







1、经典网络VGG16 basic
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
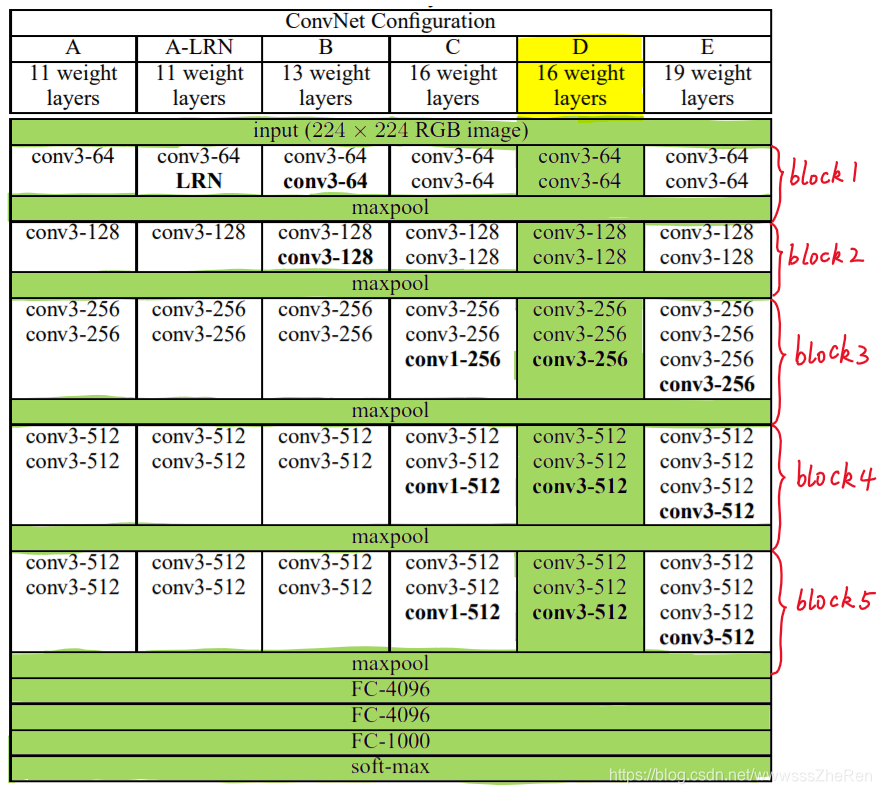
针对VGG16进行具体分析发现,VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
conv3-64的全称是convolution kernel_size=3, the number of kernel=64,该层有64个3*3的卷积和实施卷积操作。每一个卷积层都对输入图像进行了padding操作,padding的尺寸需要正好保证输出图像的尺寸与输入图像相同。
FC4096全称是Fully Connected 4096,是输出层连接4096个神经元的全连接层。
2、针对VGG16具体解释
1)block1解释
VGG16的输入图像为224*224*3,第一个conv3-64的意思是由64个3*3*3(3代表通道数)的卷积核去卷积输入图像,1个3*3*3的卷积核与图像224*224*3卷积,再通过padding后得到1个224*224大小的矩阵图像,那么64个3*3*3的卷积核去卷积输出的结果为224*224*64的矩阵图像组。针对输入224*224*64的矩阵图像组,第二个conv3-64的含义是由64个3*3*64的矩阵卷积核组去卷积矩阵图像组,由于1个224*224*64的矩阵图像组和1个3*3*64的矩阵卷积核组得到1个224*224大小的矩阵图像,故block1的最终输出结果就是224*224*64。
block1中的param分别为(第一个conv3-64:(3*3*3)*64;第二个conv3-64:(3*3*64)*64)
2)经过block1后的maxpooling1的输出层数据为为112*112*64
3)block2解释
block2的输入数据是112*112*64,conv3-128代表的意思是由128个3*3*64(64代表通道数)的卷积核去卷积输入数据,与之前讲述相同,此时得到112*112*128矩阵图像组。
block2中的param分别是(第一个conv3-128:(3*3*64)*128;第二个conv3-128:(3*3*128)*128)
4)经过block2后的maxpooling2的输出层数据为56*56*128
5)block3解释
block3的输入数据是56*56*128,conv3-256代表的意思是由256个3*3*128(128代表通道数)的卷积核去卷积输入数据,与之前讲述相同,此时得到56*56*256矩阵图像组。
block3的param分别是(第一个conv3-256:(3*3*128)*256;第二个conv3-256:(3*3*256)*256;第二个conv3-256:(3*3*256)*256)
6)经过block3后的maxpooling3的输出层数据为28*28*256
7)block4、block5以此类推
8)block5后maxpooling5的输出层数据为7*7*512
9)FC-4096层的输入数据为7*7*512,全连接层有4096个神经元。
FC-4096中的param为7*7*512*4096
3、VGG16的参数

