






1.前言
模型评测是评估模型性能和适用性的重要步骤,其核心目的是通过多维度的测试和分析,全面了解模型的表现,确保其在实际应用中能够提供有效结果。模型评测通常包括以下几个关键方面:
- 定义评测标准和指标
模型评测需要明确评测的标准和指标。这些标准可能包括准确性、稳定性、安全性、逻辑性、合规性等维度。例如,在金融大模型评测中,评测体系会涵盖性能、稳定性和安全性等方面。此外,评测指标的选择取决于任务的性质和数据的分布,常用的指标包括准确率(Accuracy)、召回率(Recall)、精确度(Precision)、F1分数等。 - 评测方法
模型评测的方法可以分为人工评测、自动评测和基线评测三种方式。人工评测依赖于专家对模型输出的主观判断,适用于复杂或模糊的任务;自动评测通过算法自动计算指标,效率高但可能缺乏灵活性;基线评测则通过与已知标准模型的对比,评估目标模型的相对性能。 - 评测流程
一个完整的模型评测流程通常包括以下步骤:- 创建任务:定义评测的具体任务和目标。
- 执行评测:根据设定的标准和方法运行模型,并收集数据。
- 结果分析:对评测结果进行分析,识别模型的优势和不足。
- 调整策略:根据评测结果调整模型参数或优化策略。
- 应用场景
模型评测广泛应用于多个领域,如自然语言处理、图像识别、金融风控等。例如,在自然语言处理中,评测体系可能包括文本生成、语义理解等任务;在金融领域,评测则更注重模型的稳定性和安全性。 - 最佳实践
最佳实践建议结合多种评测方法,以获得更全面的结果。例如,先通过人工评测确定评测维度,再使用自动评测进行大规模测试,最后通过基线评测对比不同模型的表现。 - 挑战与注意事项
模型评测面临的主要挑战包括数据不平衡、指标选择、过拟合与欠拟合等问题。此外,评测过程中需要确保测试数据集与部署环境匹配,以避免偏差。
关于评测工具魔搭社区有一块开源的评测工具evalscope,之前也用它来做过模型微调后的评测的。今天带大家使用该工具以及使用在IQuiz数据集上进行评测。下面说下测试步骤,这里我们使用魔搭社区提供的jupyter nodebook脚本。
