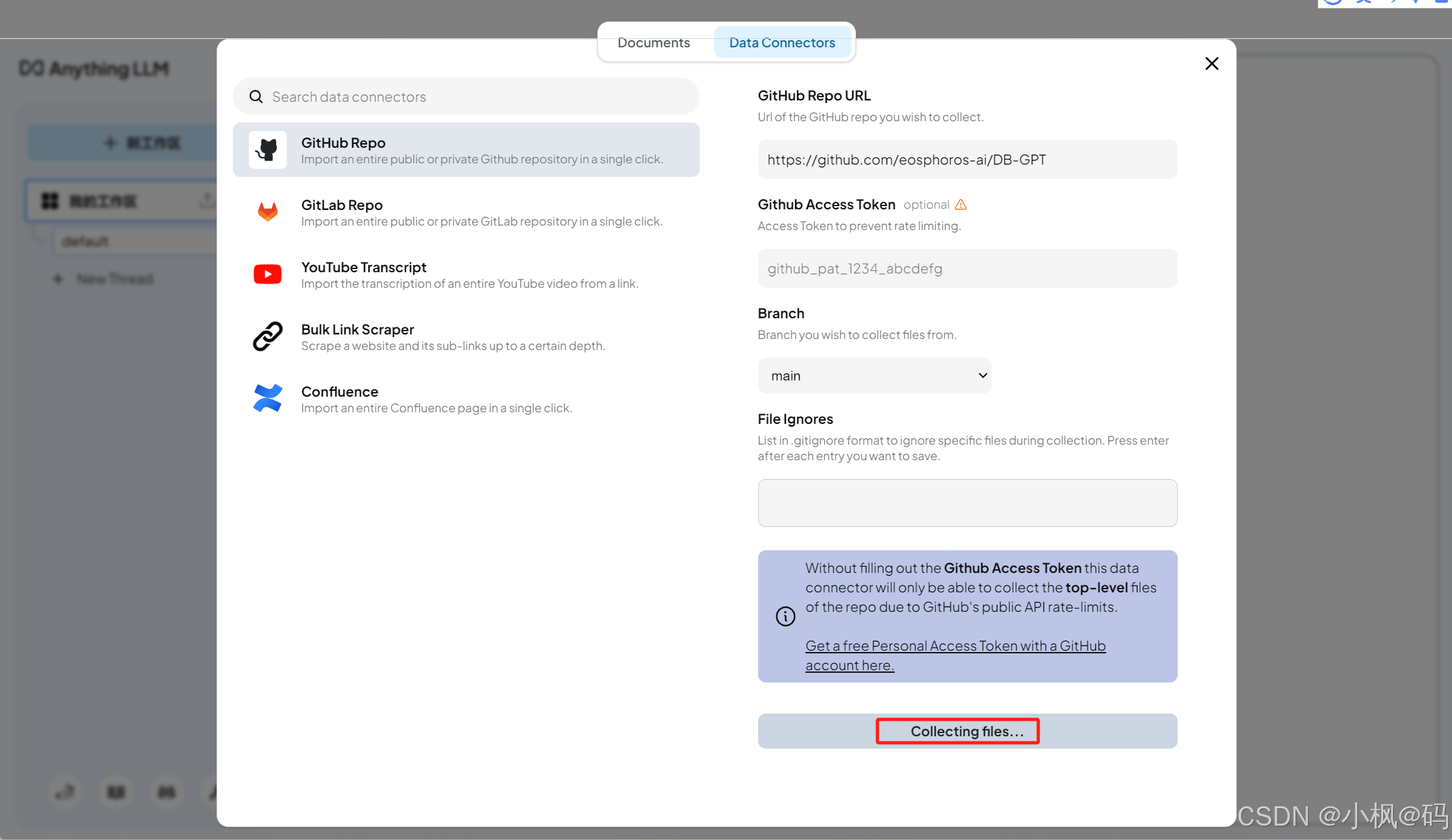
以下是一个从 GitHub 仓库导入数据的示例:
- 输入仓库地址和 Token。
- 通用 File Ignores 配置导入的目录。
- 点击导入按钮,等待数据加载完成。
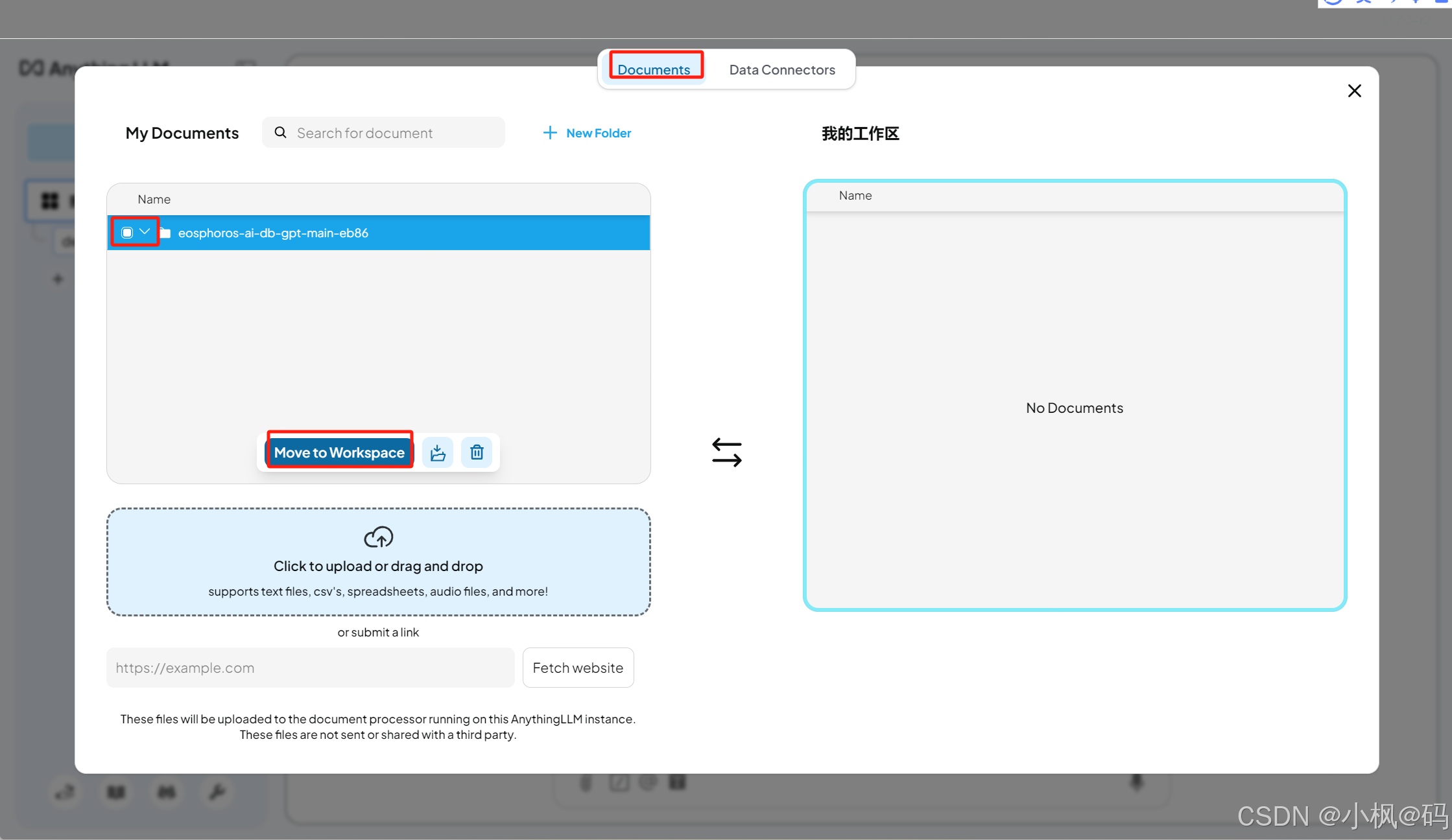