图中蓝色是计算权重参数数量的部分;红色是计算所需存储容量的部分。
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;但同时缺点也很明显:
- 即训练时间过长,调参难度大。
- 需要的存储容量大,不利于部署。例如存储VGG16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
4、VGG16的具体结构
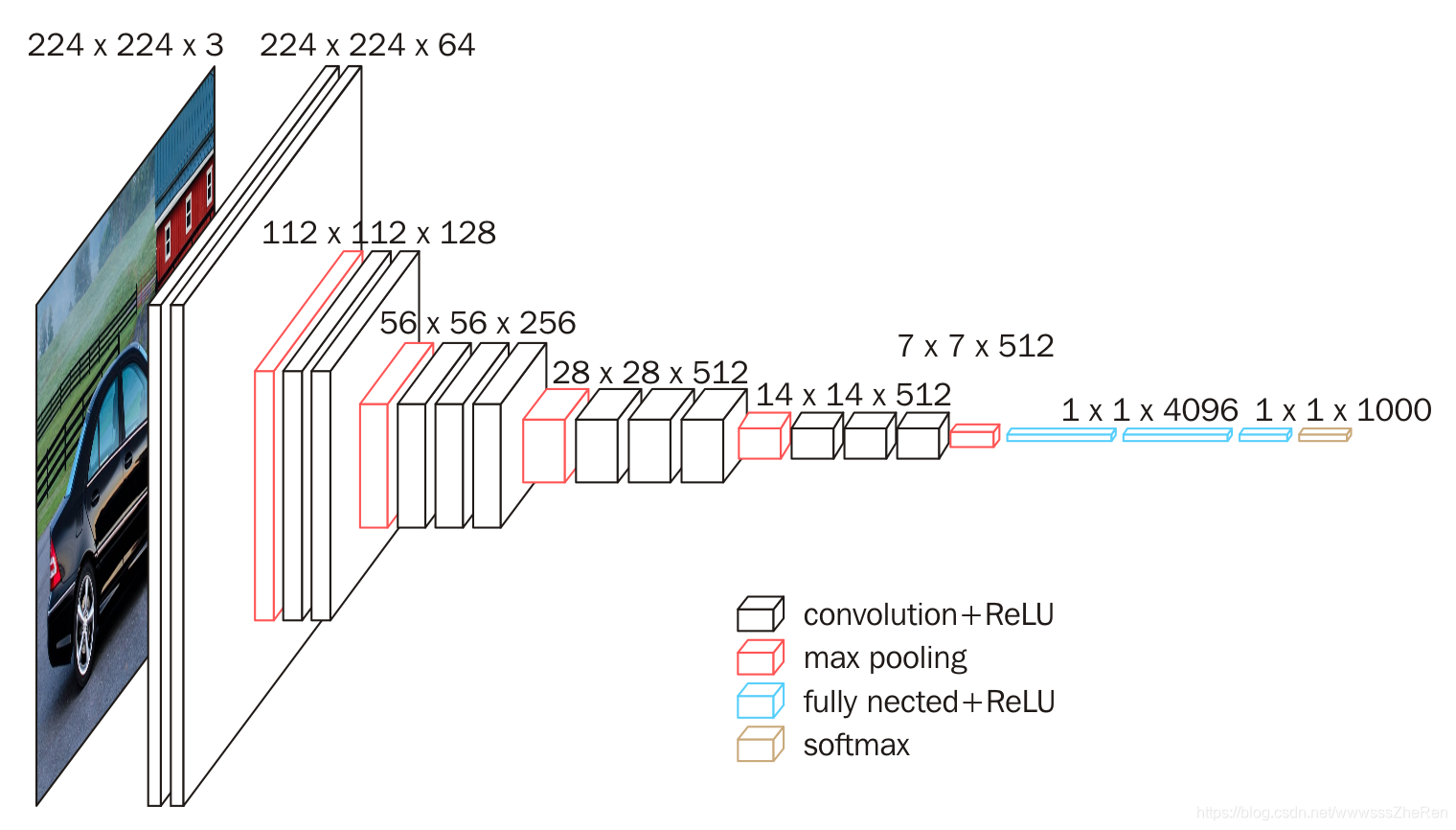
首先需要解释为什么把一个224*224*3的3通道的RGB图像->变成了224*224*64有着64通道的图像组合?
答:这里是拿64组3*3*3的卷积核去卷积这一个RGB图像。一组3*3*3的卷积核去卷积一组224*224*3的图像(27个数求和,然后扫过去),借助padding后,得到的是一个224*224的图像,那么64组卷积和就得到64组224*224的图像,即224*224*64这一个64通道的图像组合。
5、关于VGG16网络的迁移学习
vgg16对应的供keras使用的模型人家已经帮我们训练好,我们将学习好的 VGG16 的权重迁移(transfer)到自己的卷积神经网络上作为网络的初始权重,这样我们自己的网络不用从头开始从大量的数据里面训练,从而提高训练速度。这里的迁移就是平时所说的迁移学习。
参考文章:

















 4116
4116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









