






DeepSeek性能测试
EvalScope是魔搭社区官方推出的模型评测与性能基准测试框架,内置多个常用测试基准和评测指标,如MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH和HumanEval等;支持多种类型的模型评测,包括LLM、多模态LLM、embedding模型和reranker模型。EvalScope还适用于多种评测场景,如端到端RAG评测、竞技场模式和模型推理性能压测等。此外,通过ms-swift训练框架的无缝集成,可一键发起评测,实现了模型训练到评测的全链路支持。
整体架构
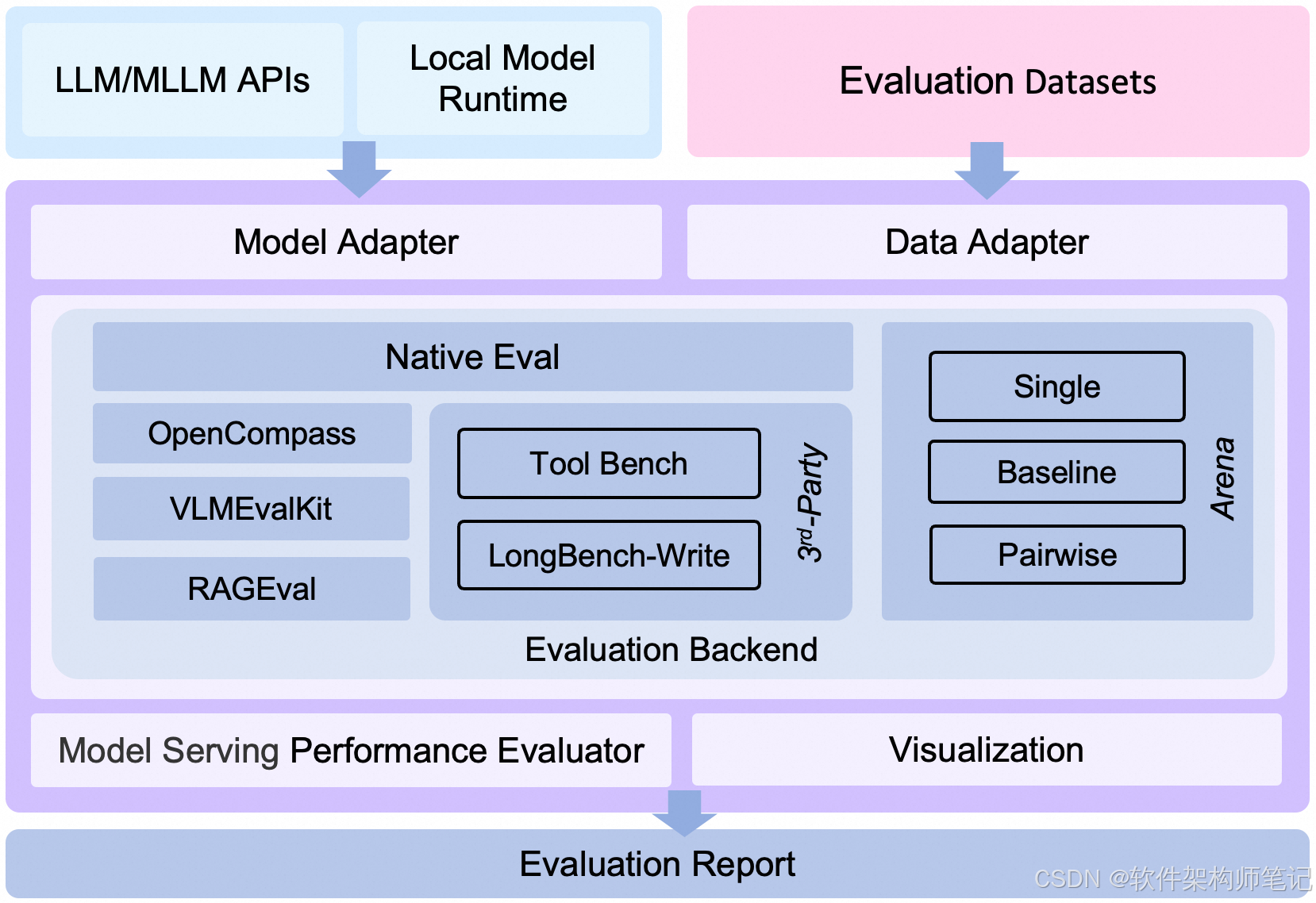
EvalScope 架构图.
