






1模型量化
模型量化是一种将深度学习模型中的浮点数参数和计算操作转换为定点数参数和计算操作的过程,旨在减少模型的存储空间和计算量,从而提高模型在移动设备和嵌入式系统上的部署效率。具体来说,模型量化是将高比特的权重和特征值用更低比特来表示的方法,例如从32位浮点数(float32)转换为8位或16位整数。模型量化是一种有效的模型压缩技术,通过将浮点数转换为定点数,减少了模型的存储需求和计算开销,同时尽量保持模型的性能。
2LMDeploy过程
2.1 模型下载
为方便文件管理,我们需要一个存放模型的目录
运行以下命令,创建文件夹并设置开发机共享目录的软链接。
mkdir /root/models
ln -s /root/share/new_models//Shanghai_AI_Laboratory/internlm2_5-7b-chat /root/models/internlm2_5-7b-chat
此时,我们可以看到/root/models中会出现internlm2_5-7b-chat文件夹
2.2 安装 lmdeploy
conda create -n lagent python=3.10 -y
conda activate lagent
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
pip install timm==1.0.8 openai==1.40.3 lmdeploy[all]==0.5.3
2.3 模型发布
conda activate lagent
lmdeploy serve api_server /share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat --model-name internlm2_5-7b-chat
查看显存使用情况

2.4 W4A16 模型量化和部署
W4A16是什么意思?
- W4:这通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16,Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。
- A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
因此,W4A16的量化配置意味着:
- 权重被量化为4位整数。
- 激活保持为16位浮点数。
让我们回到LMDeploy,在最新的版本中,LMDeploy使用的是AWQ算法,能够实现模型的4bit权重量化。输入以下指令,执行量化工作。(本步骤耗时较长,请耐心等待)
lmdeploy lite auto_awq \
/root/models/internlm2_5-7b-chat \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/model/internlm2_5-7b-chat-w4a16-4bit
命令解释:
lmdeploy lite auto_awq:lite这是LMDeploy的命令,用于启动量化过程,而auto_awq代表自动权重量化(auto-weight-quantization)。/root/models/internlm2_5-7b-chat: 模型文件的路径。--calib-dataset 'ptb': 这个参数指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank,一个常用的语言模型数据集)。--calib-samples 128: 这指定了用于校准的样本数量—128个样本--calib-seqlen 2048: 这指定了校准过程中使用的序列长度—1024--w-bits 4: 这表示权重(weights)的位数将被量化为4位。--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit: 这是工作目录的路径,用于存储量化后的模型和中间结果。
我们可以看到过程
等待推理完成,便可以直接在你设置的目标文件夹看到对应的模型文件
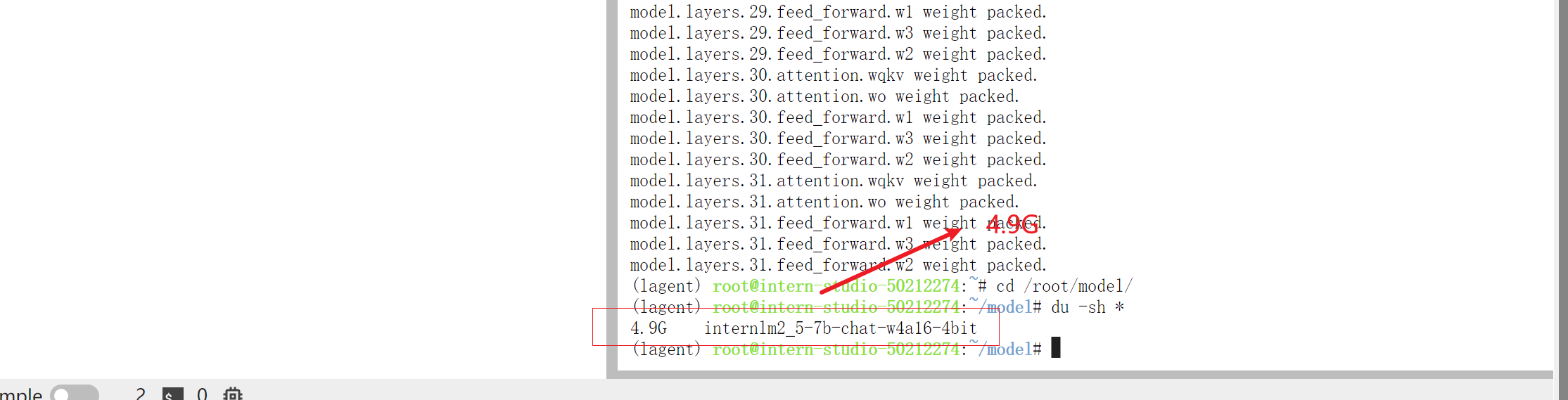
我们可以输入如下指令查看在当前目录中显示所有子目录的大小
cd /root/model/
du -sh *
输出结果如下。
那么显存占用情况对比呢?输入以下指令启动量化后的模型。
lmdeploy serve api_server /root/model/internlm2_5-7b-chat-w4a16-4bit --model-name internlm2_5-7b-chat
稍待片刻,我们直接观测右上角的显存占用情况。
可以发现,相比较于原先的23GB显存占用,W4A16量化后的模型少了约2GB的显存占用

