







一、由来:
系统里可能有多个cpu,每个cpu都可能调用伙伴算法申请内存,而且大部分申请的大小都是1个page。多个cpu同时申请内存的时候,会造成并发访问(每个zone有一个spin lock,从zone申请内存的时候需要lock),影响系统执行效率。
内核对只分配一页物理内存的情况做了特殊处理,当只请求一页内存时,内核会借助 CPU 高速缓存冷热页列表 pcplist 加速内存分配的处理,此时分配的内存页将来自于 pcplist 而不是伙伴系统。
为了解决上述问题,内核对只分配一页物理内存的情况做了特殊处理,当只请求一页内存时,内核会借助 CPU 高速缓存冷热页列表 pcplist 加速内存分配的处理,此时分配的内存页将来自于 pcplist 而不是伙伴系统。这样在分配和释放内存时,可以避免多个CPU同时访问同一个全局内存池,从而提高性能。
二、数据结构:
mmzone.h - include/linux/mmzone.h - Linux source code v5.4.285 - Bootlin Elixir Cross Referencer
struct zone {
...
struct per_cpu_pageset __percpu *pageset; //是结构体指针变量。每个cpu都有一个,因此是个数组
};
struct per_cpu_pageset {
struct per_cpu_pages pcp;
#ifdef CONFIG_NUMA
s8 expire;
u16 vm_numa_stat_diff[NR_VM_NUMA_STAT_ITEMS];
#endif
#ifdef CONFIG_SMP
s8 stat_threshold;
s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS];
#endif
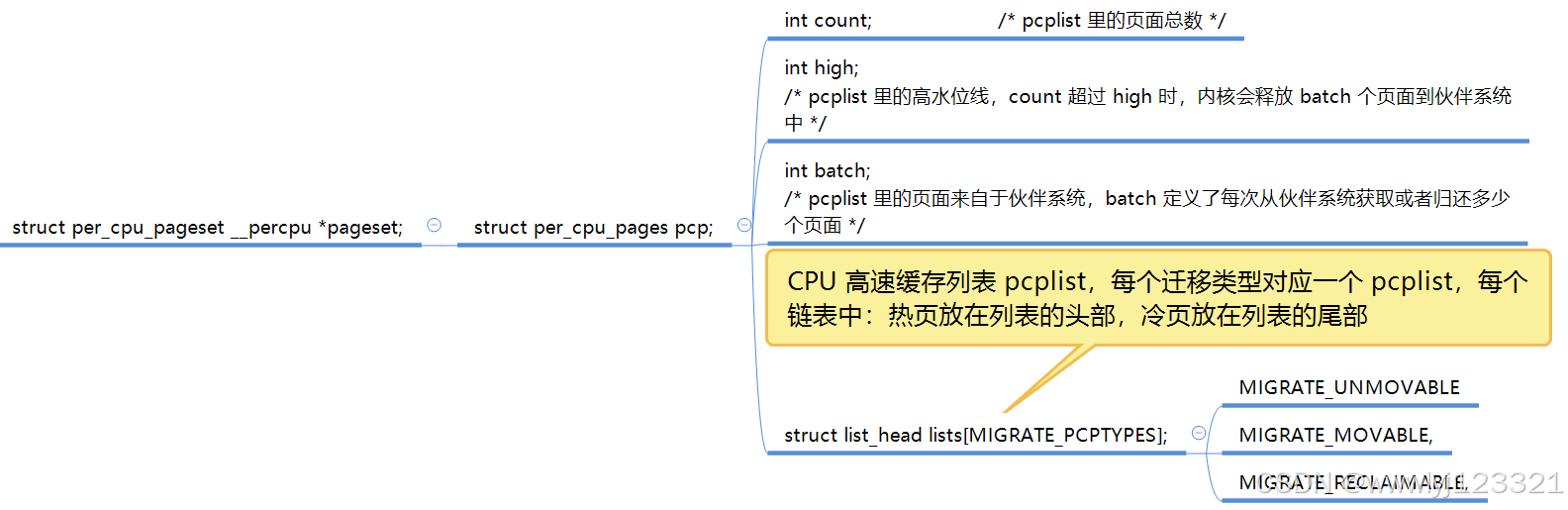
};| ---类型--- | ---名称--- | ---描述--- |
|---|---|---|
| int | count | 该链表中物理页的个数 |
| int | high | 记录了per_cpu缓存中页帧的上限 如果超过这个值就将释放 batch个页帧到buddy中去 同理,如果per_cpu中没有可分配的页帧就从伙伴系统中分配batch个页帧到缓存中来。 |
| int | batch | 每次从buddy系统返还或申请的物理页的个数 |
| struct list_head | list | 高速缓存中的页框描述符链表。 内核为了最大程度的防止内存碎片,将物理内存页面按照是否可迁移的特性分为了多种迁移类型:可迁移,可回收,不可迁移。在 struct per_cpu_pages 结构中,每一种迁移类型都会对应一个冷热页链表。 |
三、PCP基本原理:
内存分配:
当一个CPU需要分配内存时,首先检查它自己的PCP列表。如果PCP列表中有空闲page,就直接从PCP列表中分配。如果PCP列表为空,则从全局内存池中获取一批(batch个 pages),放入PCP列表,然后再从PCP列表中分配所需的page。
内存释放:
当一个CPU释放内存时,首先将页面放入它自己的PCP列表。
如果PCP列表已满,则将多余的页面返回到全局内存池。
四、源码分析:
4.1、pcp的初始化
mm/page_alloc.c
/*
* Allocate per cpu pagesets and initialize them.
* Before this call only boot pagesets were available.
*/
void __init setup_per_cpu_pageset(void)
{
struct pglist_data *pgdat;
struct zone *zone;
for_each_populated_zone(zone)
setup_zone_pageset(zone);//设置每一个zone的pageset
for_each_online_pgdat(pgdat)
pgdat->per_cpu_nodestats =
alloc_percpu(struct per_cpu_nodestat);
}
void __meminit setup_zone_pageset(struct zone *zone)
{
int cpu;
// 原来的pageset职责是由全局的boot_pageset变量担当的,现在进行重新申请.
// 关于alloc_percpu的percpu资源初始化是在setup_per_cpu_areas中完成的,
// 这是通过bootmem完成的资源分配.
// 为每一个cpu分配了一个,所以zone->pageset是数组指针