包括以下模块:
-
Model Adapter: 模型适配器,用于将特定模型的输出转换为框架所需的格式,支持API调用的模型和本地运行的模型。
-
Data Adapter: 数据适配器,负责转换和处理输入数据,以便适应不同的评测需求和格式。
-
Evaluation Backend:
- Native:EvalScope自身的默认评测框架,支持多种评测模式,包括单模型评测、竞技场模式、Baseline模型对比模式等。
- OpenCompass:支持OpenCompass作为评测后端,对其进行了高级封装和任务简化,您可以更轻松地提交任务进行评测。
- VLMEvalKit:支持VLMEvalKit作为评测后端,轻松发起多模态评测任务,支持多种多模态模型和数据集。
- ThirdParty:其他第三方评测任务,如ToolBench。
- RAGEval:支持RAG评测,支持使用MTEB/CMTEB进行embedding模型和reranker的独立评测,以及使用RAGAS进行端到端评测。
-
Performance Evaluator: 模型性能评测,负责具体衡量模型推理服务性能,包括性能评测、压力测试、性能评测报告生成、可视化。
-
Evaluation Report: 最终生成的评测报告,总结模型的性能表现,报告可以用于决策和进一步的模型优化。
-
Visualization: 可视化结果,帮助用户更直观地理解评测结果,便于分析和比较不同模型的表现。
框架特点
- 基准数据集:预置了多个常用测试基准,包括:MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval等。
- 评测指标:实现了多种常用评测指标。
- 模型接入:统一的模型接入机制,兼容多个系列模型的Generate、Chat接口。
- 自动评测:包括客观题自动评测和使用专家模型进行的复杂任务评测。
- 评测报告:自动生成评测报告。
- 竞技场(Arena)模式:用于模型间的比较以及模型的客观评测,支持多种评测模式,包括:
- Single mode:对单个模型进行评分。
- Pairwise-baseline mode:与基线模型进行对比。
- Pairwise (all) mode:所有模型间的两两对比。
- 可视化工具:提供直观的评测结果展示。
- 模型性能评测:提供模型推理服务压测工具和详细统计,详见模型性能评测文档。
- OpenCompass集成:支持OpenCompass作为评测后端,对其进行了高级封装和任务简化,您可以更轻松地提交任务进行评测。
- VLMEvalKit集成:支持VLMEvalKit作为评测后端,轻松发起多模态评测任务,支持多种多模态模型和数据集。
- 全链路支持:通过与ms-swift训练框架的无缝集成,实现模型训练、模型部署、模型评测、评测报告查看的一站式开发流程,提升用户的开发效率。
测试指令
32B 1卡1并发:32b-1-1
evalscope perf \
--parallel 1 \
--url http://127.0.0.1:11434/v1/chat/completions \
--model deepseek-r1:32b \
--log-every-n-query 5 \
--connect-timeout 6000 \
--read-timeout 6000 \
--max-tokens 2048 \
--min-tokens 512 \
--api openai \
--debug \
--number 80 \
--dataset openqa \
--name 'deepseek-r1:32b-1-1'
32B 1卡5并发:32b-1-5
evalscope perf \
--parallel 5 \