让我们计算一下2GB显存的减少缘何而来。
对于W4A16量化之前,我们2.3步骤看到显存占用情况(23GB)
1、在 BF16 精度下,7B模型权重占用14GB:70×10^9 parameters×2 Bytes/parameter=14GB
2、kv cache占用8GB:剩余显存24-14=10GB,kv cache默认占用80%,即10*0.8=8GB
3、其他项1GB
是故23GB=权重占用14GB+kv cache占用8GB+其它项1GB
而对于W4A16量化之后的显存占用情况(20.9GB):
1、在 int4 精度下,7B模型权重占用3.5GB:14/4=3.5GB
2、kv cache占用16.4GB:剩余显存24-3.5=20.5GB,kv cache默认占用80%,即20.5*0.8=16.4GB
3、其他项1GB
是故20.9GB=权重占用3.5GB+kv cache占用16.4GB+其它项1GB
如果启动的时候设定kv cache占用和kv cache int4量化
lmdeploy serve api_server \
/root/model/internlm2_5-7b-chat-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.6\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
此时显存占用17.5GB。 具体计算逻辑就不详细展开了。

接下来我们测试一下 效果
conda activate lagent
lmdeploy serve api_client http://localhost:23333
稍待片刻,等出现double enter to end input >>>的输入提示即启动成功,此时便可以随意与InternLM2.5对话,同样是两下回车确定,输入exit退出。
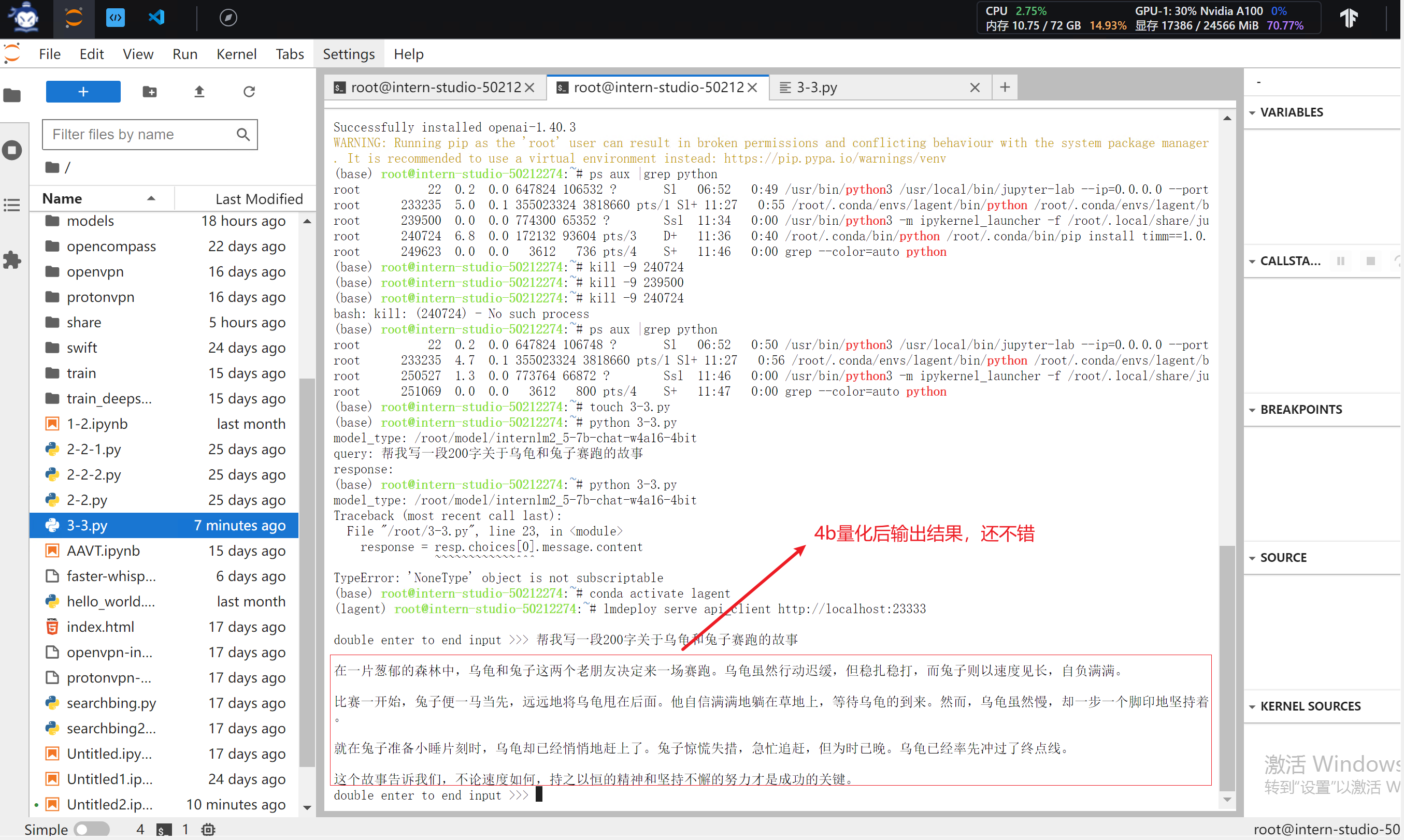
3 Function call
关于Function call,即函数调用功能,它允许开发者在调用模型时,详细说明函数的作用,并使模型能够智能地根据用户的提问来输入参数并执行函数。完成调用后,模型会将函数的输出结果作为回答用户问题的依据。
首先让我们进入创建好的conda环境并启动API服务器
conda activate lagent
lmdeploy serve api_server /share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat --model-name internlm2_5-7b-chat
让我们使用一个简单的例子作为演示。输入如下指令,新建internlm2_5_func.py。
touch /root/internlm2_5_func.py
双击打开,并将以下内容复制粘贴进internlm2_5_func.py。
from openai import OpenAI
def add(a: int, b: int):
return a + b
def mul(a: int, b: int):
return a * b
tools = [{
'type': 'function',
'function': {
'name': 'add',
'description': 'Compute the sum of two numbers',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'int',
'description': 'A number',
},