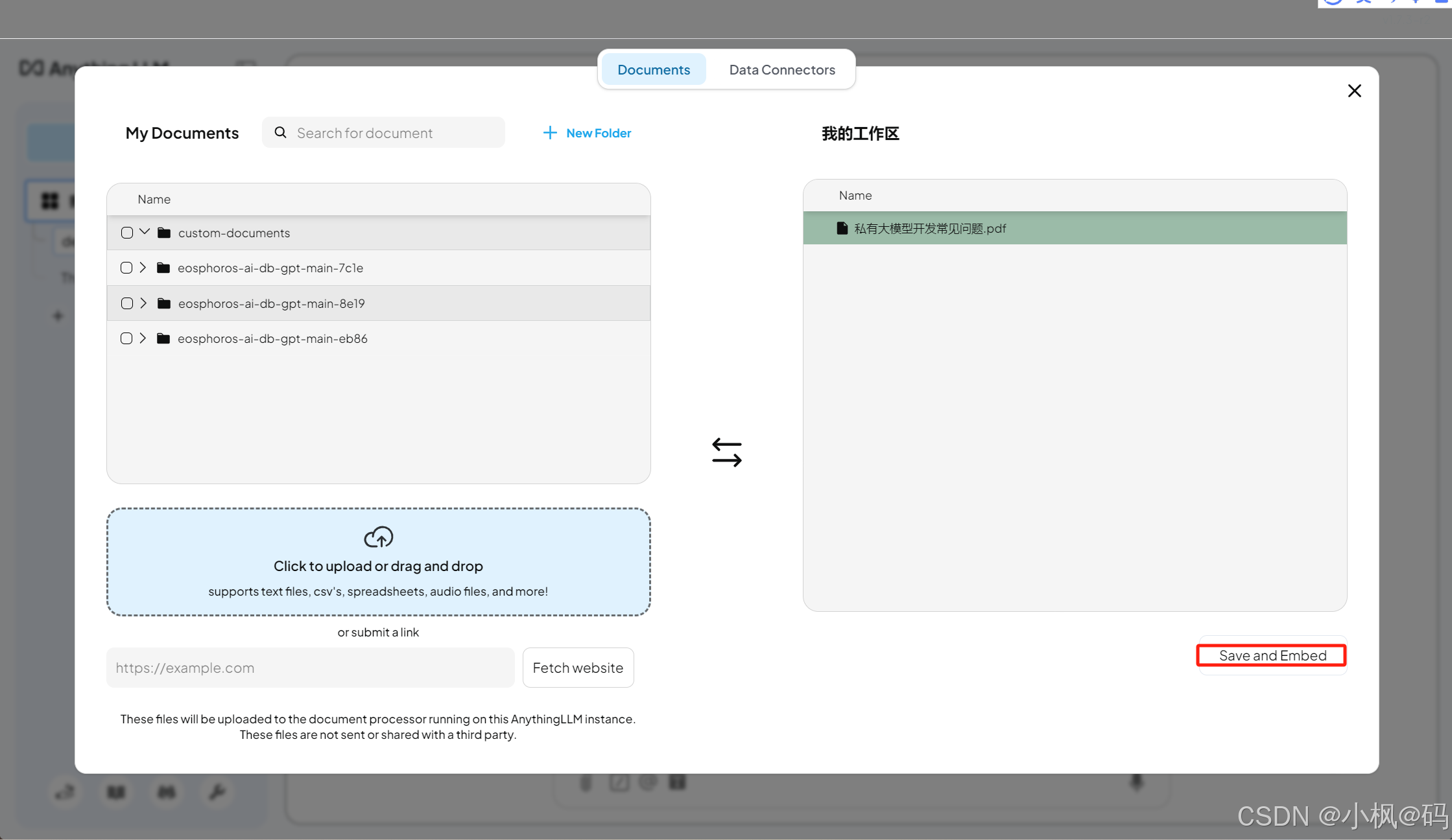
导入完成后,用户可以在 Documents 界面选中文档,并点击 Move to Workspace 将其添加到工作区。
添加到工作区后,点击 Save and Embed,将文档内容转换为向量检索所需的嵌入数据结构。此过程可能会消耗较多 CPU 资源,具体时间取决于文档数量。
查询知识库
