






Keras使用不同损失函数的方式:
- model.compile(loss='损失函数名', optimizer='sgd')
- from keras import losses model.compile(loss=losses.损失函数名, optimizer='sgd')
mean_absolute_percentage_error(MAPE)
- 定义:

def mean_absolute_percentage_error(y_true, y_pred):
diff = K.abs((y_true - y_pred) / K.clip(K.abs(y_true),
K.epsilon(),
None))
return 100. * K.mean(diff, axis=-1)
2.意义: MAPE不仅仅考虑预测值与真实值的误差,还考虑了误差与真实值之间的比例,在某些场景下,比如房价从0.5w到5w之间,0.5预测成1.0与5.0预测成4.5的差距是非常大的,在一些竞赛当中,MAPE也是常用的目标函数之一。在统计领域是一个预测准确性的衡量指标。
mean_squared_logarithmic_error(MSLE)
- 定义:

def mean_squared_logarithmic_error(y_true, y_pred):
first_log = K.log(K.clip(y_pred, K.epsilon(), None) + 1.)
second_log = K.log(K.clip(y_true, K.epsilon(), None) + 1.)
return K.mean(K.square(first_log - second_log), axis=-1)
squared_hinge
- 定义:

def hinge(y_true, y_pred):
return K.mean(K.maximum(1. - y_true * y_pred, 0.), axis=-1)
hinge
- 定义:

def hinge(y_true, y_pred):
return K.mean(K.maximum(1. - y_true * y_pred, 0.), axis=-1)
categorical_hinge
- 定义:def categorical_hinge(y_true, y_pred):
pos = K.sum(y_true * y_pred, axis=-1)
neg = K.max((1. - y_true) * y_pred, axis=-1)
return K.maximum(0., neg - pos + 1.)
logcosh
定义:def logcosh(y_true, y_pred):
"""Logarithm of the hyperbolic cosine of the prediction error.
`log(cosh(x))` is approximately equal to `(x ** 2) / 2` for small `x` and
to `abs(x) - log(2)` for large `x`. This means that 'logcosh' works mostly
like the mean squared error, but will not be so strongly affected by the
occasional wildly incorrect prediction.
# Arguments
y_true: tensor of true targets.
y_pred: tensor of predicted targets.
# Returns
Tensor with one scalar loss entry per sample.
"""
def _logcosh(x):
return x + K.softplus(-2. * x) - K.log(2.)
return K.mean(_logcosh(y_pred - y_true), axis=-1)
categorical_crossentropy(CE 交叉熵损失函数)
- 定义:

M代表类别总数,N代表样本的个数 ,yij是实际结果,y^是预测结果
def categorical_crossentropy(y_true, y_pred):
return K.categorical_crossentropy(y_true, y_pred)
2.注意:使用此损失函数时,标签要是01格式(One-hot 编码形式),即除了目标位置,其余都是0,eg.(6分类问题):000100,100000等
可以使用 from keras.utils.np_utils import to_categorical
Train_labels = to_categorical(Train_labels , num_classes=None)
将训练标签转换成01格式
3.使用场景:在只有一个结果是正确的分类问题中使用分类交叉熵(多分类问题首选),同时将分类交叉熵与激活函数 SoftMax一起使用。
binary_crossentropy(BCE亦称作对数损失,logloss)
- 定义:def binary_crossentropy(y_true, y_pred):
return K.mean(K.binary_crossentropy(y_true, y_pred), axis=-1)
2.使用场景:CE用于多分类, BCE适用于二分类”
sparse_categorical_crossentropy
- 定义:def sparse_categorical_crossentropy(y_true, y_pred):
return K.sparse_categorical_crossentropy(y_true, y_pred)
2.标签要是01格式(One-hot 编码形式),但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你 可 能需要在标签数据上增加一个维度:np.expand_dims(y,-1)
kullback_leibler_divergence(KL距离,也叫做相对熵)
- 定义:def kullback_leibler_divergence(y_true, y_pred):
y_true = K.clip(y_true, K.epsilon(), 1)
y_pred = K.clip(y_pred, K.epsilon(), 1)
return K.sum(y_true * K.log(y_true / y_pred), axis=-1)
2.从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
其物理意义是:在相同事件空间里,概率分布P(x)的事件空间,若用概率分布Q(x)编码时,平均每个基本事件(符号)编码 长度增加了多少比特。我们用D(P||Q)表示KL距离,计算公式如下:
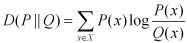
KL距离在信息检索领域,以及统计自然语言方面有重要的运用。比如利用相对熵进行分类或者是利用相对熵来衡量两个随机分 布的差距,当两个随机分布相同时,其相对熵为0.当两个随机分布的差别增加时,器相对熵也增加。
poisson
- 定义:

def poisson(y_true, y_pred):
return K.mean(y_pred - y_true * K.log(y_pred + K.epsilon()), axis=-1)
cosine_proximity(余旋相似性)
- 定义:

def cosine_proximity(y_true, y_pred):
y_true = K.l2_normalize(y_true, axis=-1)
y_pred = K.l2_normalize(y_pred, axis=-1)
return -K.sum(y_true * y_pred, axis=-1)
即预测值与真实标签的余弦距离平均值的相反数
余弦相似度计算:

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









