







目录
4. "image-specific" sampling strategy
Faster R-CNN = RPN + Fast R-CNN
1. Region Proposal Network (RPN)
R-CNN
要点
大样本下有监督预训练+小样本微调(现实任务中,带标签的检测数据较少)
1. 多阶段目标检测模型
预训练(transfer learning,用softmax regression去finetune分类网络) + selective search提取候选框 + CNN提取图像特征(AlexNet作为主干网络) + SVM分类 / regression回归调整预测框。
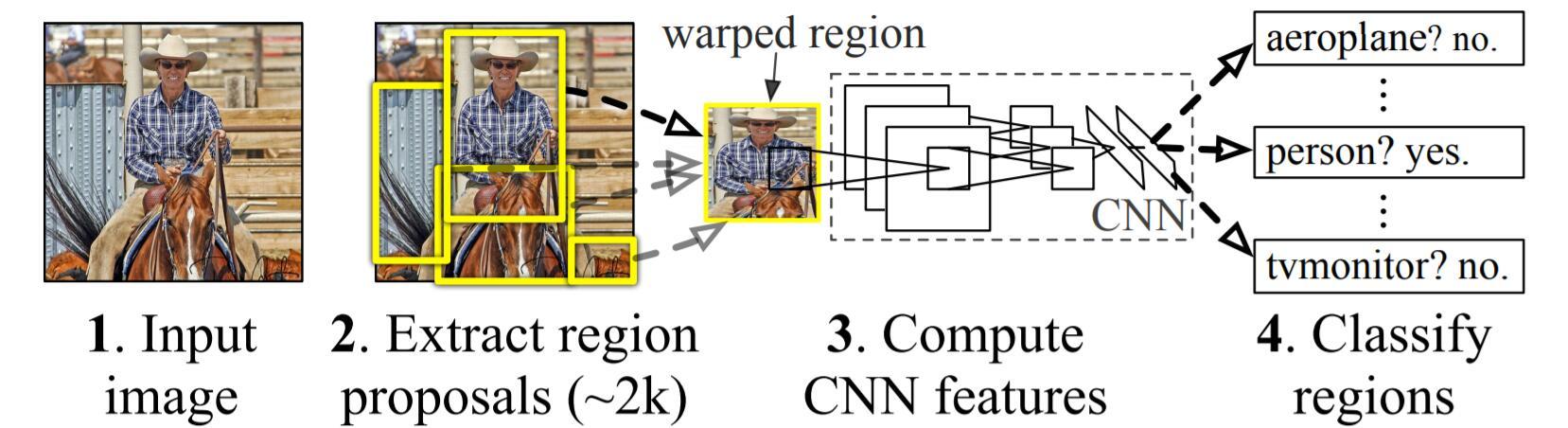
2. 训练流程
前提:将每个候选框分配给与其IOU最大的ground truth(GT)。
1)Pre-training + Finetuning
预训练数据集是ILSVRC2012,只使用 image-level annotations (没有bbox标签)。之后根据任务,将输出层改为N+1:N个类别,1个背景,微调CNN。
候选框中IOU>0.5的为正样本,其余为负样本(由于正负样本不均衡,所以会bias towads 正例)。
2)SVM分类
