







原文转自:从视频到 PPT:AI 工具如何让内容整理变得如此简单?
前几天,有个朋友跟我说:“我手上有一批培训视频,可我实在没空看。有没有什么办法能把视频内容的语音总结一下,变成文章或者 PPT,这样我就能快速浏览一下重点呢?”我一听,这事儿挺有意思的,就琢磨开了。结合 AI 技术能轻松实现批量化处理,今天就来跟大家分享一下。

1、文章整理总结
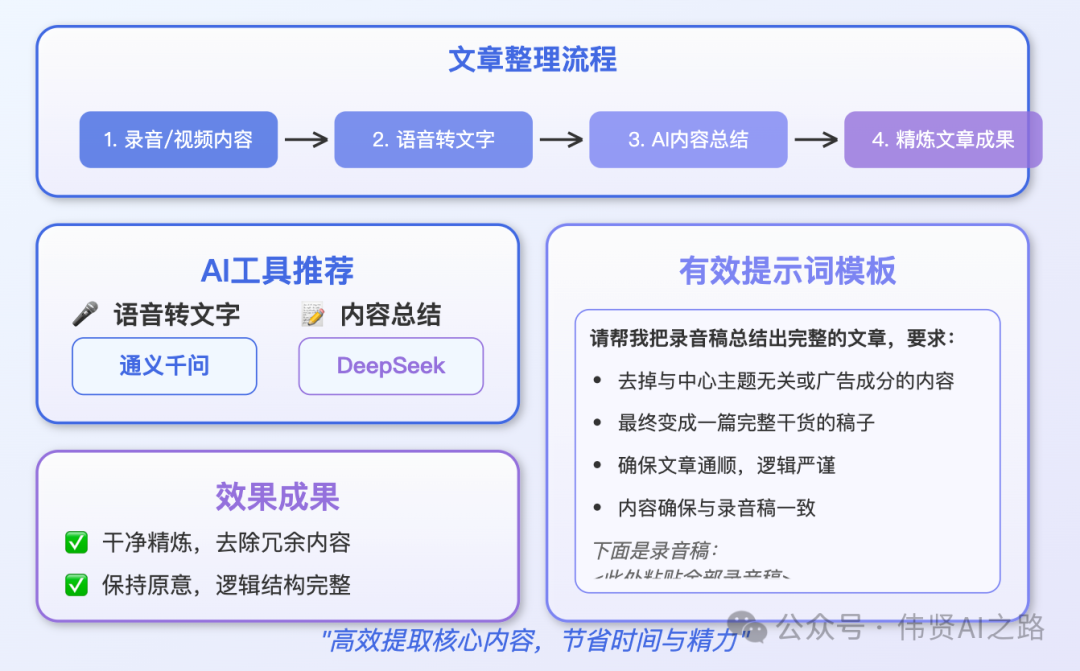
先来说说文章整理的事。咱们可以用像通义千问那样的音视频速读功能,把录音变成文字稿。我试过好几个工具,发现 DeepSeek 总结得最好。所以,直接把录音稿扔给 DeepSeek,让它帮忙总结。
我有个提示词,大家可以参考一下:
请帮我把录音稿总结出完整的文章,去掉与中心主题无关或广告成分的内容,最终变成一篇完整干货的稿子,需要确保文章通顺,逻辑严谨,内容确保与录音稿一致。下面是录音稿:<此处粘贴全部录音稿>
这样就能轻松搞定一篇干干净净的文章,全是干货,没多余的东西。
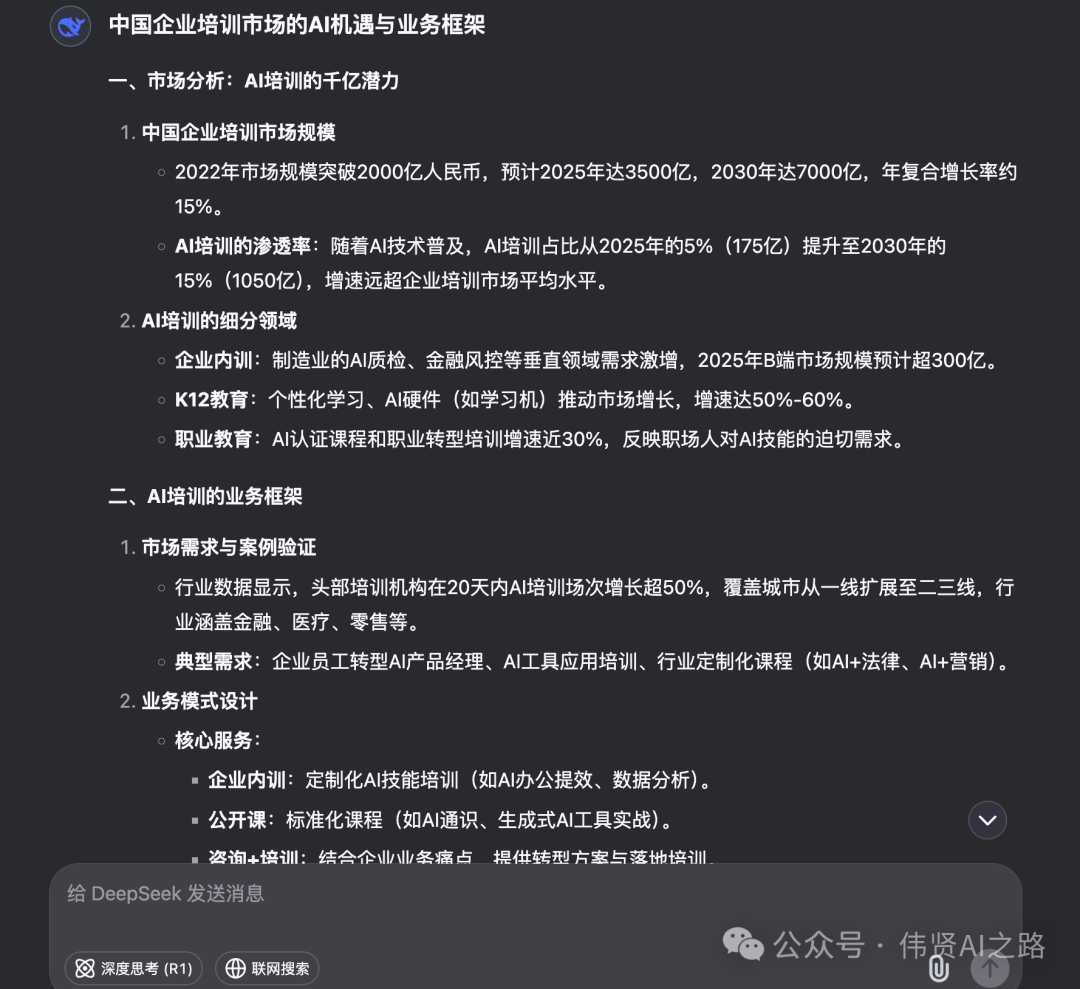
2、转化为结构化大纲
接下来,要把它变成结构化的 PPT 大纲。同样还是使用 DeepSeek 把长篇文章提炼成适合 Marp 用的 PPT 结构化内容。
下面是我使用的提示词,大家可以参考一下:
你是一位专业教学设计师,擅长将长篇文章提炼成适合Marp的PPT结构化内容。请严格遵循以下规则处理:---### **核心任务**将输入的完整课程文章转换为**Marp兼容的Markdown格式**,要求:1. **信息提炼**:提取核心论点,删除冗余解释2. **逻辑分页**:每个二级标题模块必须独立成页3. **Marp语法**:正确使用分页符和图片占位---### **Marp格式规范**```# 课程标题(自动提取关键词生成)<!-- 首页自动生成 -->---## 模块1标题![模块1相关图片]● 核心论点- 关键证据1- 关键证据2---## 模块2标题1. 