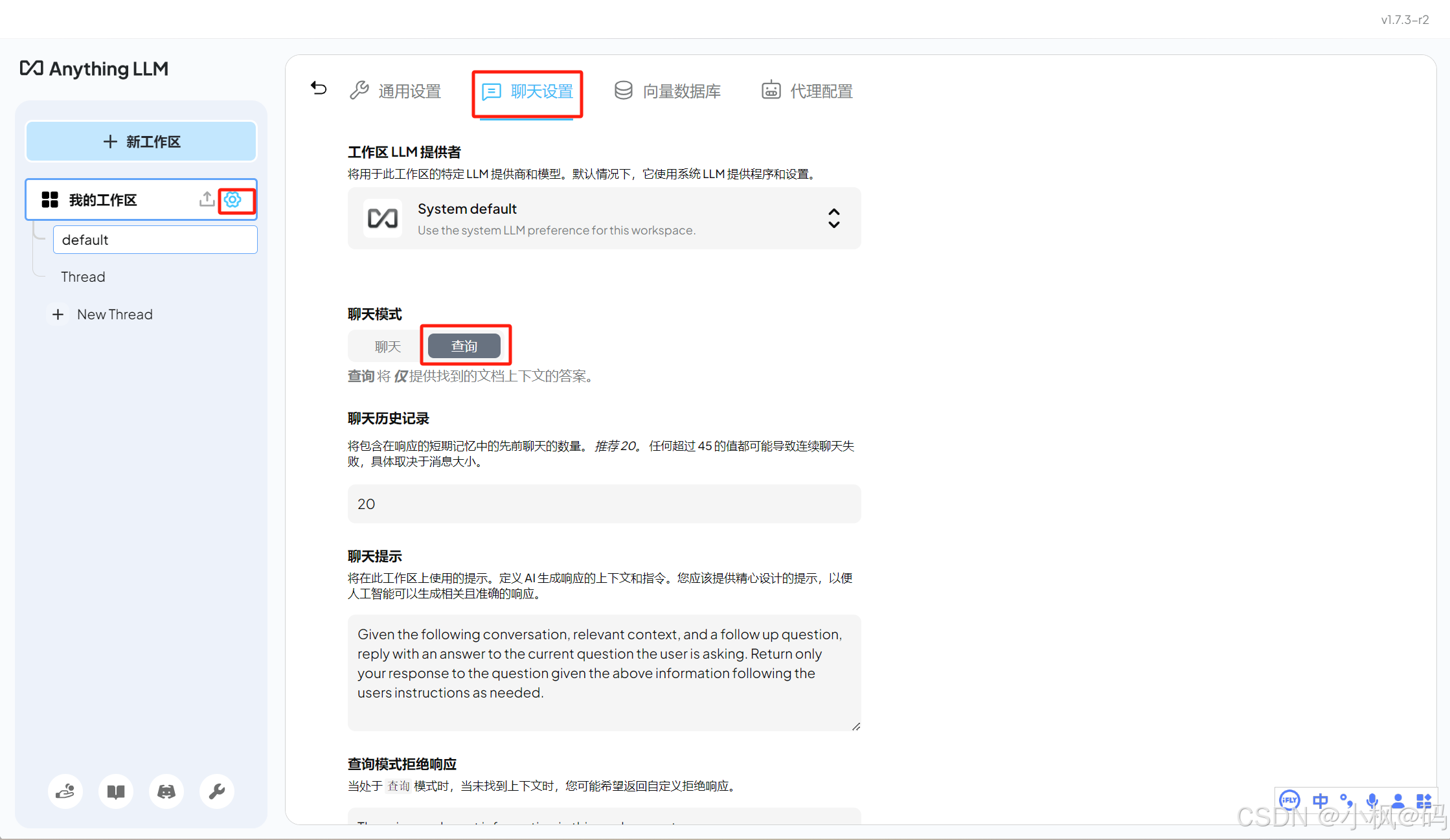
将文档添加到工作区后,用户可以通过设置聊天模式调整大模型的回复方式:
- 聊天模式:结合 LLM 的通用知识和上传文档的上下文生成答案。
- 查询模式:仅基于上传文档的上下文生成答案。
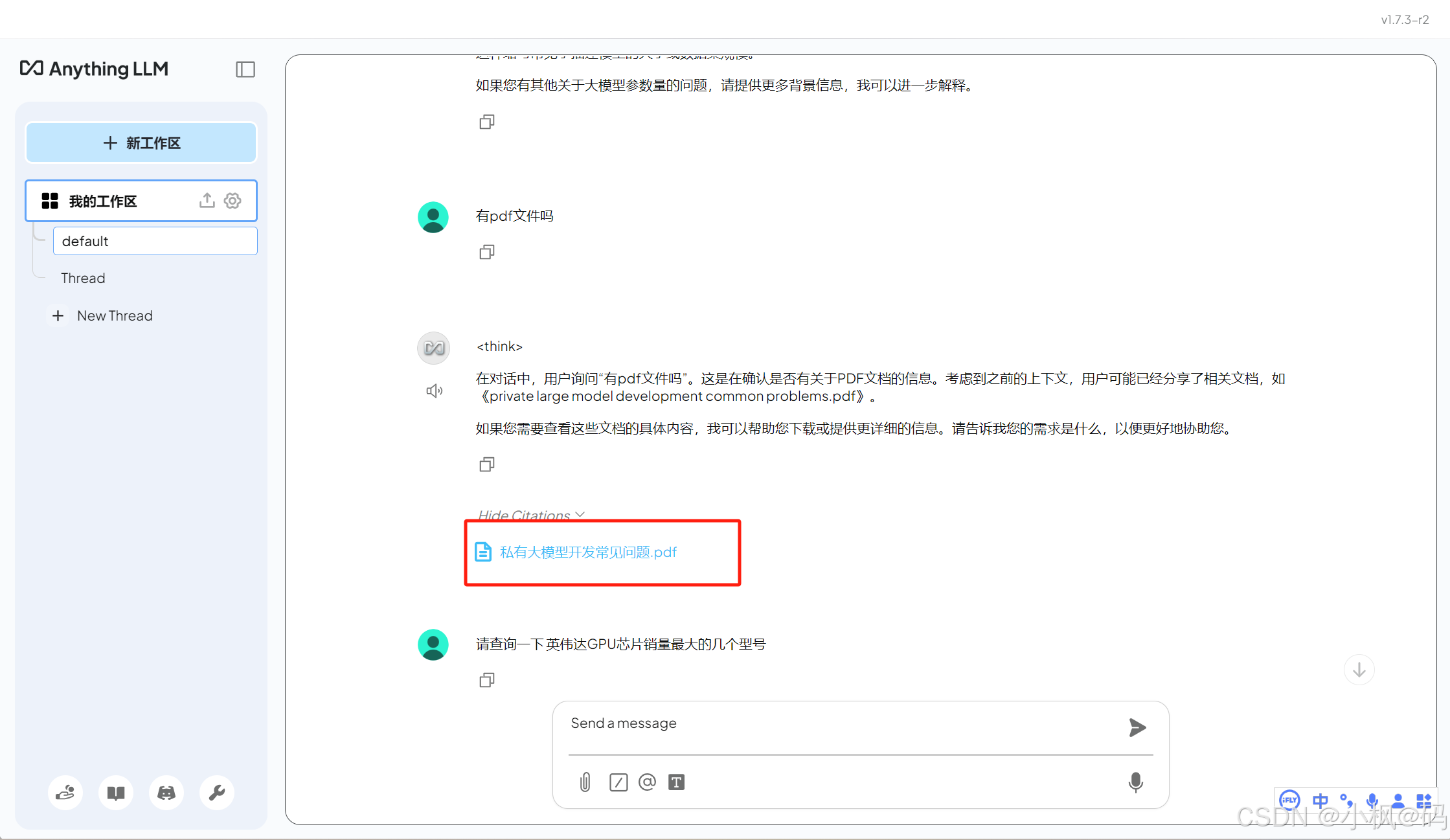
在聊天窗口中,用户可以直接提问。大模型会基于文档内容生成答案,并标注答案来源。