'b': {
'type': 'int',
'description': 'A number',
},
},
'required': ['a', 'b'],
},
}
}, {
'type': 'function',
'function': {
'name': 'mul',
'description': 'Calculate the product of two numbers',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'int',
'description': 'A number',
},
'b': {
'type': 'int',
'description': 'A number',
},
},
'required': ['a', 'b'],
},
}
}]
messages = [{'role': 'user', 'content': 'Compute (3+5)*2'}]
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
stream=False,
tools=tools)
print(response)
func1_name = response.choices[0].message.tool_calls[0].function.name
func1_args = response.choices[0].message.tool_calls[0].function.arguments
func1_out = eval(f'{func1_name}(**{func1_args})')
print(func1_out)
messages.append({
'role': 'assistant',
'content': response.choices[0].message.content
})
messages.append({
'role': 'environment',
'content': f'3+5={func1_out}',
'name': 'plugin'
})
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
stream=False,
tools=tools)
print(response)
func2_name = response.choices[0].message.tool_calls[0].function.name
func2_args = response.choices[0].message.tool_calls[0].function.arguments
func2_out = eval(f'{func2_name}(**{func2_args})')
print(func2_out)
现在让我们输入以下指令运行python代码。
python /root/internlm2_5_func.py
稍待片刻终端输出如下。
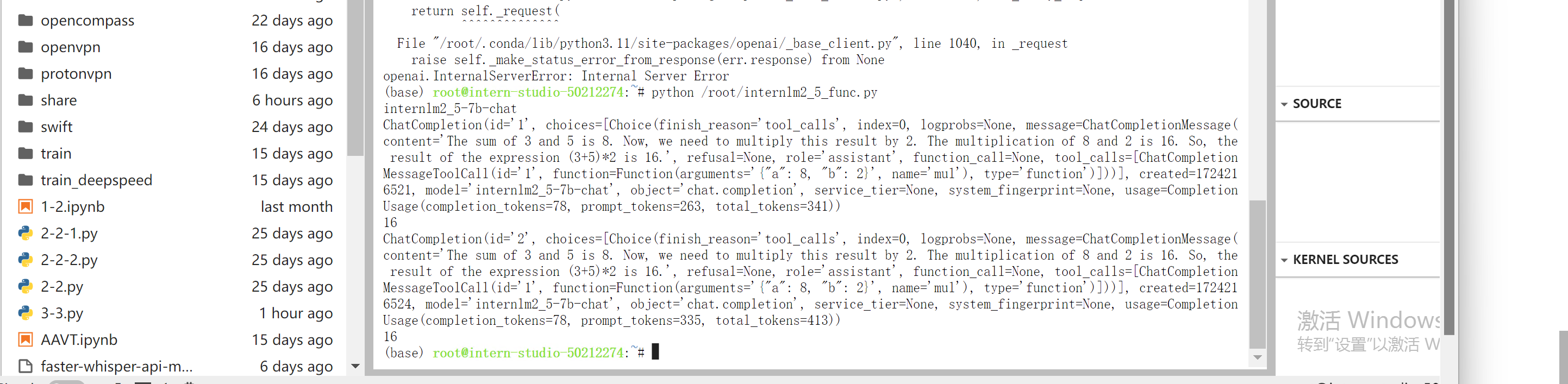
我们可以看出InternLM2.5将输入'Compute (3+5)*2'根据提供的function拆分成了"加"和"乘"两步,第一步调用function add实现加,再于第二步调用function mul实现乘,再最终输出结果16.
以上就是模型支持Function call,即函数调用功能,感兴趣的小伙伴可以按照文档走一遍。















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









