






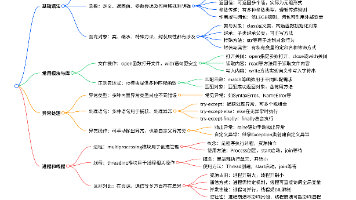
一、基础语法
(1)变量与数据类型
变量:用于存储数据的标识符,无需事先声明类型,根据赋值自动确定。
数据类型:包括整数(int)、浮点数(float)、字符串(str)、布尔值(bool)、列表(list)、元组(tuple)、集合(set)和字典(dict)等。
一、不可变类型(Immutable)
不可修改对象的值,修改时会创建新对象。
整型(int)示例:x = 10
特点:支持大整数运算(无溢出问题)
浮点型(float)示例:y = 3.14
注意:存在精度问题(如 0.1 + 0.2 != 0.3)。
布尔型(bool)示例:flag = True
本质:True 和 False 是 int 的子类(True == 1, False == 0)。
字符串(str)示例:s = "hello"
操作:切片 s[1:3],方法如 split(), strip(), format()。
特性:不可修改,s[0] = 'H' 会报错。
元组(tuple)示例:t = (1, 2, "a")
特点:不可变,用于存储固定数据(如坐标、数据库记录)。
字节序列(bytes)示例:b = b"hello"(仅ASCII字符)
用途:二进制数据存储或传输。
二、可变类型(Mutable)
对象的值可直接修改,内存地址不变。
列表(list)示例:lst = [1, 2, 3]
操作:
增删:append(), insert(), pop()
切片:lst[1:3] = [20, 30]
排序:sort(), sorted()
字典(dict)
示例:d = {"name": "Alice", "age": 25}
规则:
键必须是不可变类型(如 str, int, tuple)。
操作:keys(), values(), get("key", default)
用途:快速键值查找(哈希表实现)。
集合(set)示例:s = {1, 2, 3}
特性:元素唯一、无序,支持集合运算(并集 |,差集 -)。
方法:add(), remove(), intersection().
字节数组(bytearray)示例:ba = bytearray(b"hello")
特性:类似 bytes,但可修改(如 ba[0] = 72)。
三、特殊类型
None
表示空值:x = None用途:初始化变量或函数默认返回值。
复数(complex)示例:c = 3 + 4j
属性:c.real 获取实部,c.imag 获取虚部。
四、类型转换
| 函数 | 说明 | 示例 |
| int() | 转整型(截断小数) | int(3.9) → 3 |
| float() | 转浮点型 | float(5) → 5.0 |
| str() | 转字符串 | str(100) → "100" |
| list() | 转列表 | list("abc") → ['a','b','c'] |
| tuple() | 转元组 | tuple([1,2]) → (1,2) |
| set() | 转集合(去重) | set([1,1,2]) → {1,2} |
| dict() | 创建字典 | dict([("a",1)]) → {"a":1} |
五、重要特性
可变 vs 不可变
不可变对象 作为函数参数时,函数内修改不会影响外部变量。
可变对象(如列表、字典)作为参数时,函数内修改会影响外部变量。
pythondef modify(lst): lst.append(4) # 原列表会被修改 a = [1, 2, 3]modify(a)print(a) # 输出 [1, 2, 3, 4]
深浅拷贝
浅拷贝:copy() 方法或 list(), dict() 构造函数,仅复制外层对象。
深拷贝:import copy; copy.deepcopy(x),递归复制所有嵌套对象。
- 函数
基本语法
pythondef 函数名(参数): """文档字符串(可选)""" 代码块 return 返回值 # 可选
示例:pythondef add(a, b): return a + bresult = add(3, 5) # 调用
返回值
可返回多个值(实际返回元组):pythondef get_data(): return 1, "hello", Truex, y, z = get_data() # 元组解包
- 参数传递
参数类型
位置参数:按顺序传递,如 add(3, 5)。
关键字参数:指定参数名,如 add(b=5, a=3)。
默认参数:定义时赋值,如 def greet(name="Guest"):。
可变参数:
*args:接收任意数量位置参数(元组)。
**kwargs:接收任意数量关键字参数(字典)。
pythondef func(a, b=0, *args, **kwargs): print(a, b, args, kwargs) func(1, 2, 3, 4, key="value")# 输出:1 2 (3,4) {'key': 'value'}
参数传递规则
不可变对象(如整数、字符串):函数内修改不会影响外部变量。
可变对象(如列表、字典):函数内修改会影响外部变量。
pythondef modify_list(lst): lst.append(4) my_list = [1, 2, 3]modify_list(my_list)print(my_list) # 输出 [1, 2, 3, 4]
三、作用域与闭包
作用域规则(LEGB)
Local → Enclosing → Global → Built-in。
使用 global 或 nonlocal 修改外部变量:pythonx = 10def change_x(): global x x = 20闭包
内部函数引用外部函数变量:pythondef outer(): n = 1 def inner(): nonlocal n n += 1 return n return inner counter = outer()print(counter()) # 输出 2
- 面向对象(OOP)
类与对象
定义类:class MyClass:,构造函数 __init__(self, ...)。
继承:class Child(Parent):,重写方法,super()调用父类。
特殊方法
__str__(字符串表示)、__len__、__getitem__等。
封装与属性
私有变量:_protected(约定)或 __private(名称修饰)。
- 常用模块与库
os(文件/目录操作),re(正则表达式)
文件操作
1.文本文件2.二进制文件