使用 Agent 能力
AnythingLLM 支持 AI 代理功能,用户可以通过 Agent 完成特定任务。除了官方提供的默认 Agent(如 Scrape websites),还支持通过社区添加自定义 Agent
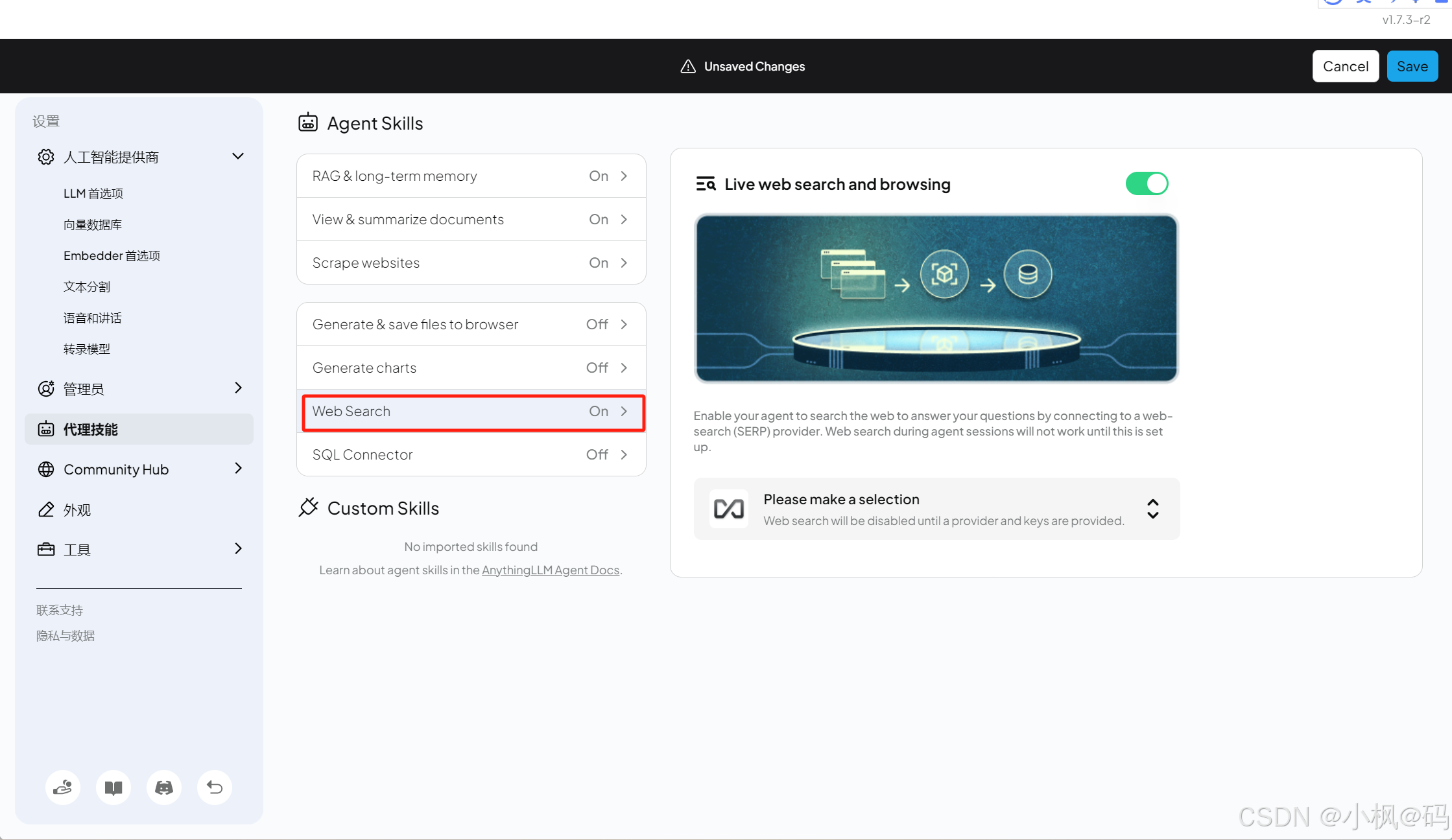
配置 Agent
