







SemEval (Semantic Evaluation) 是评估机器语义分析的一个系列,或者说是一系列研讨会。该研讨会每年都会举办一次,目前依旧存在。
Why SemEval?
在具体介绍 SemEval 之前,我们先弄清楚为什么要举办这样的一个研讨会。我们知道 NLP 是一个很有难度的领域,这一领域的终极目标即可以让机器像人一样理解、处理语言,而想做到这一点需要让机器弄明白语言的意思(meaning),也即 Semantics 。那么每年技术都有进步,我们距离最终的目标还有多远呢?为了了解当前机器的水平,合理、有效的评估就很重要了,这也是 SemEval 要做的事。
Introduce of SemEval
现在我们知道 SemEval 研讨会是为了评估语义,那么如何有效的评估呢?SemEval 是如何做的呢?其实既然是评估机器的能力(和人类的差距),那么比较自然的想法就是让机器和人做同一件事,然后基于此评估。有了大致思路,下面给出 SemEval 评估的流程:
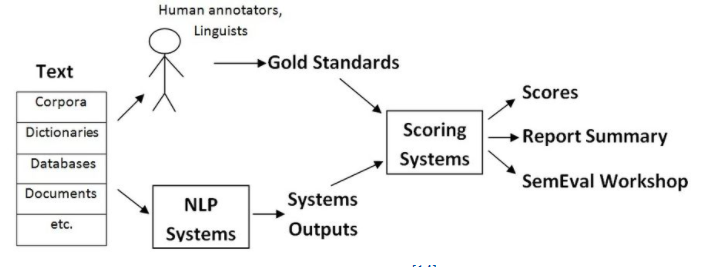
-
其实最开始一步在图中没有体现,因为我们知道语义这个词还是很宽泛的,毕竟人类在不同情景下理解语义的方式也不同(或者说侧重点不同,比如在看弹幕时我们优先想“梗”,而在女朋友生气时我们优先思考女友语言的“反义”,等等),可以说在很长一段时间里机器都没办法统一的处理所有情况(理解语义)。
基于上述,可知要想评估需要先给定任务,所以 SemEval 第一步工作即设置任务。
-
构造人工标注的数据集。
-
机器在相应数据集完成任务。机器处理的方案由许多人员或团队提出。
-
最后根据各个方案得到的结果评分以及估计 SOTA (state of the art)。
补充
SemEval 每年的任务和方案其实各自都可以看作是一个比赛,由报名参赛的人员或团队提供。(任务是近年才采用这种形式的)。
















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