读写文件:with open("file.txt", "r") as f: content = f.read()。
模式:r(读)、w(写)、a(追加)、b(二进制)。
#对文件的操作
打开和关闭文件
使用 open() 函数打开文件,其基本语法为:open(file, mode='r', encoding=None),其中:file:表示要操作的文件名(可以是相对路绝对路径)。
mode:指定打开文件的模式,常见的模式有 'r'(只读)、'w'(写入,会覆盖原文件内容)、'a'(追加,在文件末尾添加内容)、'x'(创建新文件,若文件已存在则报错) 、'rb'(以二进制模式读取)、'wb'(以二进制模式写入)等。
encoding:指定文件的编码方式,如 'utf-8'、'gbk' 等。
使用 close() 方法关闭文件,示例如下:
python
file = open('example.txt', 'w', encoding='utf-8')# 执行文件操作file.close()
更推荐使用 with 语句,它会在代码块结束时自动关闭文件,示例如下:
python
with open('example.txt', 'w', encoding='utf-8') as file:
# 执行文件操作
pass
读取文件内容
常见的读取方法有:
read():读取整个文件内容,返回一个字符串。
readline():读取文件的一行内容,返回一个字符串。
readlines():读取文件的所有行,返回一个包含每行内容的列表。
示例如下:python
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
file.seek(0) # 将文件指针移动到文件开头
line = file.readline()
print(line)
file.seek(0)
lines = file.readlines()
for line in lines:
print(line, end='')
写入文件内容
使用 write() 方法写入字符串到文件中,示例如下:
python
with open('example.txt', 'w', encoding='utf-8') as file:
file.write("Hello, world!\n")
file.write("This is a new line.")
正则表达式
re.match(pattern, string, flags=0)
从字符串的起始位置开始匹配,如果匹配成功,返回一个匹配对象;否则返回 None。示例如下:
python
import re
pattern = r'hello'
string = 'hello world'
result = re.match(pattern, string)if result:
print("匹配成功:", result.group())else:
print("匹配失败")
re.search(pattern, string, flags=0)
在字符串中搜索匹配的模式,若找到第一个匹配项,返回匹配对象;否则返回 None。示例如下:
python
import re
pattern = r'world'
string = 'hello world'
result = re.search(pattern, string)if result:
print("匹配成功:", result.group())else:
print("匹配失败")
re.findall(pattern, string, flags=0)
查找字符串中所有匹配的模式,并以列表形式返回所有匹配结果。示例如下:
python
import re
pattern = r'\d+'
string = 'abc123def456'
result = re.findall(pattern, string)print("匹配结果:", result)
re.sub(pattern, repl, string, count=0, flags=0)
用于替换字符串中所有匹配的模式。repl 是替换的字符串。示例如下:
python
import re
pattern = r'world'
string = 'hello world'
new_string = re.sub(pattern, 'Python', string)print("替换后的字符串:", new_string)
re.split(pattern, string, maxsplit=0, flags=0)
根据匹配的模式分割字符串,并返回分割后的列表。示例如下:
python
import re
pattern = r'[ ,.]+'
string = 'hello, world. python'
result = re.split(pattern, string)print("分割结果:", result)
匹配对象的方法
当使用 re.match() 或 re.search() 等函数匹配成功后,会返回一个匹配对象,该对象有一些常用方法:
group():返回匹配的字符串。
start():返回匹配字符串的起始位置。
end():返回匹配字符串的结束位置。
span():返回一个元组,包含匹配字符串的起始和结束位置。
示例如下:
python
import re
pattern = r'hello'
string = 'hello world'
result = re.search(pattern, string)if result:
print("匹配的字符串:", result.group())
print("起始位置:", result.start())
print("结束位置:", result.end())
print("起始和结束位置:", result.span())
五、异常处理
Python 内置了多种异常类型,常见的有:
SyntaxError:语法错误,通常是代码书写不符合 Python 语法规则。
IndentationError:缩进错误,Python 对代码缩进有严格要求。
NameError:使用未定义的变量或函数。
TypeError:操作或函数应用于不兼容类型的对象。
ValueError:传入无效的参数值。
FileNotFoundError:尝试打开不存在的文件。
异常处理语句
try-except 语句
try-except 语句用于捕获和处理异常,基本语法如下:
python
try:
# 可能会抛出异常的代码块
result = 1 / 0except ZeroDivisionError:
# 处理特定类型异常的代码块
print("除数不能为零!")
