







周博磊 第2章 马尔科夫决策过程
MDP
- Markov Process 马尔科夫过程
- Markov Reward Process 马尔科夫奖励过程
- Markov Decision Proces 马尔科夫决策过程
MDP性质
The furture is independent of the past given the present.
未来的状态只与当前的状态相关
Markov Prcess / Markov Chain
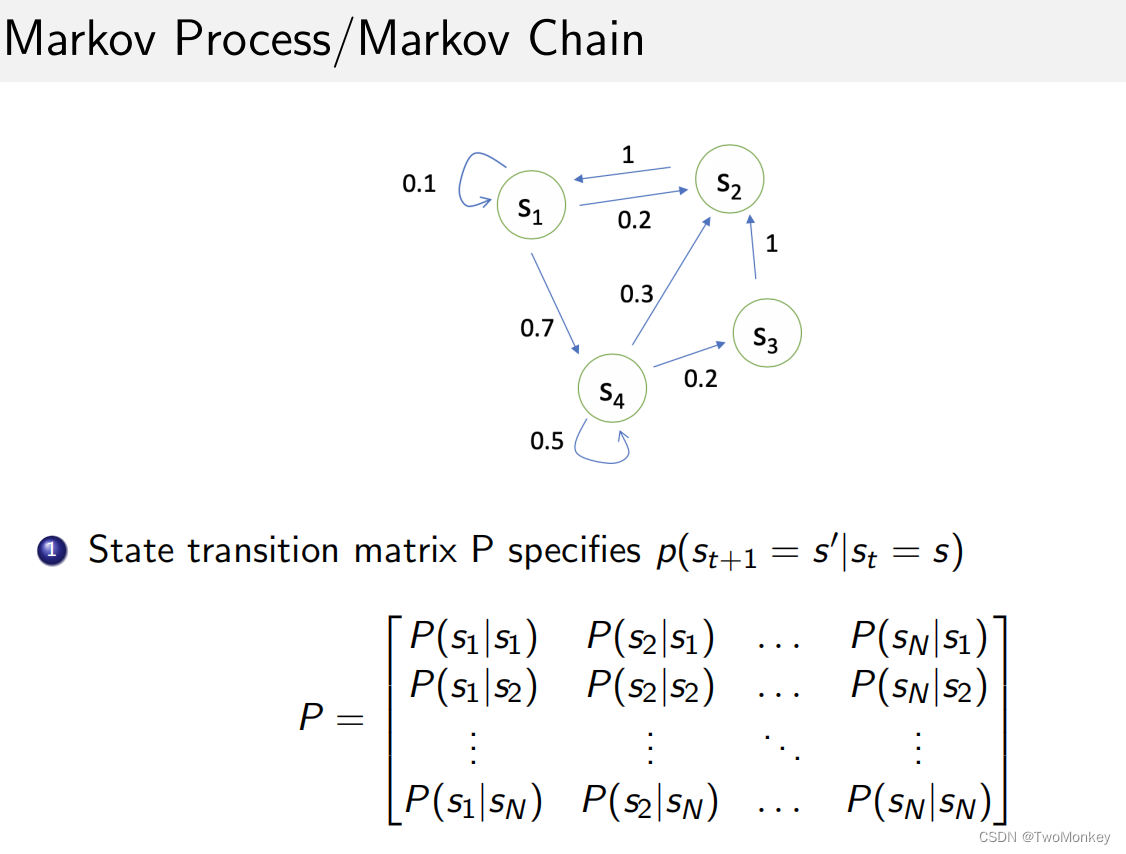
Markov Reward Process
- S 状态
- P 动态转移矩阵
- R 奖励函数 R ( s t = s ) = E [ r t ∣ S t = s ] R(s_{t}=s) = \mathbb{E}[r_{t}|S_{t}=s] R(st=s)=E[rt∣St=s]
- γ \gamma γ 折扣因子
Return && Vaule Function
- Horizon:每个Episode的最大步长
- Return: Horizon的折扣奖励
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + γ T − t − 1 R T G_{t} = R_{t+1} + \gamma R_{t+2} + \gamma^{2} R_{t+3} + ... + \gamma ^{T-t-1} R_{T} Gt=Rt+1+γRt+2+γ2Rt+3+...+γT−t−1RT -
V
t
(
s
)
V_{t}(s)
Vt(s) : Return的期望
V t = E [ G t ∣ s t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + γ T − t − 1 R T ∣ s t = s ] V_{t} = \mathbb{E}[G_{t} | s_{t} = s] \\ = \mathbb{E}[R_{t+1} + \gamma R_{t+2} + \gamma ^{2} R_{t+3} + ... + \gamma^{T-t-1} R_{T} | s_{t} = s] Vt=E[Gt∣st=s]=E[Rt+1+γRt+2+γ2Rt+3+...+γT−t−1RT∣st=s]
折扣因子 γ \gamma γ
- 避免环状的马尔科夫过程
- 未来具有不确定性
- 更加关注即时的奖励
贝尔曼方程
贝尔曼等式描述了状态间的迭代关系
V
(
s
)
=
R
(
s
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
)
V
(
s
′
)
V(s) = R(s) + \gamma \sum_{s^{'} \in S} P(s^{'}|s) V(s^{'})
V(s)=R(s)+γs′∈S∑P(s′∣s)V(s′)
迭代的方式计算MRP
-
Dynamic Programming