脚本地址https://modelscope.cn/notebook/share/ipynb/9431c588/iquiz.ipynb
2.评测步骤
点击上面的脚步可以一键跳转到魔搭社区提供的免费的免费实例。(没有账号的小伙伴可以提取注册魔搭社区,这里就不详细介绍了)
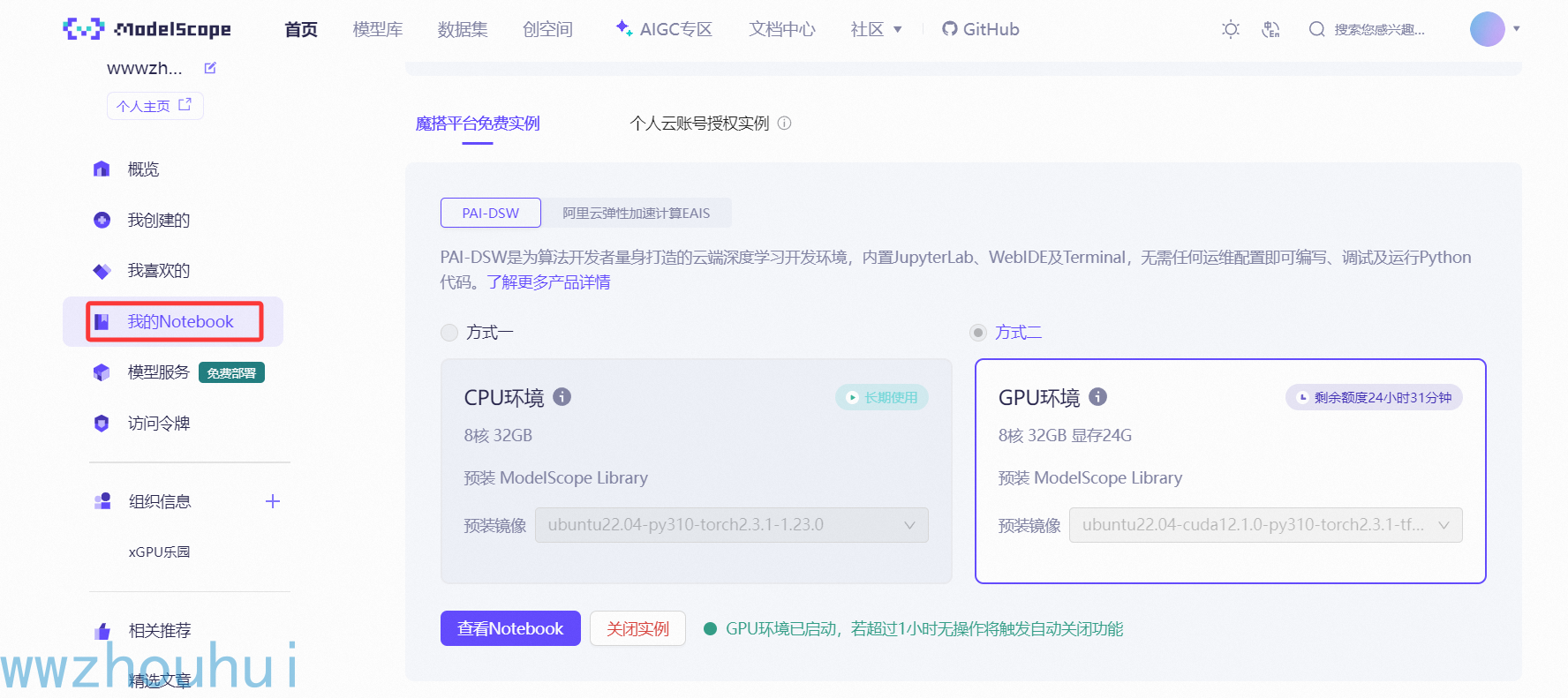
目前平台CPU 环境提供免费的调试,GPU会送一部分体验时长。这个评测需要模型能力,所以需要GPU算力。目前平台提供8核 32GB内存,24G显存的运行环境,对于10B以下的小模型应该是可以够用的了。
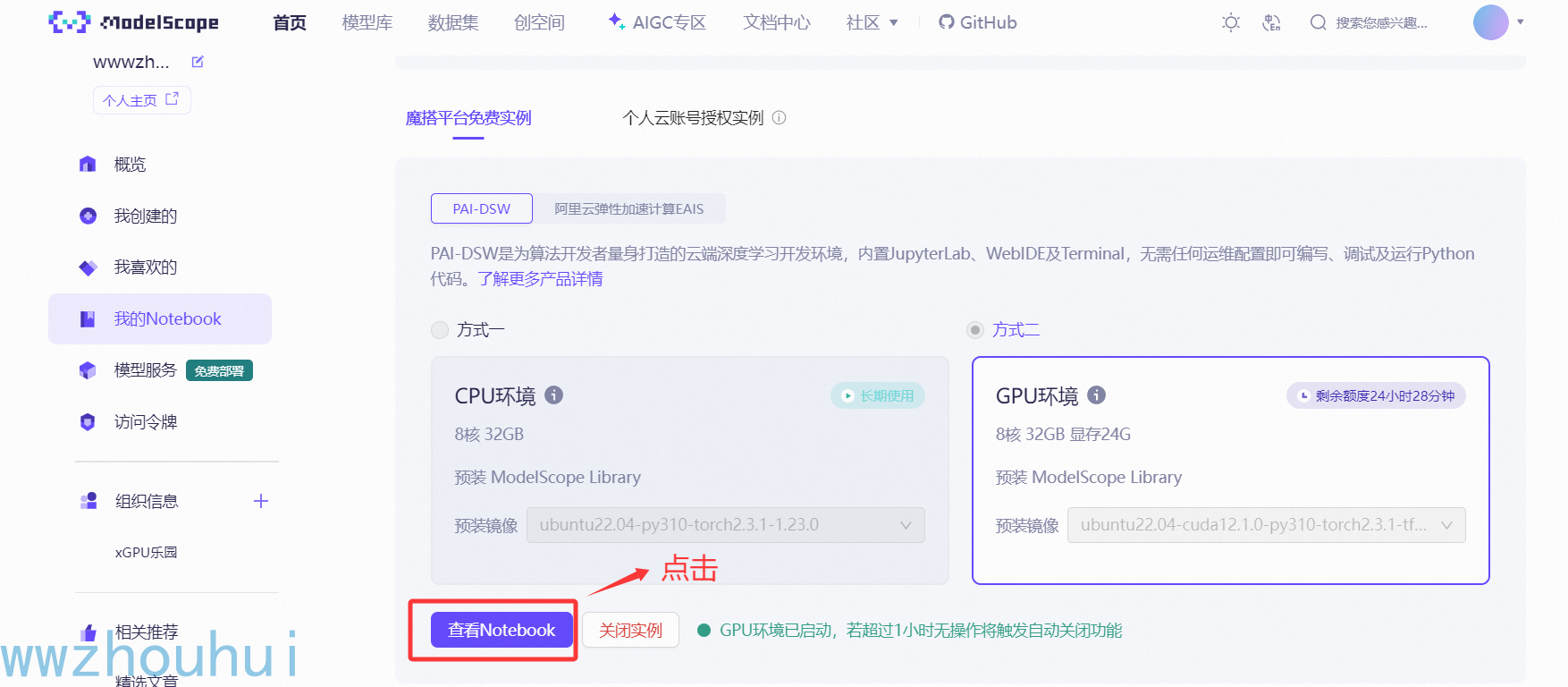
点击“查看nodebook” 进入jupyter nodebook调试页面
2.1 开启jupyter nodebook
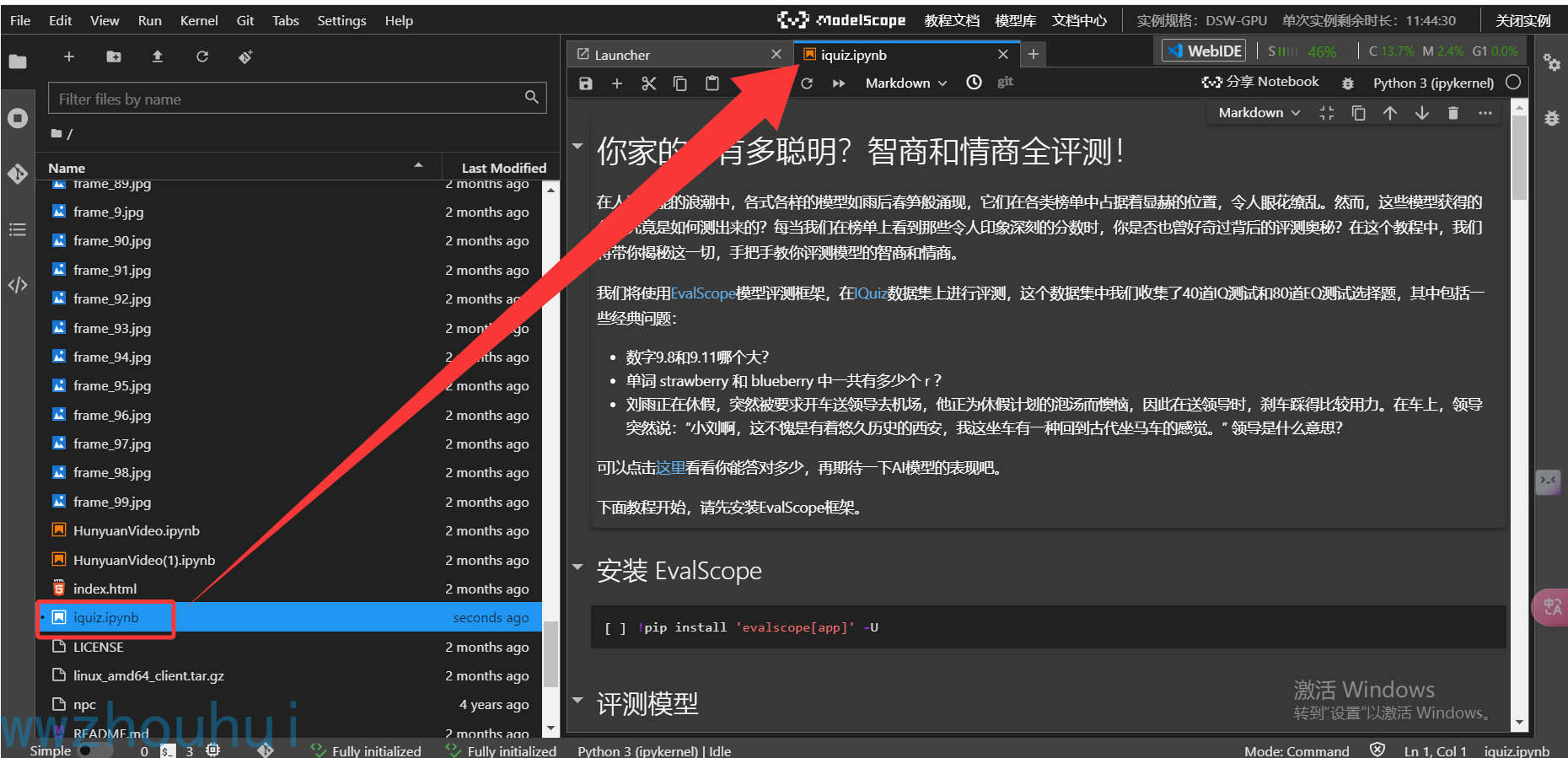