--url http://127.0.0.1:11434/v1/chat/completions \
--model deepseek-r1:32b \
--log-every-n-query 5 \
--connect-timeout 6000 \
--read-timeout 6000 \
--max-tokens 2048 \
--min-tokens 512 \
--api openai \
--debug \
--number 80 \
--dataset openqa \
--name 'deepseek-r1:32b-1-5'
32B 1卡10并发:32b-1-10
evalscope perf \
--parallel 10 \
--url http://127.0.0.1:11434/v1/chat/completions \
--model deepseek-r1:32b \
--log-every-n-query 5 \
--connect-timeout 6000 \
--read-timeout 6000 \
--max-tokens 2048 \
--min-tokens 512 \
--api openai \
--debug \
--number 80 \
--dataset openqa \
--name 'deepseek-r1:32b-1-10'
32B 2卡1并发:32b-2-1
evalscope perf \
--parallel 1 \
--url http://127.0.0.1:11434/v1/chat/completions \
--model deepseek-r1:32b \
--log-every-n-query 1 \
--connect-timeout 6000 \
--read-timeout 6000 \
--max-tokens 2048 \
--min-tokens 512 \
--api openai \
--debug \
--number 80 \
--dataset openqa \
--name 'deepseek-r1:32b-2-1'
32B 2卡5并发:32b-2-5
evalscope perf \
--parallel 5 \
--url http://127.0.0.1:11434/v1/chat/completions \
--model deepseek-r1:32b \
--log-every-n-query 5 \
--connect-timeout 6000 \
--read-timeout 6000 \
--max-tokens 2048 \
--min-tokens 512 \
--api openai \
--debug \
--number 80 \
--dataset openqa \
--name 'deepseek-r1:32b-2-5'
测试结果
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Key | 32b-1-1 | 32b-1-5 | 32b-1-10 | 32b-2-1 |32b-2-5 |
+===================================+==========+=============+===========+===========+===========+