单独训练SVM,且每个类别都训练一个SVM。
GT为正样本,候选框中IOU值<0.3的为负样本,并使用难例挖掘。
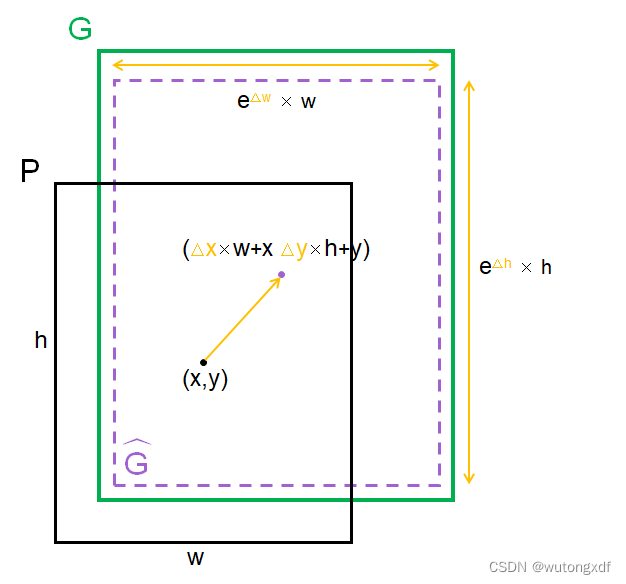
3)预测框回归
候选框中IOU>阈值的为正样本,其余丢弃。
对每个object class 都这么做,从而训练出 class-specific 的 bounding box regression。
缺陷
1. 为使候选框与CNN网络兼容,输入前需要先将其变为固定尺寸;
2. R-CNN 比较耗时:
1)使用 selective search 产生候选框的步骤消耗大量时间;
2)使用CNN逐一分别提取所有候选框的特征,存在大量重复计算;
3)非端到端,各组件需要单独训练,并需要写回内存。
Fast R-CNN
改进(针对R-CNN)
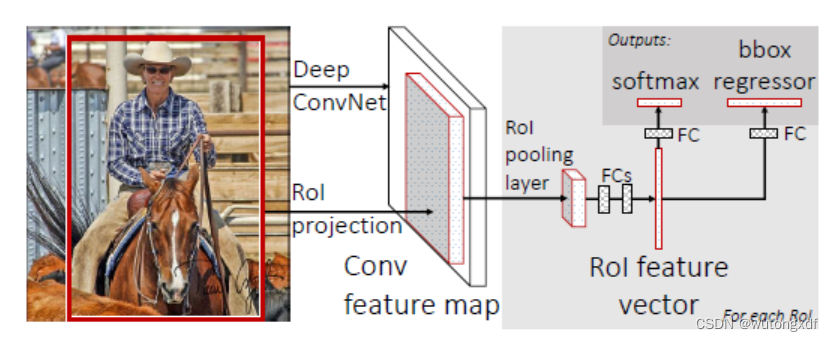
1. 使用 multi-task loss
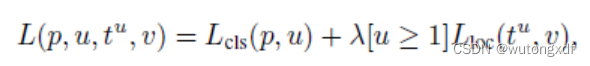
其中,分类损失采用 log loss(对应softmax regression);定位使用 smoothL1 损失,背景类不计入定位损失。
另外,论文中也提到了采用 multi-task training 的优越性。