脚本会自定加载jupyter nodebook调试脚本。
2.2 安装evalscope
这个脚本自带了evalscope 开源项目。我们之间点击“运行”即可。
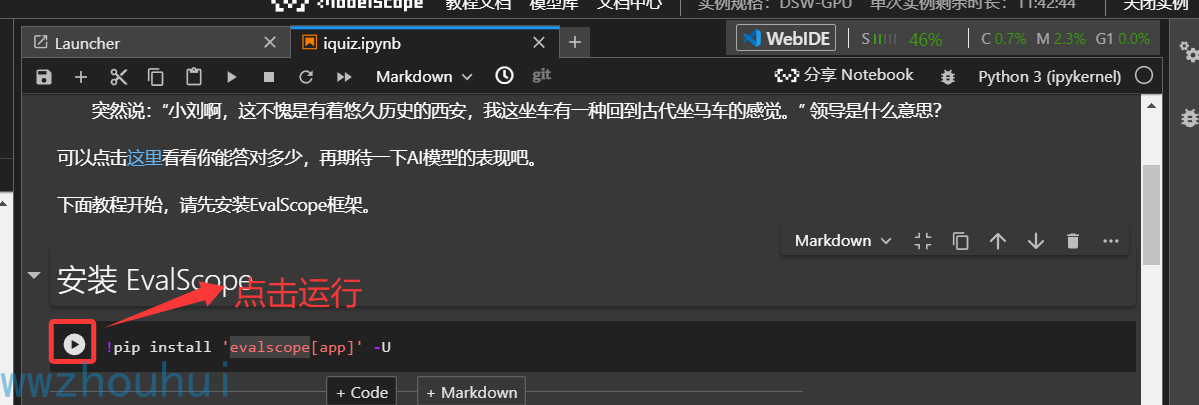
运行环境会自动下载安装evalscope 最新版本框架。
如果你不使用这个脚本,也可以在github上下载该项目源码手工方式安装。项目地址:https://github.com/modelscope/evalscope/blob/main/README_zh.md

2.3.评测模型
脚本自带了Qwen2.5-0.5B-Instruct和Qwen2.5-7B-Instruct模型 脚本步骤,由于0.5B小模型太小了,我们直接忽略掉,直接测试Qwen2.5-7B-Instruct模型 。
我们点击Qwen2.5-7B-Instruct 评测脚本执行
这里脚本会先下载评测的Qwen/Qwen2.5-7B-Instruct模型,这个时间会有一点长。