| Time taken for tests (s) | 1921.774 | 578.334 | 612.153 | 1539.471 |533.021 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Number of concurrency | 1 | 5 | 10 | 1 |5 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Total requests | 80 | 80 | 80 | 80 |80 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Succeed requests | 80 | 80 | 80 | 80 |80 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Failed requests | 0 | 0 | 0 | 0 |0 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Throughput(average tokens/s) | 30.479 | 95.02 | 93.049 | 37.487 |104.608 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average QPS | 0.042 | 0.138 | 0.131 | 0.052 |0.15 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average latency (s) | 24.019 | 34.707 | 71.745 | 19.24 |31.977 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average time to first token (s) | 24.019 | 34.707 | 71.745 | 19.24 |31.977 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average time per output token (s) | 0.033 | 0.066 | 0.201 | 0.027 |0.061 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average input tokens per request | 24.2 | 24.2 | 24.2 | 24.2 |24.2 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average output tokens per request | 732.163 | 686.913 | 712.0 | 721.375 |696.975 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average package latency (s) | 24.019 | 34.707 | 71.745 | 19.24 |31.977 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Average package per request | 1.0 | 1.0 | 1.0 | 1.0 |1.0 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
| Expected number of requests | 80 | 80 | 80 | 80 |80 |
+-----------------------------------+----------+-------------+-----------+-----------+-----------+
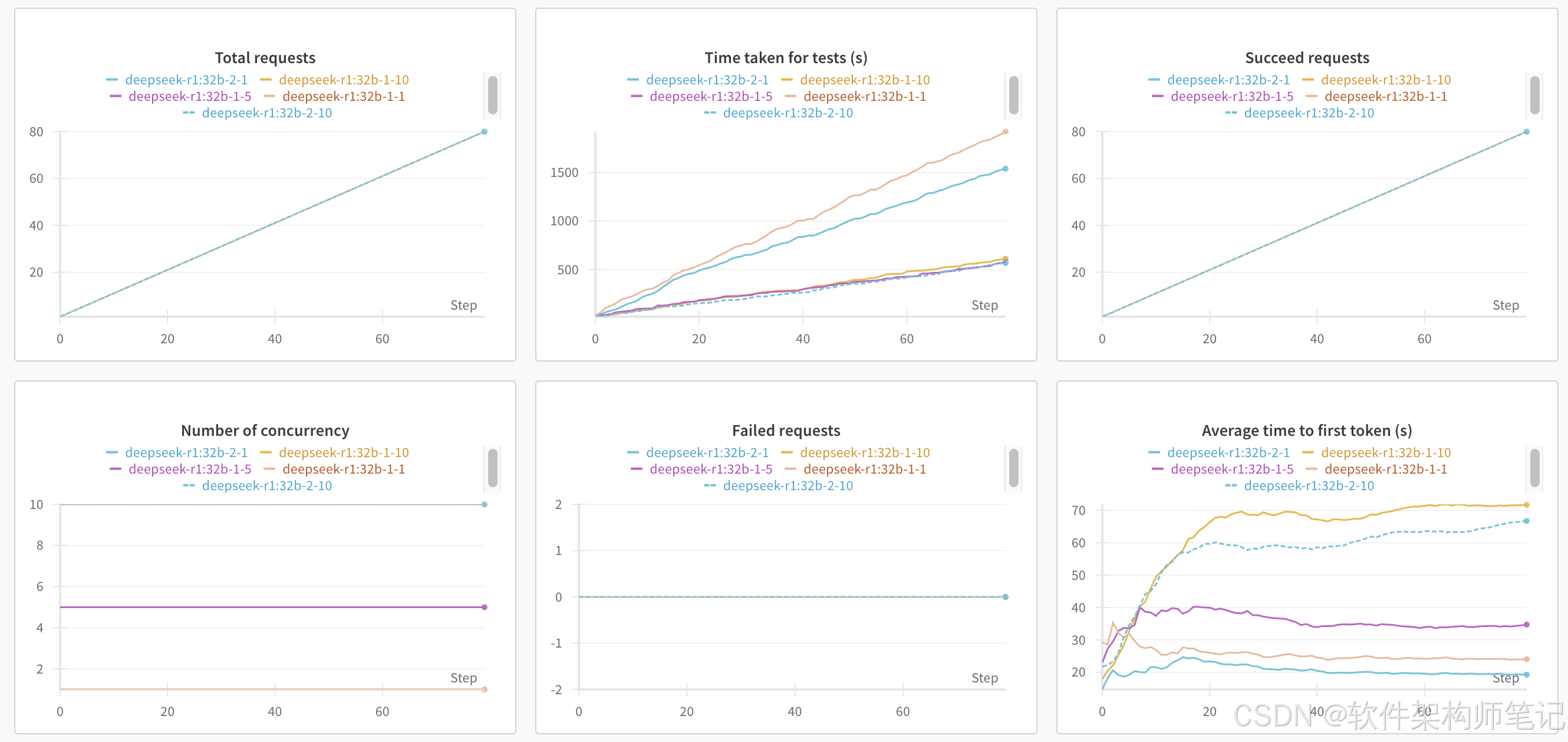
