






反向传播算法
引言
在上篇文章中,谈了对梯度下降算法的见解,对于单层神经网络,我们很容易计算出损失对权重的导数。而对于一个复杂的神经网络,如下图所示,我们很难求出损失函数对权重的导数。梯度下降法是寻找到最优点,即找到使损失函数最小值的点,从而达到良好优化效果。而反向传播算法就是求最终的输出,也即损失函数最小值对前面各个参数的偏导的过程。一个神经网络训练过程,它包括了前向传播、反向传播、以及更新损失参数三个基本部分。
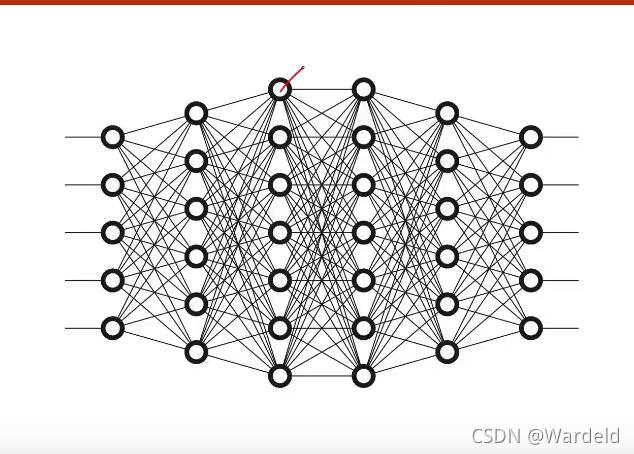
深刻理解反向传播算法
在实践中,神经网络包含许多连接在一起的张量运算,每个运算都有简单的、已知的导数。
对于这种连接在一起、多层嵌套的函数链,我们可以通过链式求导法则应用于神经网络梯度值的计算,亦即在神经网络模型中反向传播算法的作用就是要求出这个梯度值,从而后续用梯度下降去更新模型参数。反向传播算法从模型的输出层开始,利用函数求导的链式法则,逐层从后向前求出模型梯度。
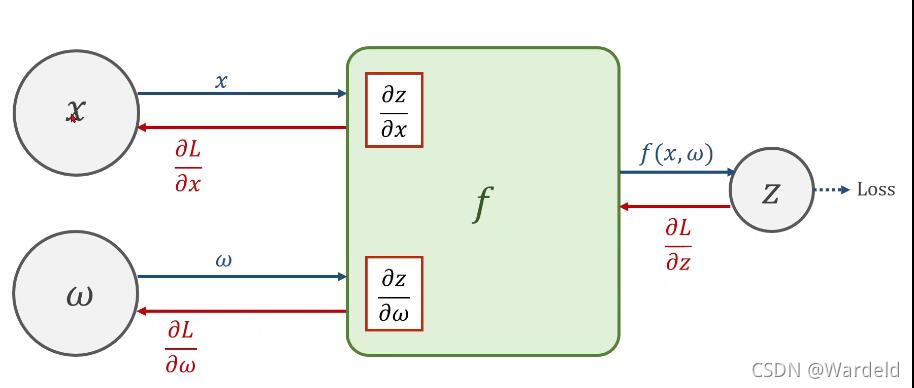
这是一个二层的链式求导法则。而事实上,我们的x也可能是某个二层多层的神经网络的输出,一层层嵌套。上面只是展示了一个简单的二层链式求导法则的示例。
示例
代码如下:
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True # 默认的Tensor是不需要计算梯度的,此处定义为需计算梯度
# 定义模型
def forward(x):
return x * w
# 定义损失函数,loss = (y' - y)²
def loss(x, y):
y_pired = forward(x)
return (y - y_pired) ** 2
print('predict(before training)', 4, forward(4).item()) # .item()转换数据类型,
for epoh in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) #前馈
l.backward() #反馈
print('\tgrad', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
w.grad.zero_() # 反向传播的梯度清零
print('process', epoh, l.item())
print('predict(after tarining)', 4, forward(4).item())
输出部分结果
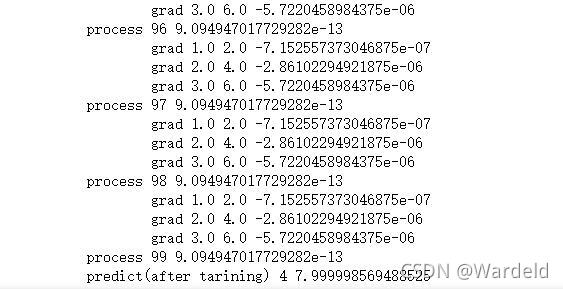
















 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