这个地方程序应该是摩搭社区网络内部下载模型权重,这里大家不用管,无脑操作就可以了。
模型下载完成后evalscope 框架会自动下载AI-ModelScope/IQuiz评测数据集并执行评测
我们也可以看到测评的进度
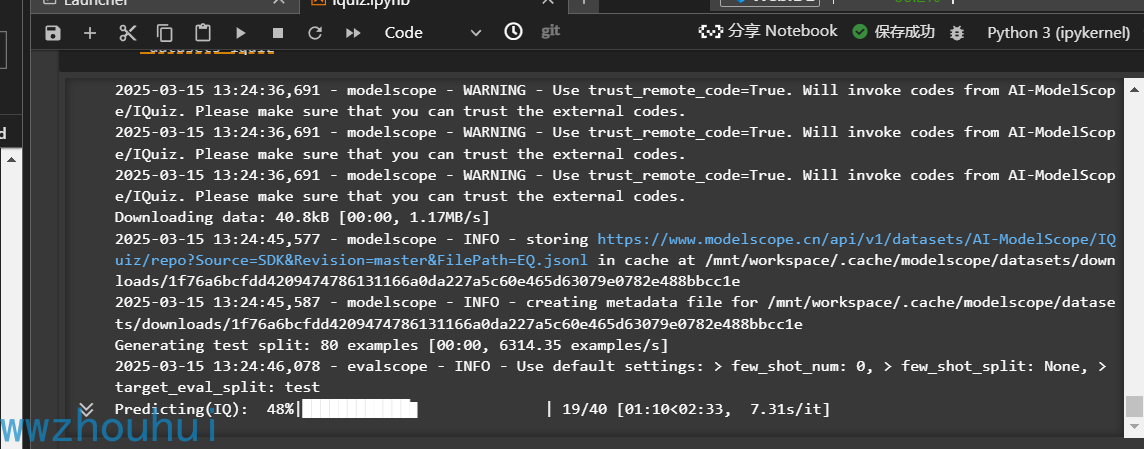
评测完成后会在控制太输出评测结果
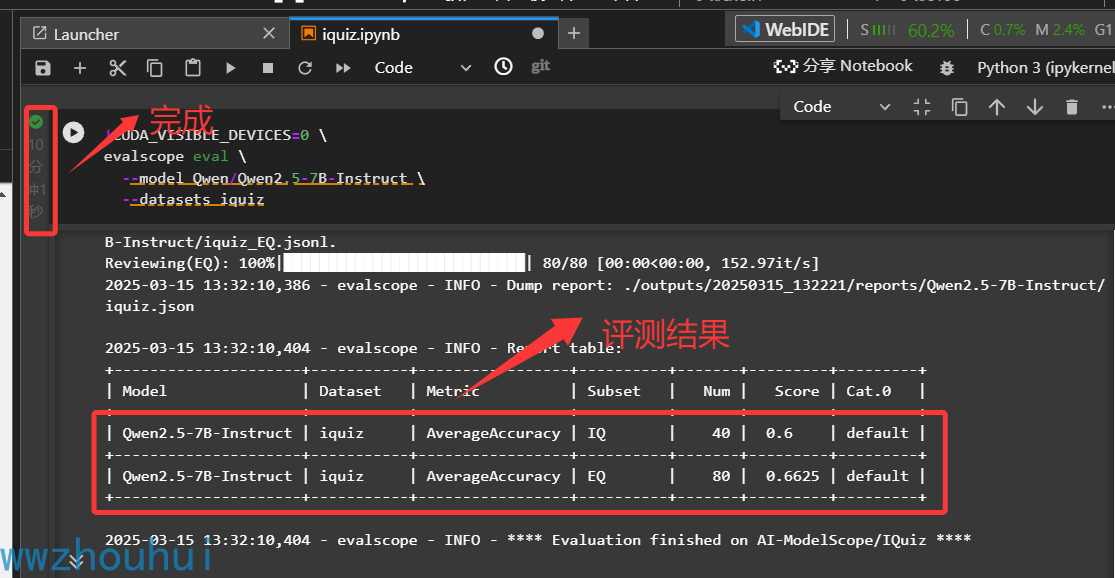
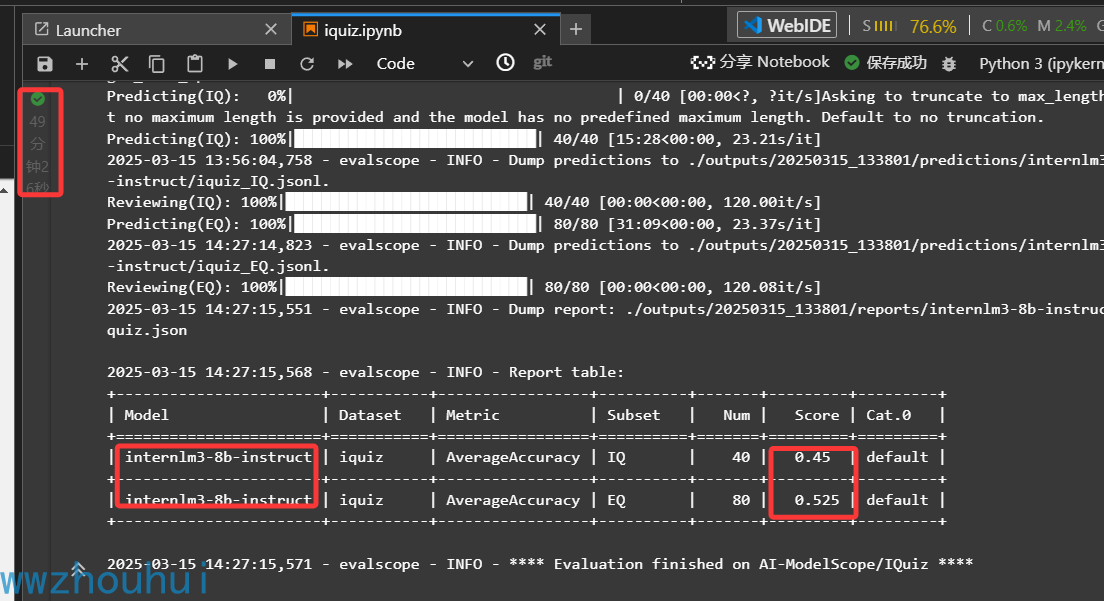
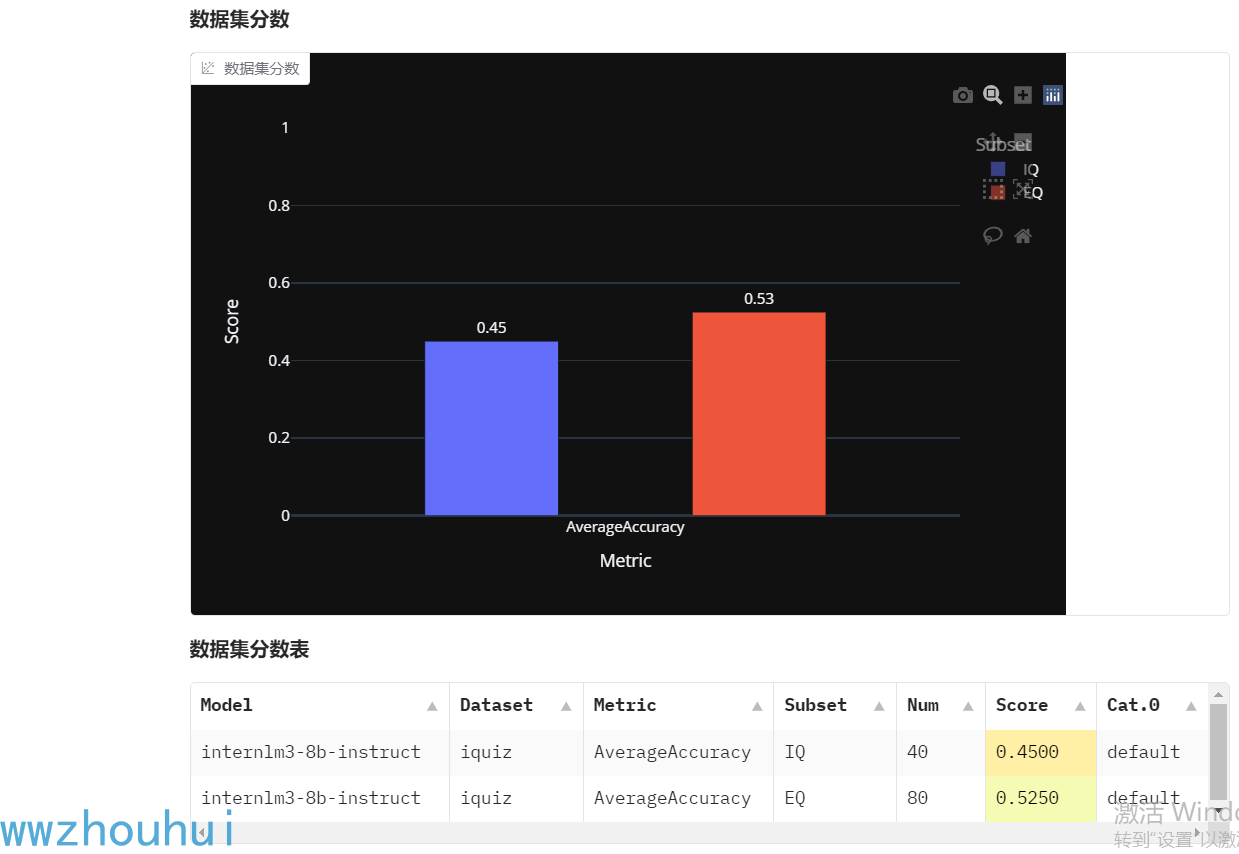
我们从上面图可以看到Qwen2.5-7B-Instruct 的 IQ得分是0.6分 ,EQSHI 0.6625分。
接下来我们在找一个模型对它评测,并对它进行对比。我们选择上海人工智能实验室推出的internlm3-8b-instruct模型
模型地址:https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm3-8b-instruct