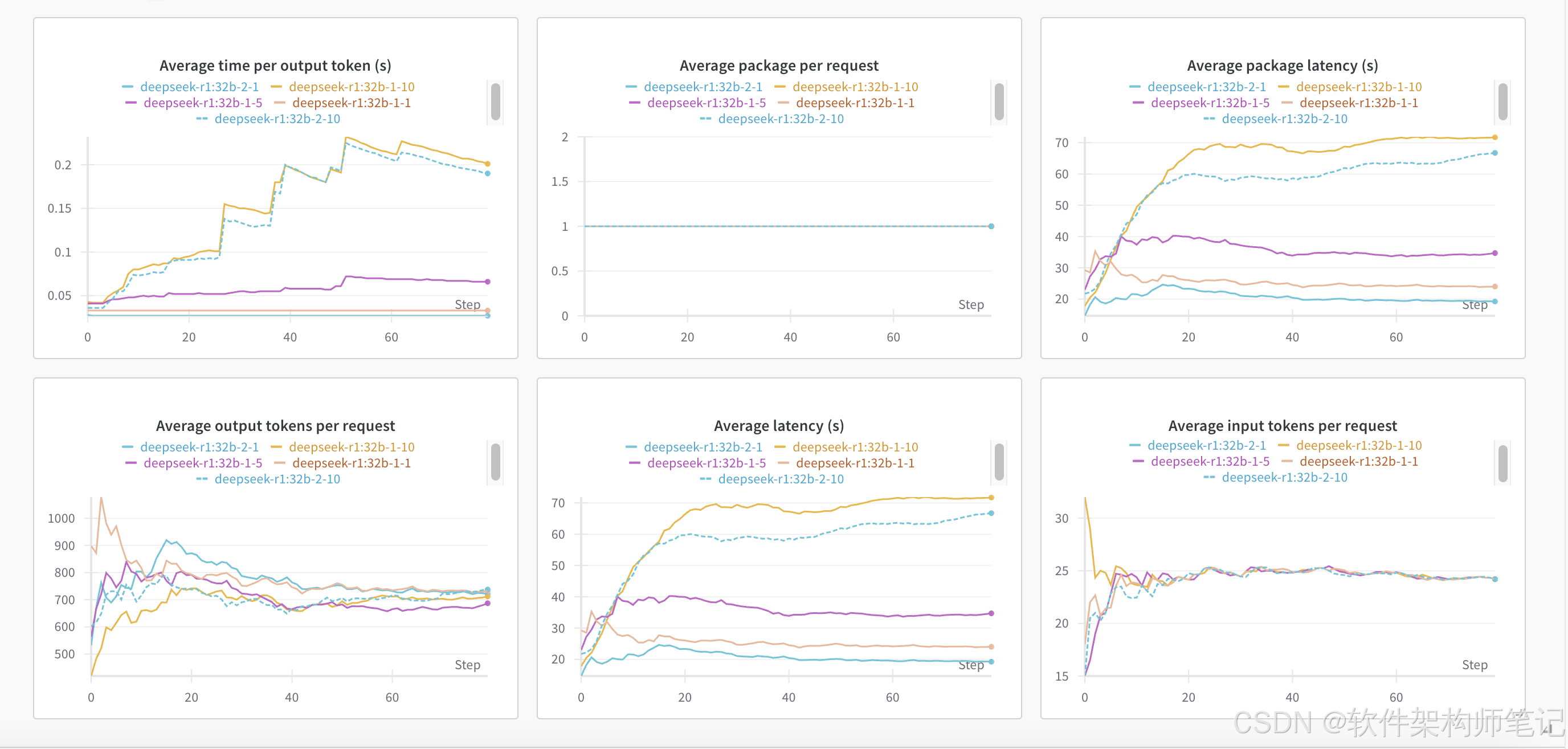
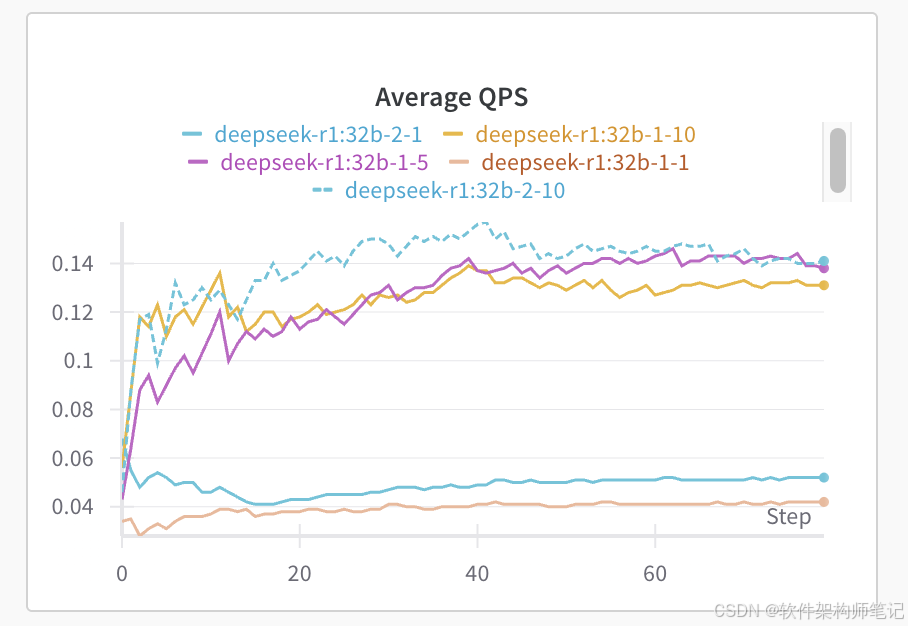
性能测试工具evalscope
安装
- 创建 conda 环境(可选)
# It is recommended to use Python 3.10
conda create -n evalscope python=3.10
# Activate the conda environment
conda activate evalscope
- 使用 pip 安装依赖项
pip install evalscope # Install Native backend (default)
# Additional options
pip install evalscope[opencompass] # Install OpenCompass backend
pip install evalscope[vlmeval] # Install VLMEvalKit backend
pip install evalscope[rag] # Install RAGEval backend
pip install evalscope[perf] # Install Perf dependencies
pip install evalscope[all] # Install all backends (Native, OpenCompass, VLMEvalKit, RAGEval)
基准测试可视化
安装
pip install 'evalscope[app]'
evalscope app --server-port 28888
访问地址
http://127.0.0.1:28888/
基准测试指令
evalscope eval \
--model deepseek-r1:32b \
--api-url http://127.0.0.1:11434/v1 \
--api-key EMPTY \
--eval-type service \
--datasets gsm8k \
--limit 10
基准测试结果
+-----------------+-----------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=================+===========+=================+==========+=======+=========+=========+
| deepseek-r1:32b | gsm8k | AverageAccuracy | main | 10 | 0.9 | default |
+-----------------+-----------+-----------------+----------+-------+---------+---------+
性能测试可视化wandb
安装
pip install wandb
本地启动参数
wandb server start -e HOST=http://127.0.0.1:8080 --wandb-api-key 'wandb_api_key' --name 'name_of_wandb_log'
远端看板地址
https://wandb.ai/
参数说明
--number 发出的请求的总数量;默认为None,表示基于数据集数量发送请求。
--parallel 并发请求的数量,默认为1。
--log-every-n-query 每n个查询记录日志,默认为10。
--stream 使用SSE流输出,默认为False。
--connect-timeout 网络连接超时,默认为120s。