-
Monte-Carto evalutation

-
Temporal-Difference Learning
MDP
马尔科夫决策过程相比与奖励过程,加入了动作。也就是说,未来的状态由当前状态和动作共同决定的。
Markov 链/ MRP: 像随波漂流的小船
Markov 决策过程:可以采取导航行为的小船

- S 状态
- A 动作
- P 动态转移矩阵 P ( s t + 1 = s ′ ∣ s t = s , a t = a ) P(s_{t+1} = s^{'}|s_{t} = s, a_{t} = a) P(st+1=s′∣st=s,at=a)
- R 奖励函数 R ( s t = s ) = E [ r t ∣ s t = s , a t = a ] R(s_{t}=s) = \mathbb{E}[r_{t}|s_{t}=s, a_{t}=a] R(st=s)=E[rt∣st=s,at=a]
- γ \gamma γ 折扣因子
Policy 策略
Policy 是指在某一状态执行某一动作的概率
π
=
P
(
a
t
=
a
∣
s
=
s
t
)
\pi = P(a_{t} = a|s=s_{t})
π=P(at=a∣s=st)
动态转移方程和奖励由当前状态与动作共同决定
P
π
=
∑
a
∈
A
π
(
a
∣
s
)
P
(
s
′
∣
s
,
a
)
P^{\pi} = \sum_{a\in A} \pi(a|s) P(s'|s, a)
Pπ=a∈A∑π(a∣s)P(s′∣s,a)
R
π
=
∑
a
∈
A
π
(
a
∣
s
)
R
(
s
,
a
)
R^{\pi} = \sum_{a\in A} \pi(a|s) R(s, a)
Rπ=a∈A∑π(a∣s)R(s,a)
Value Function 价值函数
-
v
π
(
s
)
v^{\pi}(s)
vπ(s) 在s状态下,基于策略
π
\pi
π 期望的回报
V π = E [ G t ∣ s t = s ] V^{\pi} = \mathbb{E}[G_{t}|s_{t}=s] Vπ=E[Gt∣st=s] -
q
π
(
s
,
a
)
q^{\pi}(s,a)
qπ(s,a) 在s状态下,采取行动,基于策略
π
\pi
π 期望的回报
q π ( s , a ) = E [ G t ∣ s t = s , a t = a ] q^{\pi}(s, a) = \mathbb{E}[G_{t}|s_{t} = s, a_{t} = a] qπ(s,a)=E[Gt∣st=s,at=a] - 两者之间的关系
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v^{\pi}(s) = \sum_{a\in A} \pi(a|s)q^{\pi}(s,a) vπ(s)=a∈A∑π(a∣s)qπ(s,a)
贝尔曼期望方程
v
π
(
s
)
=
E
π
[
R
t
+
1
+
γ
v
π
(
s
t
+
1
)
∣
s
t
=
s
]
v^{\pi}(s) = \mathbb{E}_{\pi}[R_{t+1} + \gamma v^{\pi}(s_{t+1})|s_{t} = s]
vπ(s)=Eπ[Rt+1+γvπ(st+1)∣st=s]
q
π
(
s
,
a
)
=
E
π
[
R
t
+
1
+
γ
q
π
(
s
t
+
1
,
A
t
+
1
)
∣
s
t
=
s
,
A
t
=
a
]
q^{\pi}(s, a) = \mathbb{E}_{\pi}[R_{t+1} + \gamma q^{\pi}(s_{t+1}, A_{t+1}) | s_{t} = s, A_{t} = a]
qπ(s,a)=Eπ[Rt+1+γqπ(st+1,At+1)∣st=s,At=a]
两者之间的关系
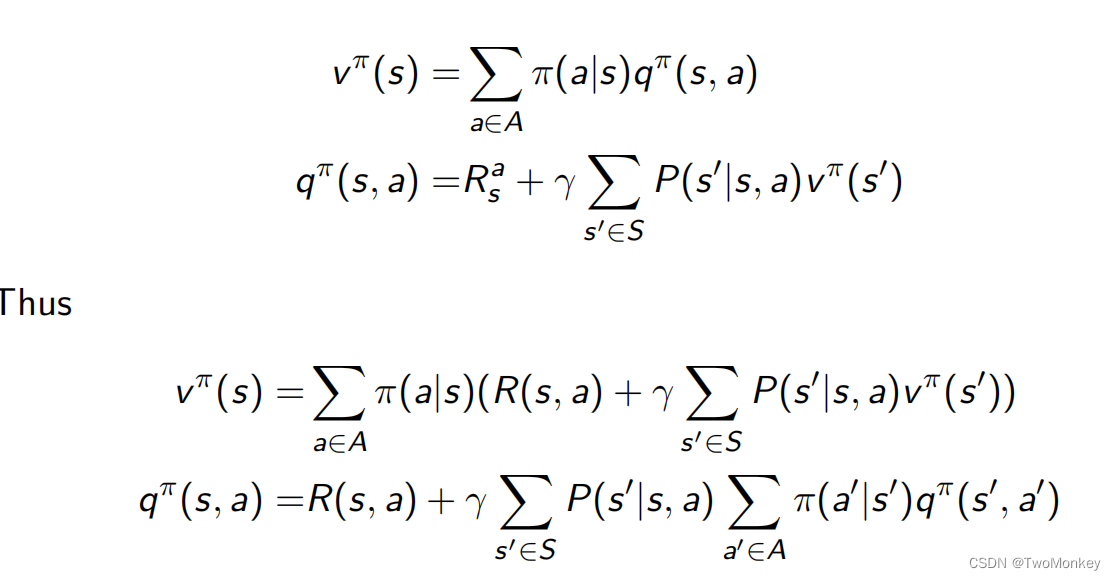
Policy Evalution
已知策略
π
\pi
π MDP, 计算价值函数
v
π
(
s
)
v^{\pi}(s)
vπ(s)
可以用动态规划来做:
v
t
+
1
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
V
t
(
s
′
)
)
v_{t+1}(s) = \sum_{a\in A} \pi(a|s) (R(s,a) + \gamma\sum_{s'\in S} P(s^{'}|s, a)V_t(s^{'}))
vt+1(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)Vt(s′))
Control
已知MDP,寻找最优价值函数和策略
最优函数可以通过寻找最大化
q
∗
(
s
,
a
)
q^{*}(s, a)
q∗(s,a)
π
∗
(
a
∣
s
)
=
{
1
,
i
f
a
=
a
r
g
m
a
x
a
∈
A
q
∗
(
s
,
a
)
0
,
o
t
h
e
r
w
i
s
e
\pi^{*}(a|s) = \left\{ \begin{array}{lc} 1, & if a = arg max_{a \in A}q^{*}(s, a) \\ 0, & otherwise\\ \end{array} \right.
π∗(a∣s)={1,0,ifa=argmaxa∈Aq∗(s,a)otherwise
演示样例
动画:
https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
代码:
https://github.com/cuhkrlcourse/RLexample/tree/master/MDP
通过策略迭代更新策略