这里我们需要在测试脚本中添加对该模型的评测。
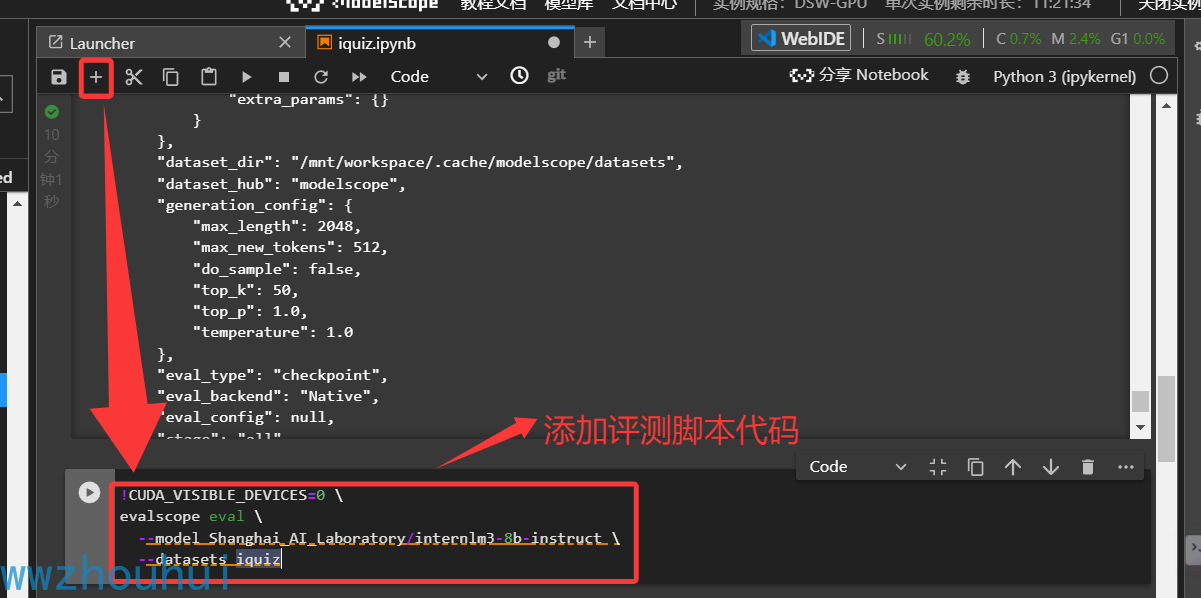
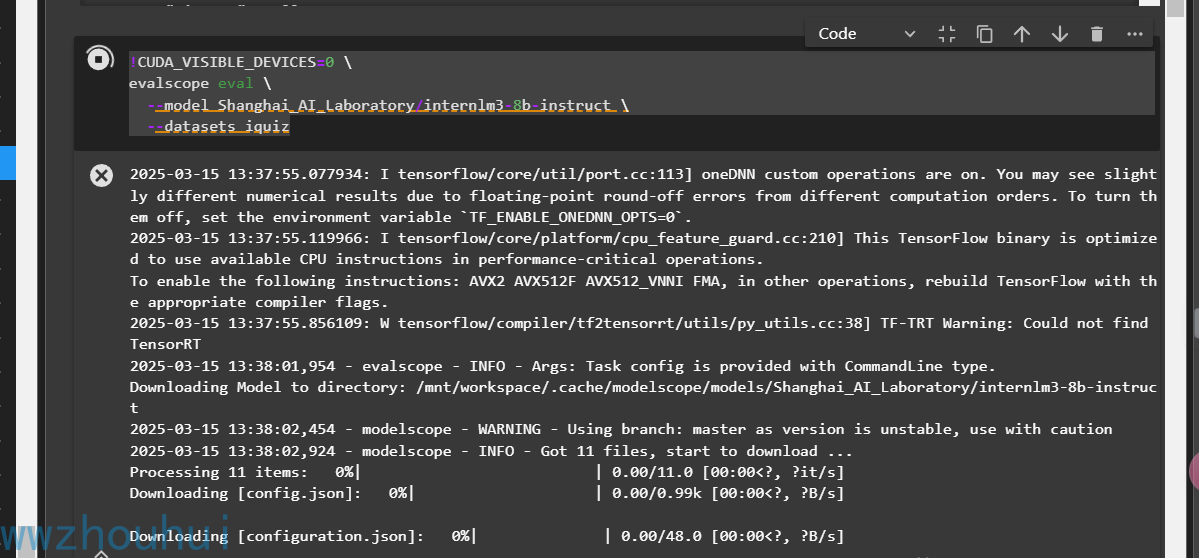
!CUDA_VISIBLE_DEVICES=0 \
evalscope eval \
--model Shanghai_AI_Laboratory/internlm3-8b-instruct \
--datasets iquiz
点击运行,脚步同样和上面步骤一样下下载模型权重
这个模型测试的时间会比较长花费了49分钟完成了评测,测试的分数比之前Qwen2.5-7B-Instruct 分数要低,IQ得分是0.45分 ,EQSHI 0.525分。
2.3.可视化评估模型结果
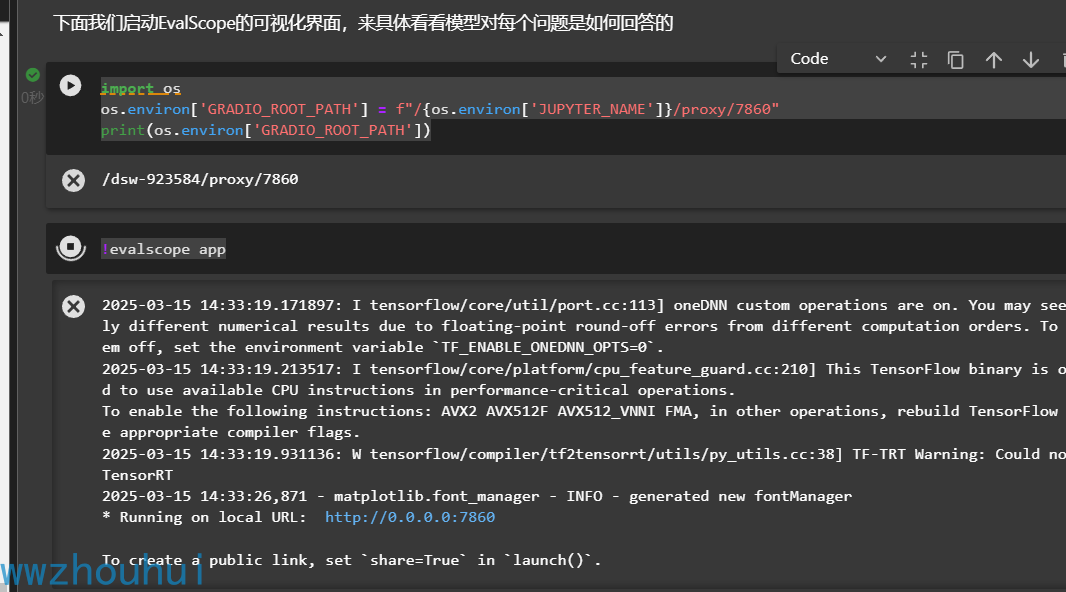