在设置页面的 代理技能 中,用户可以管理 Agent。默认开启的 Agent 无法关闭,其他 Agent 需要手动启用。
使用示例
以下是一个使用 Scrape websites Agent 的示例:
- 在聊天界面输入
@agent+ 提示词,启动 Agent 会话。
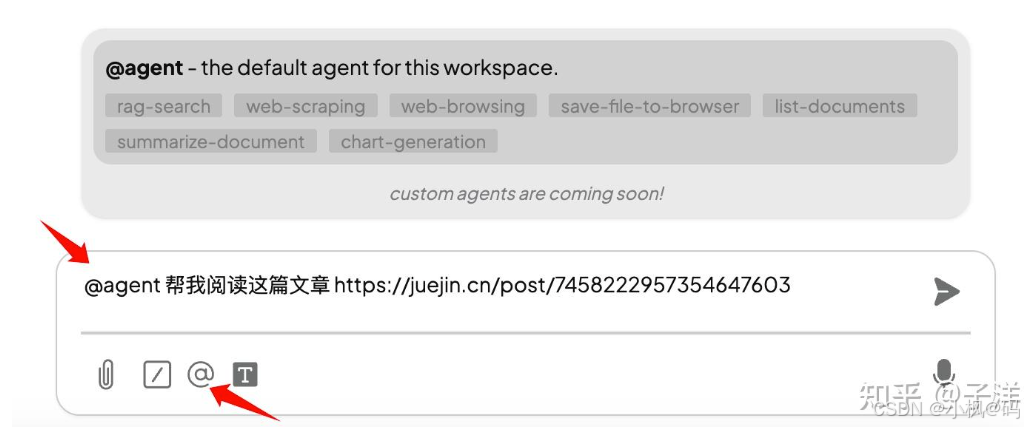
- Agent 会通过 Web Scraping 工具爬取指定页面并返回结果。
