







本节介绍通过UI, 命令行, 配置文件, YARN API 管理YARN资源:
- Ambari UI
- ResourceManager UI
- Command line and manual configuration
- YARN API
一、 Ambari UI
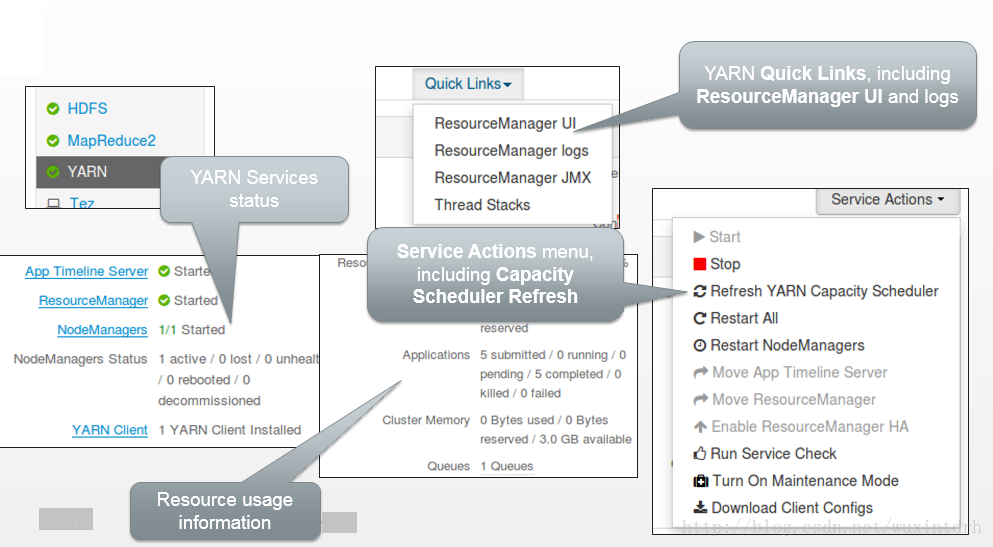
1.1、Ambari UI YARN Management
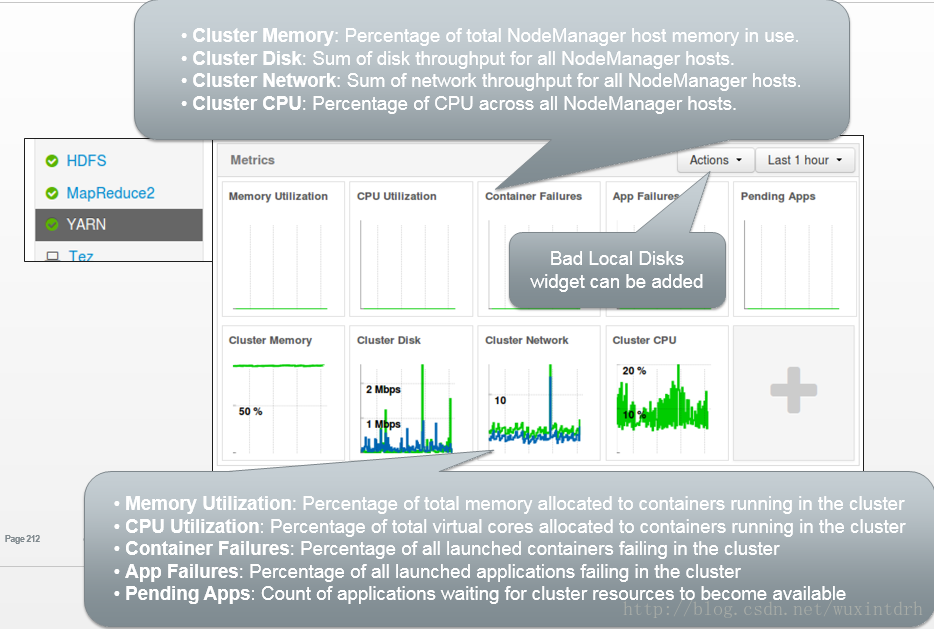
1.2、Ambari UI YARN Resource Monitoring
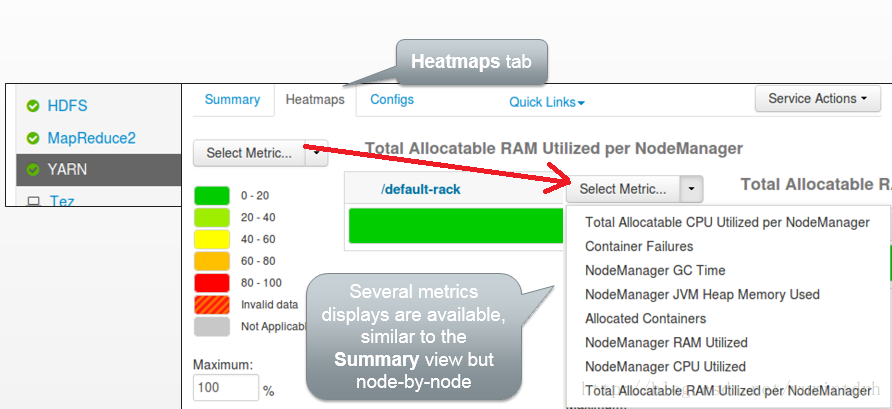
1.3 Ambari UI YARN Heatmaps
1.4
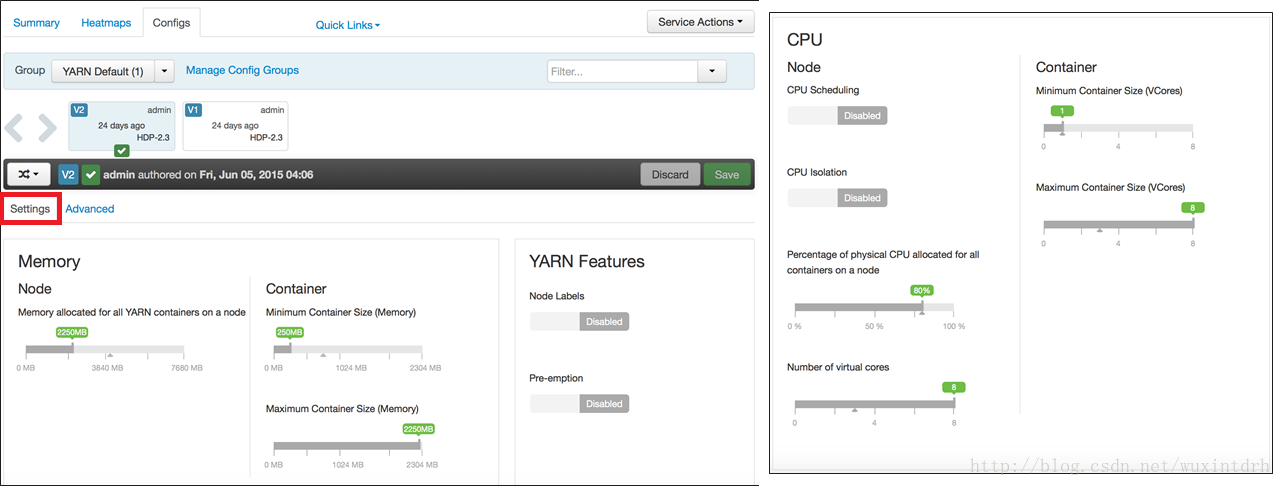
The Configs tab provides the ability to modify the default behavior of YARN and YARN applications. The default Settings sub-tab contains several customizeable settings that can be configured via a GUI. These include:
Memory: Controls the amount of node memory that can be allocated for containers, as well as the minimum and maximum size of those containers.
YARN Features: Enable Node Lables to restrict YARN applications so that they can only run on nodes that have a specified label. Pre-emption allows the specification of higher-priority applications, which can reclaim resources from lower-priority applications in the event of resource contention.
CPU: Enable CPU scheduling, which changes the default scheduler behavior to include both memory *and* CPU (rather than just memory) when making scheduling decisions. Enable CPU Isolation, which allows the isolation of CPU-heavy processes. When applicable (more on that in a later lesson), this section also controls the percentage of physical CPU allocated for containers on a node, the number of virtual cores allocated for containers. The Container settings set the minimum and maximum number of virtual cores (VCores) that can be allocated to any individual container.













 39万+
39万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