可以使用多个 except 子句来捕获不同类型的异常,示例如下:
Python
try:
num = int(input("请输入一个整数: "))
result = 10 / numexcept ValueError:
print("输入不是有效的整数!")except ZeroDivisionError:
print("除数不能为零!")
还可以使用一个 except 子句捕获多种类型的异常,示例如下:
python
try:
num = int(input("请输入一个整数: "))
result = 10 / numexcept (ValueError, ZeroDivisionError):
print("输入无效或除数为零!")
try-except-else 语句
else 子句在 try 代码块没有抛出异常时执行,示例如下:
python
try:
num = int(input("请输入一个整数: "))
result = 10 / numexcept ValueError:
print("输入不是有效的整数!")except ZeroDivisionError:
print("除数不能为零!")else:
print(f"结果是: {result}")
try-except-finally 语句
finally 子句无论 try 代码块是否抛出异常都会执行,常用于释放资源等操作,示例如下:
python
file = Nonetry:
file = open('example.txt', 'r')
content = file.read()
print(content)except FileNotFoundError:
print("文件未找到!")finally:
if file:
file.close()
抛出异常
使用 raise 语句可以手动抛出异常,示例如下:
python
def divide(a, b):
if b == 0:
raise ZeroDivisionError("除数不能为零!")
return a / b
try:
result = divide(10, 0)
print(result)except ZeroDivisionError as e:
print(e)
自定义异常
可以通过继承 Exception 类来创建自定义异常类,示例如下:
python
class MyCustomError(Exception):
def __init__(self, message):
self.message = message
def __str__(self):
return self.message
try:
raise MyCustomError("这是一个自定义异常!")except MyCustomError as e:
print(e)
通过合理运用异常处理机制,可以让 Python 程序在遇到错误时更稳定和可靠。
- 进程和线程
进程
概念
进程是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间、系统资源等,进程之间相互独立,一个进程的崩溃通常不会影响其他进程。
使用方法
Python 的 multiprocessing 模块可以用来创建和管理进程。以下是一个简单的示例:
python
import multiprocessing
def worker(num):
"""进程要执行的任务"""
print(f'Worker {num} started')
result = num * num
print(f'Worker {num} result: {result}')
if __name__ == '__main__':
processes = []
for i in range(3):
p = multiprocessing.Process(target=worker, args=(i,))
processes.append(p)
p.start()
for p in processes:
p.join()
print('All processes finished')
在上述代码中:
multiprocessing.Process 用于创建一个新的进程,target 参数指定进程要执行的函数,args 参数是传递给该函数的参数。
p.start() 启动进程。
p.join() 用于等待进程执行完毕。
线程
概念
线程是进程中的一个执行单元,一个进程可以包含多个线程,这些线程共享进程的内存空间和系统资源。线程的创建和销毁开销相对较小,适合处理 I/O 密集型任务。
使用方法
Python 的 threading 模块可用于创建和管理线程。以下是一个简单的示例:
python
import threading
def worker(num):
"""线程要执行的任务"""
print(f'Thread {num} started')
result = num * num
print(f'Thread {num} result: {result}')
if __name__ == '__main__':
threads = []
for i in range(3):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
print('All threads finished')
在上述代码中:
threading.Thread 用于创建一个新的线程,target 参数指定线程要执行的函数,args 参数是传递给该函数的参数。
t.start() 启动线程。
t.join() 用于等待线程执行完毕。
进程和线程的区别
资源占用:进程拥有自己独立的内存空间和系统资源,资源开销较大;线程共享进程的内存空间和系统资源,资源开销相对较小。
通信方式:进程间通信(IPC)需要使用特定的机制,如管道、队列、共享内存等;线程间通信相对简单,可以直接访问共享的全局变量。
并发性能:进程可以利用多核 CPU 的优势,实现真正的并行计算;由于 Python 的全局解释器锁(GIL),同一时刻只有一个线程可以执行 Python 字节码,对于 CPU 密集型任务,多线程并不能提高性能,但对于 I/O 密集型任务,多线程可以提高程序的并发性能。
健壮性:进程之间相互独立,一个进程的崩溃不会影响其他进程;线程共享进程的资源,一个线程的崩溃可能会导致整个进程崩溃。

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