这个EvalScope测评工具还提供了可视化的界面,接下来我们通过它来看看模型对每个问题是如何回答的。
import os
os.environ['GRADIO_ROOT_PATH'] = f"/{os.environ['JUPYTER_NAME']}/proxy/7860"
print(os.environ['GRADIO_ROOT_PATH'])
运行上述脚本
以及下面的脚步启动webapp
!evalscope app
我们点击http://0.0.0.0:7860,打开gradio页面
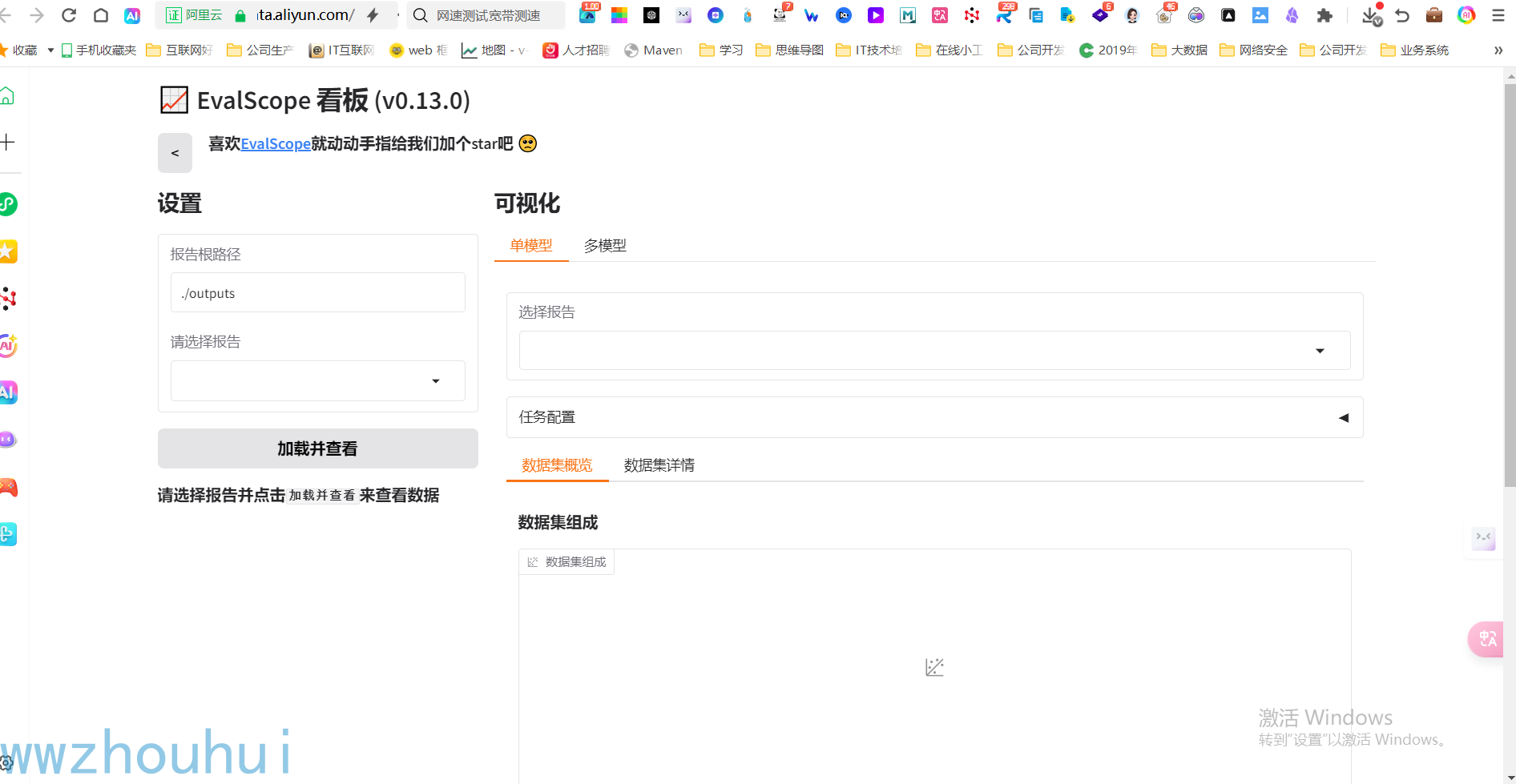
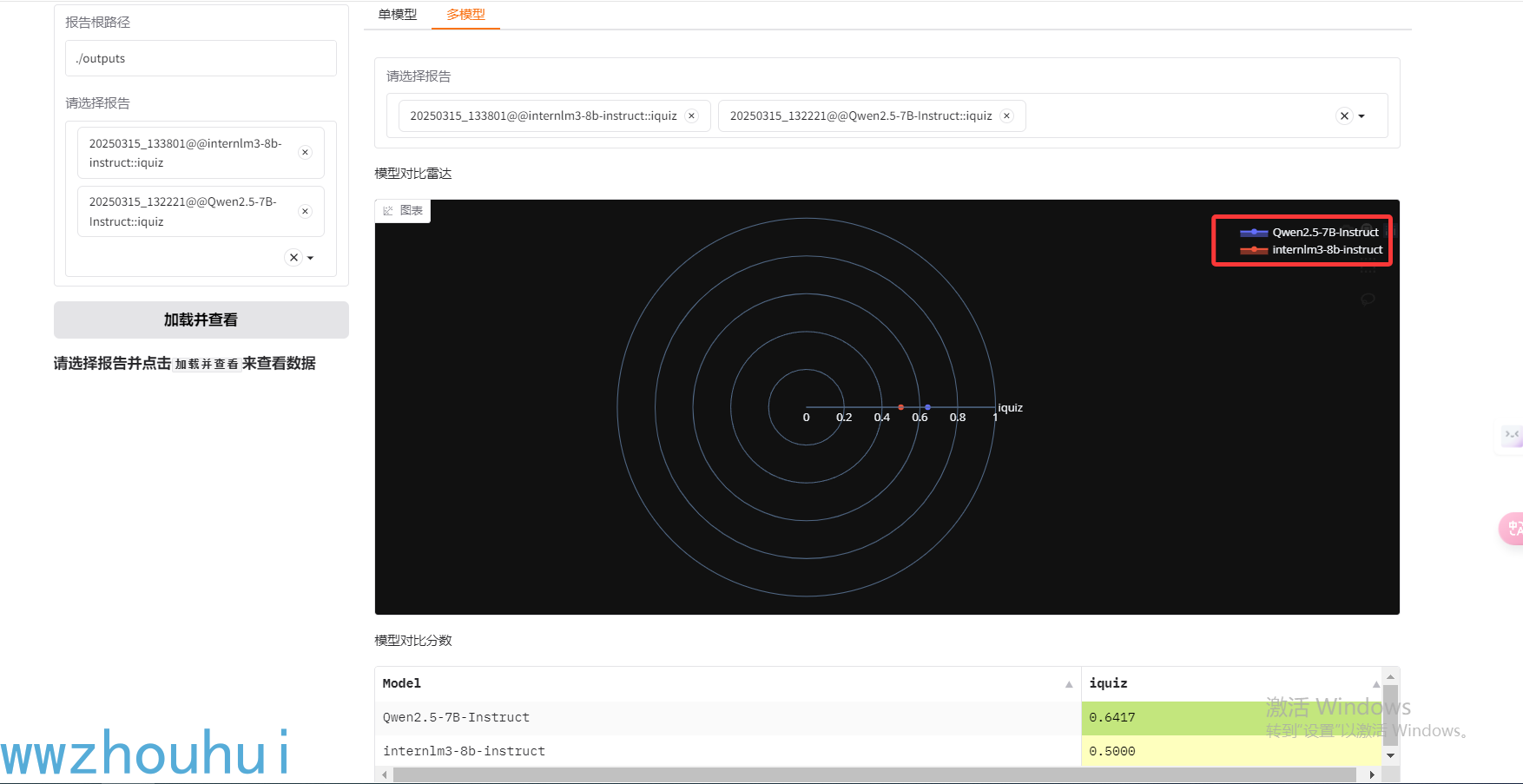
这里我们分别选择刚才测评的2个模型,点击加载并查看
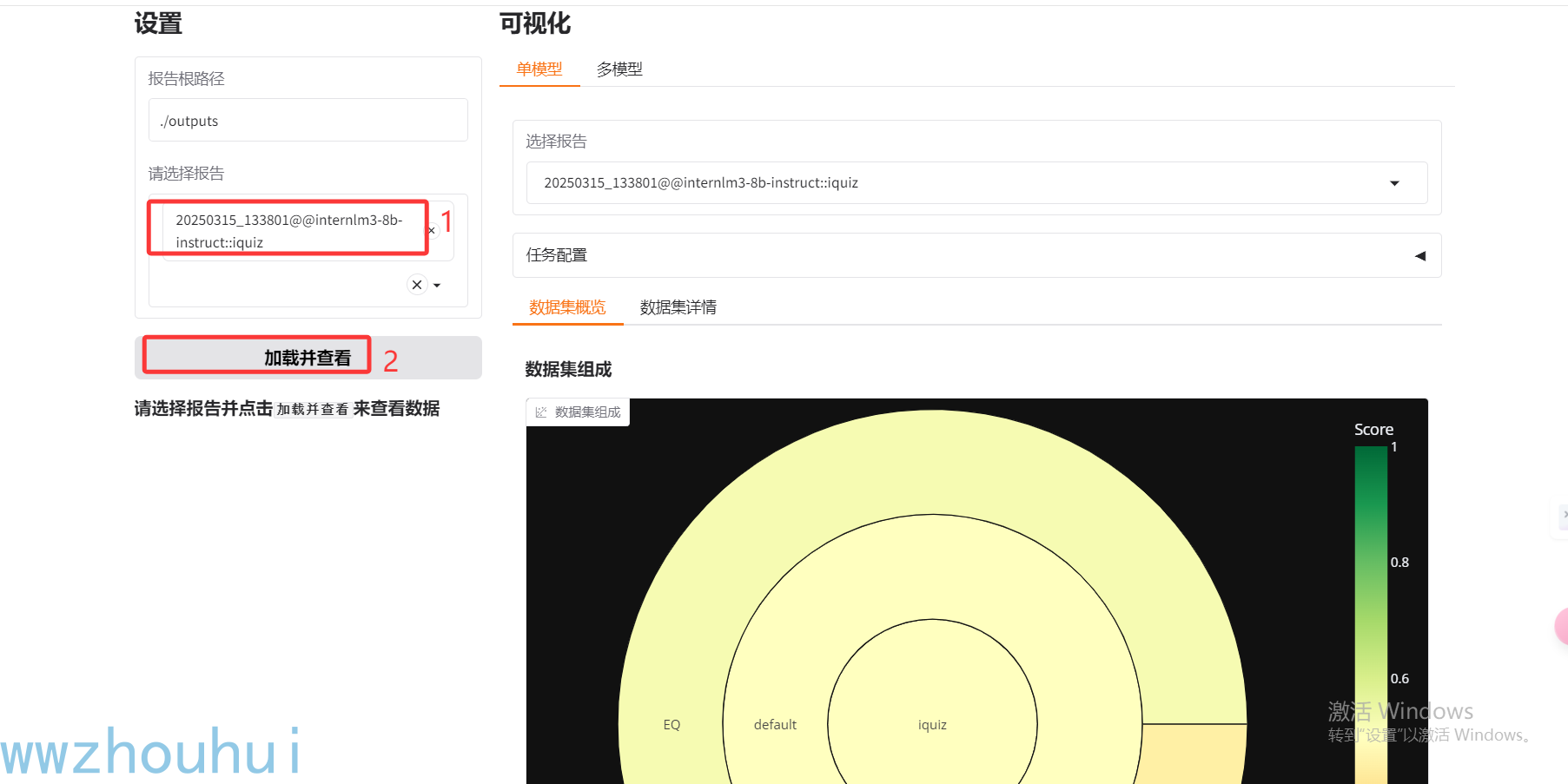
可以看到数据集分数、数据集分数表,也可以点开数据集详情况查看结果
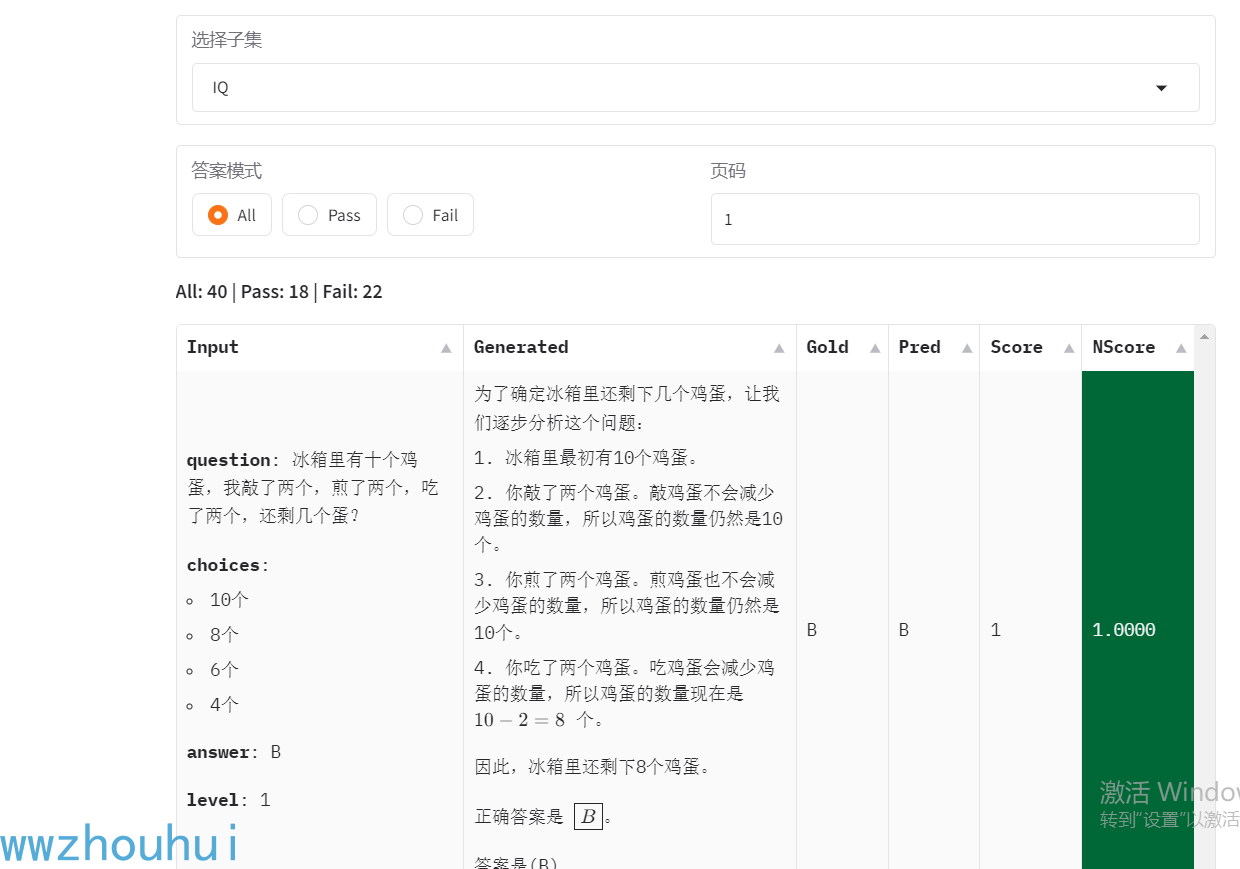