第一步2. 第二步3. 第三步![流程图示意]```---### **关键规则**1. **分页控制**:- 每个`## 二级标题`前必须加`---`分页符- 标题与内容之间空一行- 图片独占一行(不嵌入列表)2. **内容处理**:- 将长段落拆分为`●`论点 + `-`论据- 流程性内容用`1. 2. 3.`编号- 保留硬数据(如"准确率提升15%")3. **视觉优化**:- 每个模块开头插入`![图片描述]`占位- 复杂概念旁添加图片提示(如`![神经网络结构图]`)---### **禁止项**❌ 三级及以上标题❌ 未分页的连续内容❌ 代码块包裹标记(```)❌ "谢谢观看"等非内容元素---### **示例对比**[输入文章]"卷积神经网络(CNN)包含卷积层、池化层和全连接层。其中卷积层通过滤波器提取特征..."[输出格式]```# 深度学习核心模型---## 卷积神经网络结构![CNN架构示意图]● 核心组件- 卷积层(特征提取)- 池化层(降维)- 全连接层(分类)---## 训练流程1. 前向传播2. 损失计算3. 反向传播![训练过程图]```请处理以下课程文章:{{course_article}}
最终生成的大纲如下:
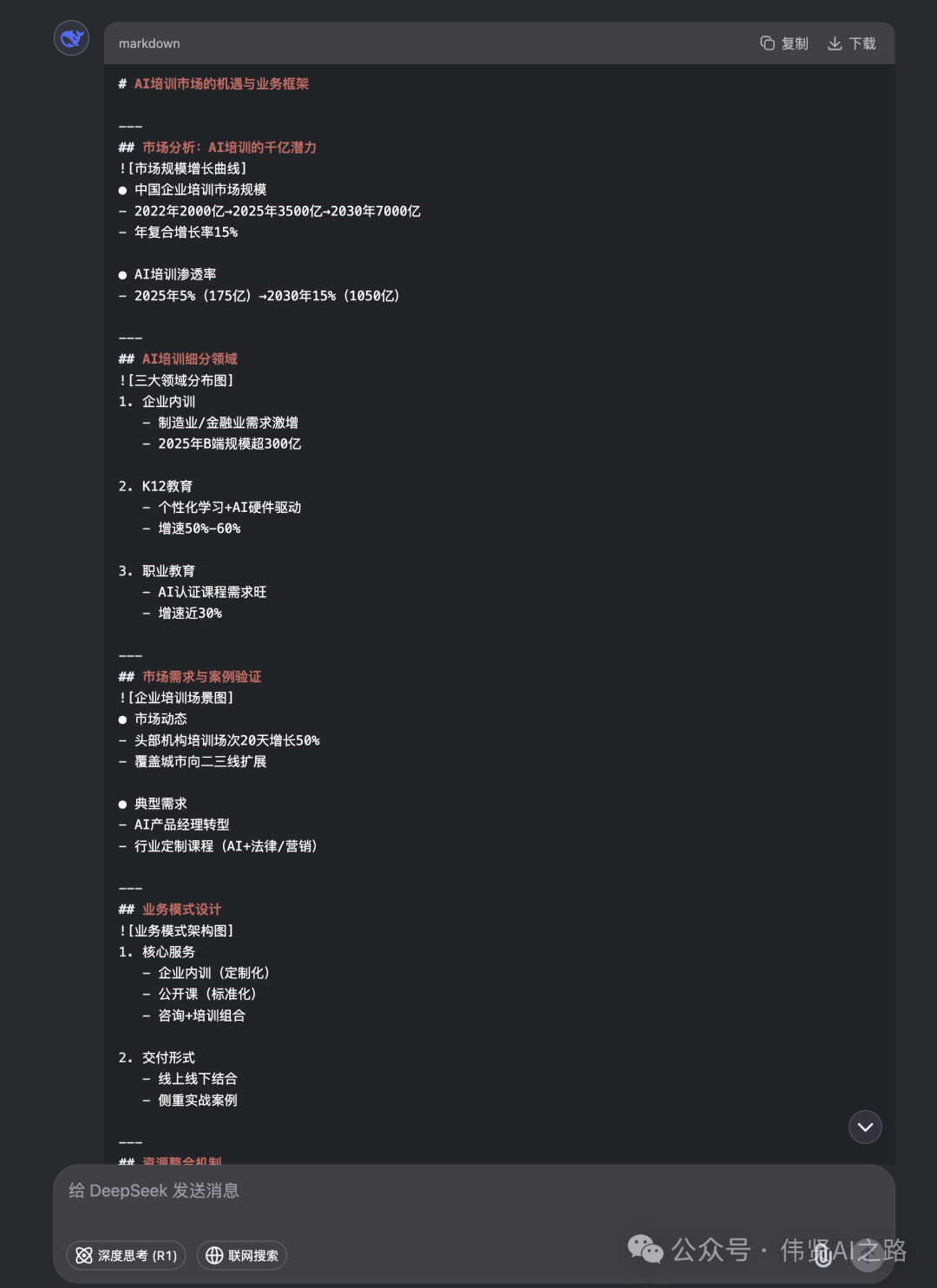
3、生成 PPT 方法
现在网上有很多在线生成 PPT 的方法,但我今天要分享的是用 Marp 来批量生产 PPT,还能自定义主题。
在 Mac 上安装
- 1. 安装 Node.js(如果尚未安装):
brew install node - 2. 安装 Marp CLI:
npm install -g @marp-team/marp-cli - 3. 安装 Python 依赖:
pip install Pillow pdf2image - 4. 安装 Poppler:
brew install poppler
参考代码
把下面的代码复制到md_to_ppt.py文件里。