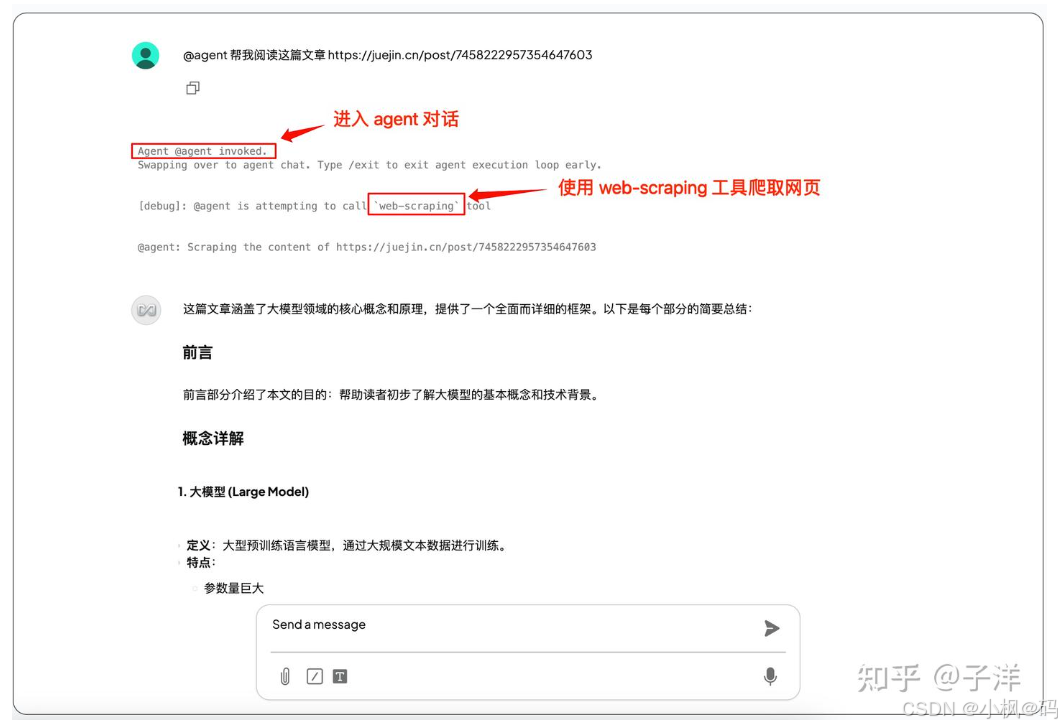
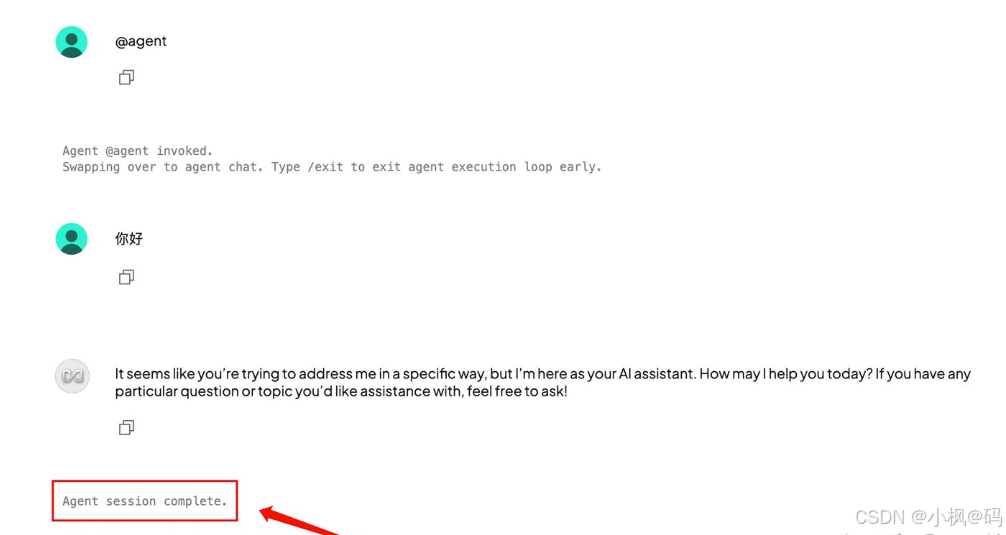
注意: 启动 Agent 会话后,无需每次输入@agent。退出 Agent 会话可通过切换聊天页面或输入/exit命令。
当会话提示 Agent session complete 时,表示已退出 Agent 会话。
结语
通过 AnythingLLM 和 Ollama 的结合,我们成功搭建了一个具备私有知识库能力的 AI 应用。私有知识库不仅可以让 AI 回答通用问题,还能基于私有文档(如企业内部资料、图书等)生成更精准的答案。
注意: 随着知识库中文档数量的增加,回答的准确性可能会受到影响。建议将文档分散到多个工作区,以提高检索效率。
个人知识库+本地大模型的优点如下:
第一、隐私性很好,不用担心自己的资料外泄、离线可用。
第二、在工作和学习过程中对自己整理的文档,能快速找到,并自动关联。
第三、在代码开发上,能参考你的开发习惯,快速生成代码。

















 2327
2327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