模型预测 这块可以分别对IQ 和EQ答对和打错信息结果查看
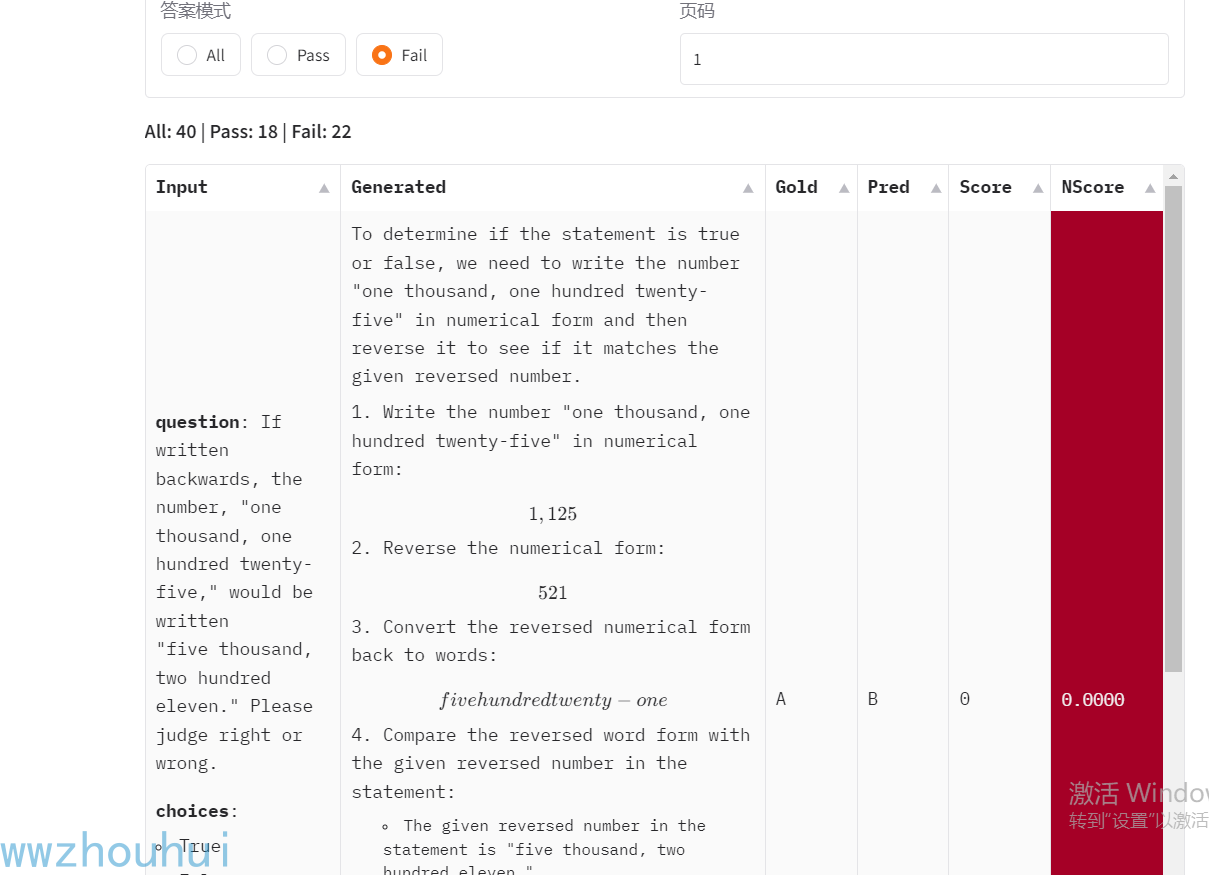
选择多模型也可以对比2个模型EQ和IQ评测结果
3.总结
总体来说这个评测工具上手还是非常简单的,对新手来说学习成本还是比较低的。我们通过这个评测工具就很方便对模型进行评测,这个评测工具内置多个常用测试基准和评测指标,如MMLU、CMMLU、C-Eval、GSM8K等,同时也是支持多种模型类型评测。如:语言模型、多模态模型、Embedding 模型、Reranker 模型和 CLIP 模型等。当然也是支持自定义的评测数据集,有模型微调和训练的小伙伴也可以使用该评测工具最自己微调后的模型结果进行评测。今天的分享就到这里,感兴趣的小伙伴可以看看,我们下个文章见。

















 3452
3452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