2. 样本选择
1)正样本:与GT的IOU≥0.5的ROIs,占全部采样ROI的25%;
2)负样本:与GT的IOU∈[0.1,0.5)的ROIs。
3. ROI pooling

先将整张图片输入CNN,产生 feature map。selective search 方法产生的候选框经过 feature map 投影得到相应的ROI后,通过 ROI pooling 层,生成固定长度的特征向量。
4. "image-specific" sampling strategy
Fast R-CNN 可以更新整个网络(对比SPPnet)。
SPPnet 的训练样本(如每次采样R=128个样本)都来自于不同的图像,使得反向传播算法非常低效,无法更新SPP layer之前的网络。
Fast R-CNN采用分层采样策略。同样采集R=128个样本,Fast R-CNN 会先采样N=2张图像,再从每张图像中采集 R/N=64个 ROIs。同一张图像的ROIs可以共享计算和内存,从而能够加快计算。
5. 使用truncated SVD加快检测
缺陷
1. Fast R-CNN 本身并不能生成候选框,仍需使用 selective search 提取ROI,十分耗时。
2. 使用 ROI pooling 时,需要进行两次取整操作,使得 RoI 与所提取的特征之间存在错位(Mask R-CNN 就此进行了改进)。
Faster R-CNN
Faster R-CNN = RPN + Fast R-CNN
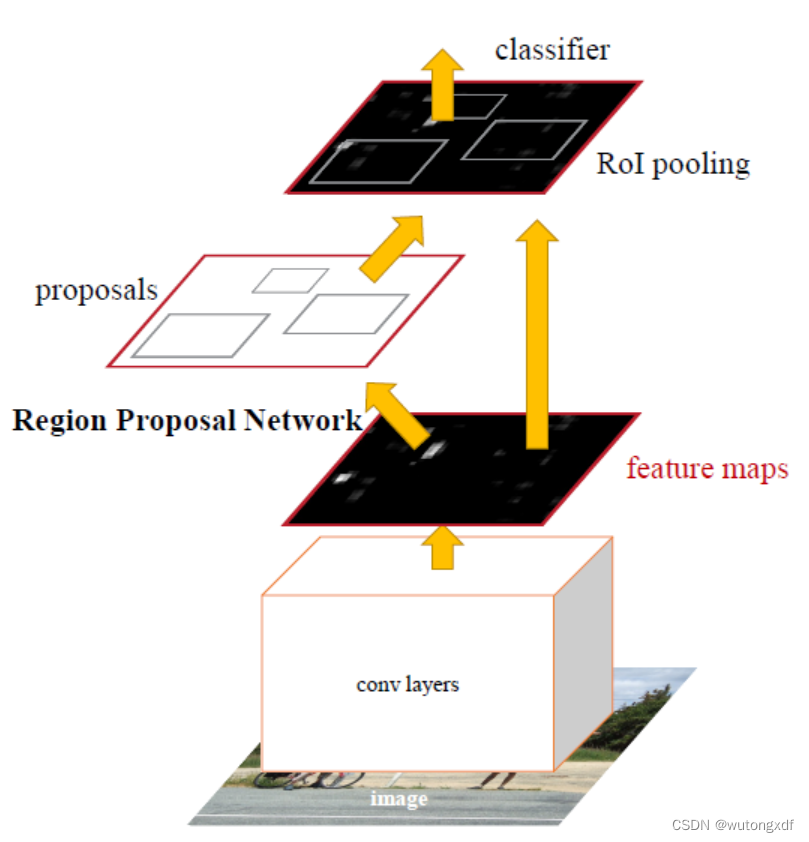
1. Region Proposal Network (RPN)
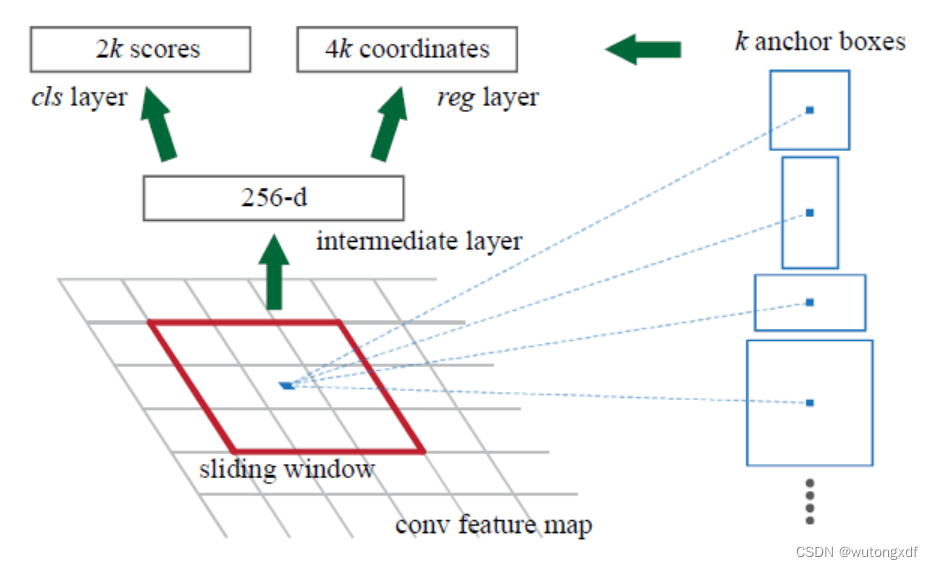
1)RPN为全卷积网络,取代selective search,生成候选框
假设CNN进行了N倍下采样,则feature map 上的一个点(location)可能对应原始输入图片上一个N×N的区域,该区域的中心即为锚点(anchor boxes的中心点)。在feature map上对一个点进行信息抽取时,对应了原图上anchor boxes的特征信息。
2)引入多尺度的 anchor box 机制
设特征图每个位置对应k个anchors,则W×H大小的特征图,共有 WHk 个anchors。每个anchor/proposal输出 4个回归参数,以及2个分类score(只关注是否为目标,不关注具体类别)。
3)损失函数
分类损失采用二分类的 softmax regression (log loss over two classes)。
