







 本文详细介绍了HDFS(Hadoop分布式文件系统)的基本架构,包括NameNode、DataNode及SecondaryNameNode的角色职责。深入解析了HDFS的读取流程,从客户端发起请求到最终获取数据的具体步骤,同时提供了实现HDFS文件读取的Java代码示例。
本文详细介绍了HDFS(Hadoop分布式文件系统)的基本架构,包括NameNode、DataNode及SecondaryNameNode的角色职责。深入解析了HDFS的读取流程,从客户端发起请求到最终获取数据的具体步骤,同时提供了实现HDFS文件读取的Java代码示例。
1、HDFS架构

如上图:HDFS是master和slave架构, 主要包含NameNode、DataNode, Secondary NameNode三种角色。
- NameNode: 管理HDFS的名称空间和数据块映射信息、配置副本策略和处理客户端请求;
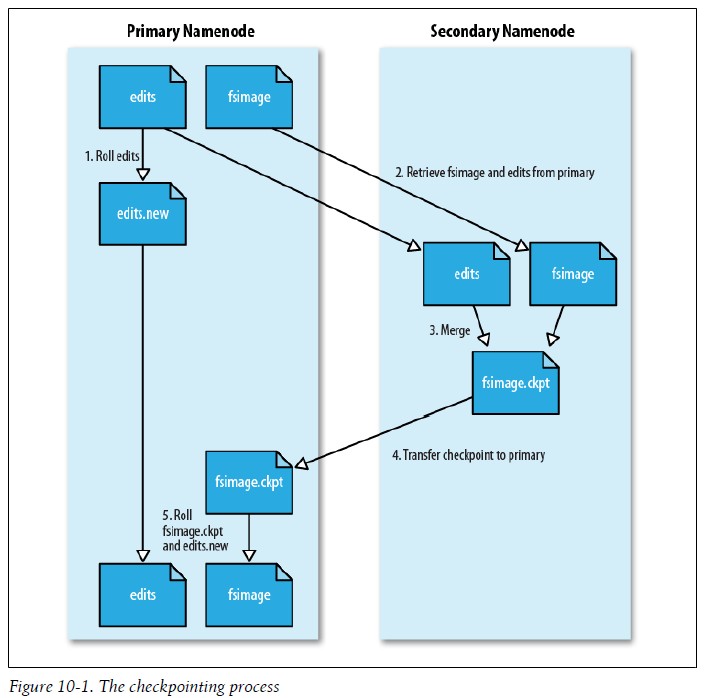
- Secondar NameNode: 辅助NameNode,分担其工作, 定期合并fsimage和fsedits,并推送给NameNode紧急情况下, 可以恢复NameNode(但是只是一定时间内的数据)。
- DataNode: Slave节点, 实际存储数据、执行数据块的读写并汇报, 存储信息给NameNode.
Secondary NameNode定期会合并fsimge和image两个文件:
2、HDFS读操作

2.1
- 1、Client通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象时分布文件系统的一个实例;
- DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一Block按照重复数会返回多个位置,这些位置按照Hadoop集群拓扑结构排序,距离客户端近的排在前面;
- 3、前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法;
- 4、存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端;
- 5、到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode,这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流;
- 6、一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取。
2.2、使用的是服务器模式,加入hadoop配置文件

2.x、代码如下
package com.chb.test;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapreduce.Job;
public class FileSystemCat {
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME", "chb");
Configuration conf = new Configuration();
String file = "/user/chb/input/wc.txt";
InputStream in = null;
try {
FileSystem fs = FileSystem.get(URI.create(file),conf);
in = fs.open(new Path(file));
IOUtils.copyBytes(in, System.out, 4096);
} catch (Exception e) {
e.printStackTrace();
}finally {
IOUtils.closeStream(in);
}
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