--read-timeout 网络读取超时,默认为120s。
--max-tokens 可以生成的最大token数量。
--min-tokens 生成的最少token数量。
--seed 随机种子,默认为42。
--temperature 采样温度。
--url 指定API地址。
--name wandb数据库结果名称和结果数据库名称,默认为: {model_name}_{current_time},可选。
--api 指定服务API,目前支持[openai|dashscope|local|local_vllm]。
指定为openai,则使用支持OpenAI的API,需要提供--url参数。
指定为local,则使用本地文件作为模型,并使用transformers进行推理。--model为模型文件路径,也可为model_id,将自动从modelscope下载模型,例如Qwen/Qwen2.5-0.5B-Instruct。
指定为local_vllm,则使用本地文件作为模型,并启动vllm推理服务。--model为模型文件路径,也可为model_id,将自动从modelscope下载模型,例如Qwen/Qwen2.5-0.5B-Instruct。
指标说明
| 指标 | 说明 |
|---|---|
| Time taken for tests (s) | 测试所用的时间(秒) |
| Number of concurrency | 并发数量 |
| Total requests | 总请求数 |
| Succeed requests | 成功的请求数 |
| Failed requests | 失败的请求数 |
| Throughput(average tokens/s) | 吞吐量(平均每秒处理的token数) |
| Average QPS | 平均每秒请求数(Queries Per Second) |
| Average latency (s) | 平均延迟时间(秒) |
| Average time to first token (s) | 平均首次token时间(秒) |
| Average time per output token (s) | 平均每个输出token的时间(秒) |
| Average input tokens per request | 每个请求的平均输入token数 |
| Average output tokens per request | 每个请求的平均输出token数 |
| Average package latency (s) | 平均包延迟时间(秒) |
| Average package per request | 每个请求的平均包数 |
| Expected number of requests | 预期的请求数 |
| Result DB path | 结果数据库路径 |
| Percentile | 数据被分为100个相等部分,第n百分位表示n%的数据点在此值之下 |
| TTFT (s) | Time to First Token,首次生成token的时间 |
| TPOT (s) | Time Per Output Token,生成每个输出token的时间 |
| Latency (s) | 延迟时间,指请求到响应之间的时间 |
| Input tokens | 输入的token数量 |
| Output tokens | 输出的token数量 |
| Throughput (tokens/s) | 吞吐量,指每秒处理token的数量 |



















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