正例:与GT的IOU最大的anchor/anchors;或者与GT的IOU>0.7的anchor。一个GT可能分配给多个anchor。
负例:与GT的IOU<0.3的anchors。
【注】学习k个回归器,每个回归器对应于一个不同的尺寸和宽高比。
2. RPN 与 Fast R-CNN 共享网络
RPN 与 Fast R-CNN 可以交替训练,共用CNN网络。
Mask R-CNN(实例分割)
要点
1. 引入FPN
通过backbone和FPN产生多个尺度的feature map,随后经过RPN网络产生proposals,再将生成的proposals输入RoIAlign,在对应的特征层(通过公式计算)进行裁剪,得到固定大小的特征。
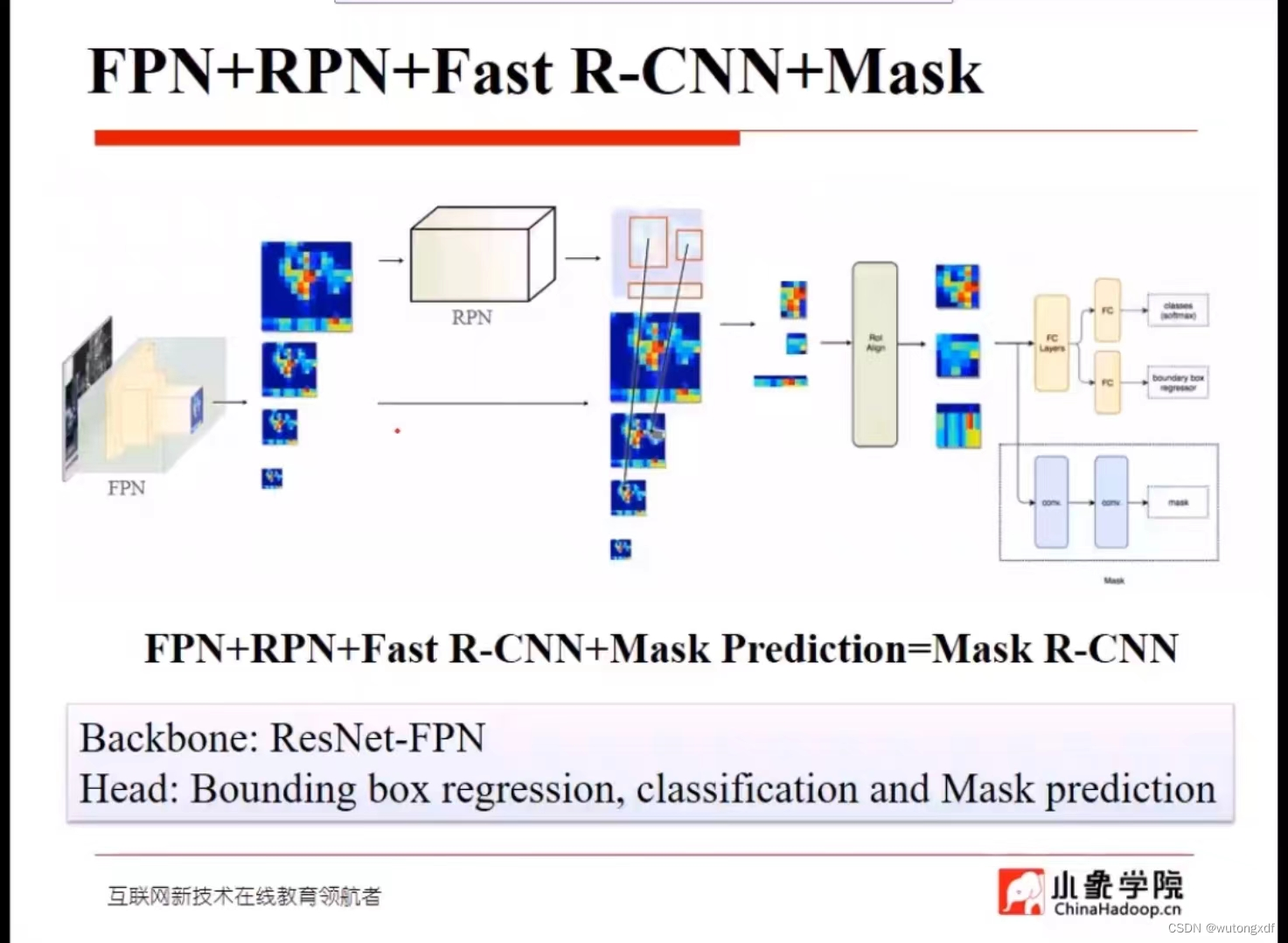
图片来源:Faster rcnn/Mask rcnn/FPN_哔哩哔哩_bilibili
2. RoIAlign
改进 RoIPool 因量化(取整)操作而造成的misalignment。

在每个子区域(图中黑色框格)中采用双线性插值的方法计算四个采样点的值,随后输出四个采样点的最大值或均值作为子区域的值。
【注】Fast R-CNN分支与mask分支feature map尺寸不同,不共用RoIAlign,mask分支需要更细粒度的特征信息。
3. mask branch