zone->pageset = alloc_percpu(struct per_cpu_pageset);
for_each_possible_cpu(cpu)
zone_pageset_init(zone, cpu);
}
static void __meminit zone_pageset_init(struct zone *zone, int cpu)
{
struct per_cpu_pageset *pcp = per_cpu_ptr(zone->pageset, cpu);
//初始化链表 lists[MIGRATE_UNMOVABLE] lists[MIGRATE_MOVABLE] lists[MIGRATE_RECLAIMABLE]
pageset_init(pcp);
//见详细函数分析
pageset_set_high_and_batch(zone, pcp);
}
static void pageset_set_high_and_batch(struct zone *zone,
struct per_cpu_pageset *pcp)
{
if (percpu_pagelist_fraction)
pageset_set_high(pcp,
(zone_managed_pages(zone) /
percpu_pagelist_fraction));
else
pageset_set_batch(pcp, zone_batchsize(zone));
}
/* a companion to pageset_set_high() */
static void pageset_set_batch(struct per_cpu_pageset *p, unsigned long batch)
{
pageset_update(&p->pcp, 6 * batch, max(1UL, 1 * batch));
}
static void pageset_update(struct per_cpu_pages *pcp, unsigned long high,
unsigned long batch)
{
/* start with a fail safe value for batch */
pcp->batch = 1;
smp_wmb();
/* Update high, then batch, in order */
pcp->high = high;
smp_wmb();
pcp->batch = batch;
}变量percpu_pagelist_fraction 和/proc/sys/vm/percpu_pagelist_fraction,关联。默认值为0
{
.procname = "percpu_pagelist_fraction",
.data = &percpu_pagelist_fraction,
.maxlen = sizeof(percpu_pagelist_fraction),
.mode = 0644,
.proc_handler = percpu_pagelist_fraction_sysctl_handler,
.extra1 = SYSCTL_ZERO,
},当指定了percpu_pagelist_fraction:
//pageset_set_high(pcp, (zone_managed_pages(zone) /percpu_pagelist_fraction));
static void pageset_set_high(struct per_cpu_pageset *p,
unsigned long high)
{
unsigned long batch = max(1UL, high / 4);
if ((high / 4) > (PAGE_SHIFT * 8))
batch = PAGE_SHIFT * 8;
pageset_update(&p->pcp, high, batch);
}high = managed_pages / percpu_pagelist_fraction
batch 在high 的基础上除以4,然后限制最大值(PAGE_SHIFT * 8,4K页的PAGE_SHIFT为12)
当没有指定percpu_pagelist_fraction:pcp->batch 是通过 zone_batchsize() 计算得来
static int zone_batchsize(struct zone *zone)
{
#ifdef CONFIG_MMU
int batch;
batch = zone_managed_pages(zone) / 1024;
/* But no more than a meg. */
if (batch * PAGE_SIZE > 1024 * 1024)