- 步骤一:基于策略
π
\pi
π计算价值函数
q π i ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π i ( s ′ ) q^{\pi_{i}}(s, a) = R(s, a) + \gamma \sum_{s^{'}\in S} P(s^{'} | s, a)v^{\pi_{i}}(s') qπi(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)vπi(s′) - 步骤二:依据价值函数更新策略
π i + 1 ( s ) = arg max a q π i ( s , a ) \pi_{i+1}(s) = \argmax_{a} q^{\pi_{i}(s, a)} πi+1(s)=aargmaxqπi(s,a)
值迭代

贝尔曼最优方程
v
∗
=
max
a
q
∗
(
s
,
a
)
q
∗
(
s
,
a
)
=
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
v
(
s
′
)
v^{*} = \max_{a} q^{*}(s,a) \\ q^{*}(s, a) = R(s, a) + \gamma \sum_{s^{'} \in S}P(s^{'}|s, a)v(s^{'})
v∗=amaxq∗(s,a)q∗(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)v(s′)
=>
v
∗
=
max
a
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
v
(
s
′
)
q
∗
(
s
,
a
)
=
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
max
a
′
q
∗
(
s
′
,
a
′
)
v^{*} = \max_{a}R(s,a) + \gamma \sum_{s^{'} \in S}P(s^{'}|s, a)v(s^{'}) \\ q^{*}(s, a) = R(s, a) + \gamma \sum_{s^{'} \in S}P(s^{'}|s, a)\max_{a^{'}}q^{*}(s^{'}, a^{'})
v∗=amaxR(s,a)+γs′∈S∑P(s′∣s,a)v(s′)q∗(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)a′maxq∗(s′,a′)
策略迭代 VS 价值迭代
- 策略迭代:【策略估计 + 策略更新】作为一个整体过程,需要迭代多次
- 价值阶段:找出最优价值函数 + 策略提取 寻找最优策略是个迭代过程,策略提取取最大价值的动作即是策略。















 3290
3290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