1)在Faster R-CNN的基础上,对每一个ROI输出一个用于实例分割的mask蒙版,classification分支与mask分支并行。
2)mask预测与分类预测解耦
mask分支会针对各个类别预测一个蒙版,避免了类间竞争。每个RoI都会有一个Km²维的输出,其中K为类别数,m×m为RoI的像素值。
由专门的分类分支进行类别的预测,mask分支凭此选取RoI所属类别的mask,并对每个像素进行sigmoid激活。mask损失为BCE,只取RoI所属类别的mask与GT的mask进行损失计算。
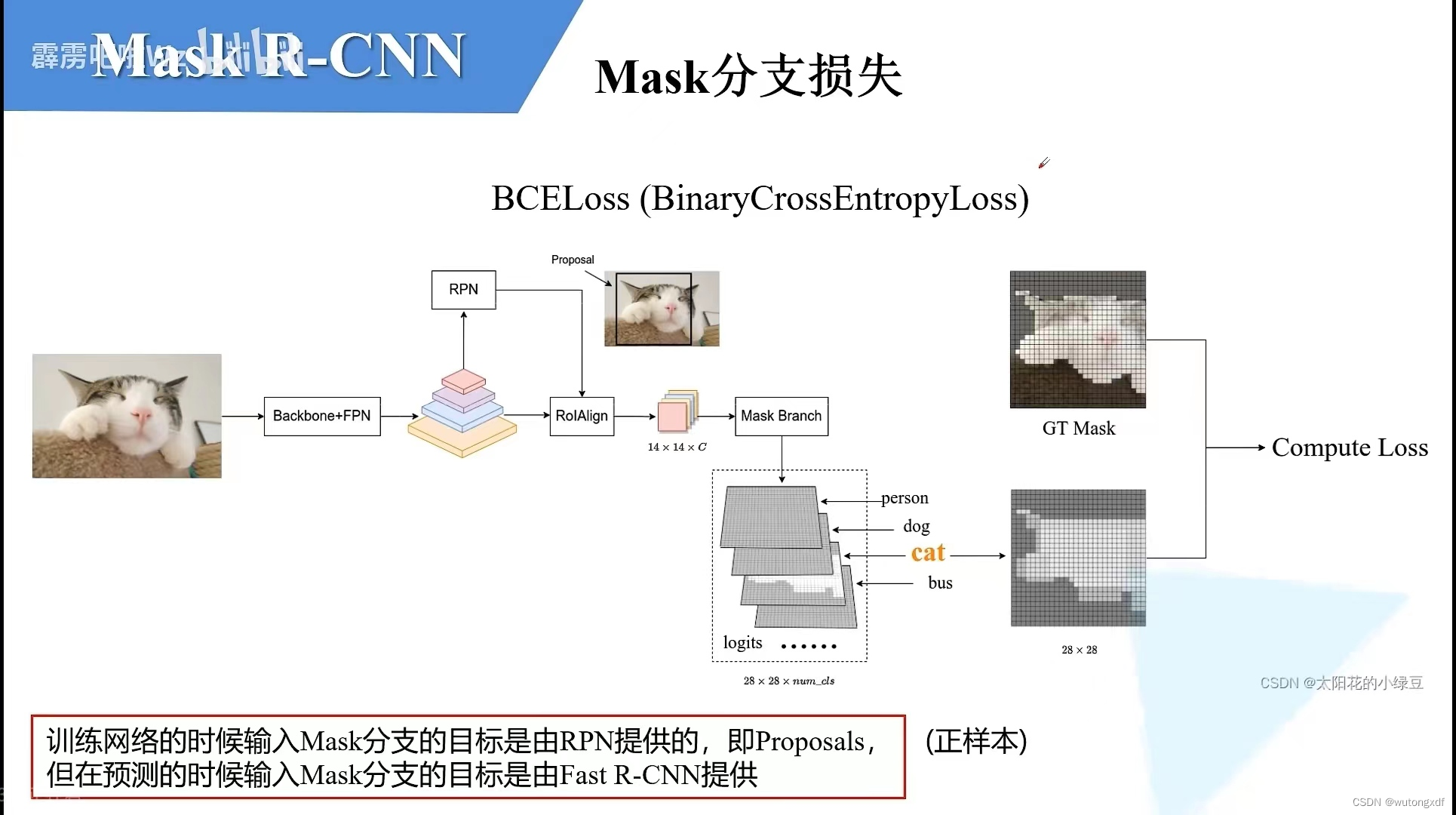
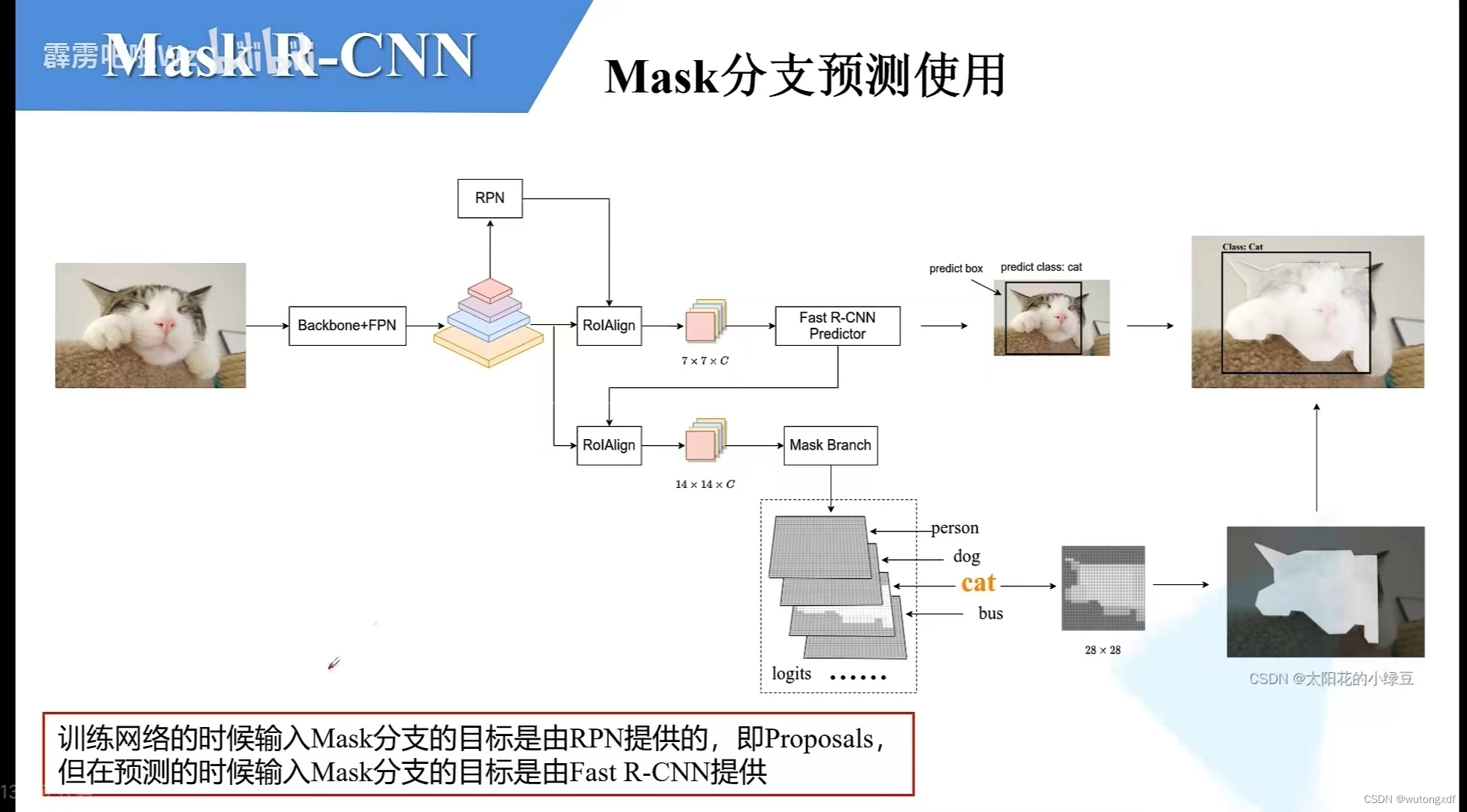
图片来源:Mask R-CNN网络详解_哔哩哔哩_bilibili
【注】训练时输入mask分支的目标由RPN网络提供(即proposals,只选取正样本),此时的训练样本不很准确,但一定包含部分GT,可能可以达到随机裁剪的数据增强的效果;而预测时输入mask分支的目标由Fast R-CNN提供。















 6250
6250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