batch = (1024 * 1024) / PAGE_SIZE;
batch /= 4; /* We effectively *= 4 below */
if (batch < 1)
batch = 1;
//rounddown_pow_of_two求最接近的最大2的指数次幂,比如数字8是5的接近的2的整数次幂。
batch = rounddown_pow_of_two(batch + batch/2) - 1;
return batch;
#else
return 0;
#endif
}batch = zone_managed_pages /1024,并限制上限为256(page size为4K的情况下)
接着用新的batch 除以 4,并设置下限为1
到此为止,batch的范围为[1, 64]
//Clamp the batch to a 2^n - 1 value
batch = rounddown_pow_of_two(batch + batch/2) - 1;
pcp->high = pcp->batch * 6;
4.2、pcp的申请
当内核尝试从 pcplist 中获取一个物理内存页时,会首先获取运行当前进程的 CPU 对应的高速缓存列表 pcplist。然后根据指定的具体页面迁移类型 migratetype 获取对应迁移类型的 pcplist。
当获取到符合条件的 pcplist 之后,内核会调用 __rmqueue_pcplist 从 pcplist 中摘下一个物理内存页返回。
当 pcplist 中的页面数量 count 为 0 (表示此时 pcplist 里没有缓存的页面)时,内核会调用 rmqueue_bulk 从伙伴系统中获取 batch 个物理页面添加到 pcplist
page_alloc.c - mm/page_alloc.c - Linux source code v5.4.285 - Bootlin Elixir Cross Referencer
static struct page *rmqueue_pcplist(struct zone *preferred_zone,
struct zone *zone, gfp_t gfp_flags,
int migratetype, unsigned int alloc_flags)
{
struct per_cpu_pages *pcp;
struct list_head *list;
struct page *page;
unsigned long flags;
// 关闭中断
local_irq_save(flags);
// 获取运行当前进程的 CPU 高速缓存列表 pcplist
pcp = &this_cpu_ptr(zone->pageset)->pcp;
// 获取指定页面迁移类型的 pcplist
list = &pcp->lists[migratetype];
// 从指定迁移类型的 pcplist 中移除一个页面,用于内存分配
page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list);
if (page) {
// 统计内存区域内的相关信息
zone_statistics(preferred_zone, zone);
}
// 开中断
local_irq_restore(flags);
return page;
}
static struct page *__rmqueue_pcplist(struct zone *zone, int migratetype,
unsigned int alloc_flags,
struct per_cpu_pages *pcp,
struct list_head *list)
{
struct page *page;
do {
// 如果当前 pcplist 中的页面为空,那么则从伙伴系统中获取 batch 个页面放入 pcplist 中
if (list_empty(list)) {
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, alloc_flags);
if (unlikely(list_empty(list)))
return NULL;
}
// 获取 pcplist 上的第一个物理页面
page = list_first_entry(list, struct page, lru);
// 将该物理页面从 pcplist 中摘除
list_del(&page->lru);
// pcplist 中的 count 减一
pcp->count--;
} while (check_new_pcp(page));
return page;
}PCP列表的优点
减少锁争用:由于每个CPU都有自己的PCP列表,内存分配和释放时不需要频繁地获取全局锁,从而减少了锁争用,提高了系统的并发性能。
提高缓存命中率:PCP列表中的页面更有可能被同一个CPU再次使用,从而提高了缓存命中率,减少了内存访问延迟。
在Linux内核中,可以通过一些内核参数来调整PCP列表的行为,例如:
- min_free_kbytes:设置系统中保持的最小空闲内存量。
- percpu_pagelist_fraction:设置每个CPU的PCP列表大小占系统总内存的比例。
4.3、pcp的释放
/*
* Free a 0-order page
*/
void free_unref_page(struct page *page)
{
unsigned long flags;
// 获取要释放的物理内存页对应的物理页号 pfn
unsigned long pfn = page_to_pfn(page);
// 关闭中断
local_irq_save(flags);
// 释放物理内存页至 pcplist 中
free_unref_page_commit(page, pfn);
// 开启中断
local_irq_restore(flags);
}通过 free_unref_page_commit 函数将内存页释放至 CPU 高速缓存列表 pcplist 中,这里大家需要注意的是在释放的过程中是不会响应中断的。
static void free_unref_page_commit(struct page *page, unsigned long pfn)
{
// 获取内存页所在物理内存区域 zone
struct zone *zone = page_zone(page);
// 运行当前进程的 CPU 高速缓存列表 pcplist
struct per_cpu_pages *pcp;
// 页面的迁移类型
int migratetype;
migratetype = get_pcppage_migratetype(page);
// 内核这里只会将 UNMOVABLE,MOVABLE,RECLAIMABLE 这三种页面迁移类型放入 pcplist 中,其余的迁移类型均释放回伙伴系统
if (migratetype >= MIGRATE_PCPTYPES) {
if (unlikely(is_migrate_isolate(migratetype))) {
// 释放回伙伴系统
free_one_page(zone, page, pfn, 0, migratetype);
return;
}
// 内核这里会将 HIGHATOMIC 类型页面当做 MIGRATE_MOVABLE 类型处理
migratetype = MIGRATE_MOVABLE;
}
// 获取运行当前进程的 CPU 高速缓存列表 pcplist
pcp = &this_cpu_ptr(zone->pageset)->pcp;
// 将要释放的物理内存页添加到 pcplist 中
list_add(&page->lru, &pcp->lists[migratetype]);
// pcplist 页面计数加一
pcp->count++;
// 如果 pcp 中的页面总数超过了 high 水位线,则将 pcp 中的 batch 个页面释放回伙伴系统中
if (pcp->count >= pcp->high) {
unsigned long batch = READ_ONCE(pcp->batch);
// 释放 batch 个页面回伙伴系统中
free_pcppages_bulk(zone, batch, pcp);
}
}这里需要注意的是,内核只会将 UNMOVABLE,MOVABLE,RECLAIMABLE 这三种页面迁移类型放入 CPU 高速缓存列表 pcplist 中,其余的迁移类型均需释放回伙伴系统。
如果当前 pcplist 中的页面数量 count 超过了规定的水位线 high 的值,说明现在 pcplist 中的页面太多了,需要从 pcplist 中释放 batch 个物理页面到伙伴系统中。这个过程称之为惰性合并。
根据本文 "4. 伙伴系统的内存回收原理" 小节介绍的内容,我们知道,单内存页直接释放回伙伴系统会发生很多合并的动作,这里的惰性合并策略阻止了大量的无效合并操作。
ref:
内核源码解读之内存管理(10)percpu_page_set分析_linux per cpu page-CSDN博客
内存管理-11-buddy伙伴子系统-2-Per-CPU页帧缓存 - Hello-World3 - 博客园

















 2633
2633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