import argparseimport osimport subprocessfrom pdf2image import convert_from_pathimport shutilimport sysdef inject_marp_header(input_file, output_file, theme_file):with open(input_file, 'r', encoding='utf-8') as file:content = file.read()marp_header = f"""---marp: truetheme: {os.path.abspath(theme_file)}paginate: truesize: 16:9---"""with open(output_file, 'w', encoding='utf-8') as file:file.write(marp_header + content)def convert_md_to_formats(input_file, output_dir, formats, theme_file):input_file = os.path.abspath(input_file)output_dir = os.path.abspath(output_dir)theme_file = os.path.abspath(theme_file)if not os.path.exists(output_dir):os.makedirs(output_dir)filename = os.path.splitext(os.path.basename(input_file))[0]preprocessed_file = os.path.join(output_dir, f"preprocessed_{filename}.md")# 创建预处理的 Markdown 文件inject_marp_header(input_file, preprocessed_file, theme_file)try:pdf_generated = Falsefor format in formats:output_file = os.path.join(output_dir, f"{filename}.{format}")if format in ['pdf', 'pptx', 'html']:marp_command = ["marp", "--html", "--allow-local-files","--theme", theme_file,"--output", output_file,preprocessed_file]print(f"执行命令: {' '.join(marp_command)}")result = subprocess.run(marp_command, check=False, cwd=os.path.dirname(input_file), capture_output=True, text=True)if result.returncode != 0:print(f"错误: Marp 命令失败")print(f"标准输出: {result.stdout}")print(f"标准错误: {result.stderr}")sys.exit(1)print(f"已生成 {output_file}")if format == 'pdf':pdf_generated = Trueelif format in ['png', 'jpeg']:if not pdf_generated:pdf_file = os.path.join(output_dir, f"{filename}.pdf")marp_command = ["marp", "--html", "--allow-local-files","--theme", theme_file,"--output", pdf_file,preprocessed_file]print(f"执行命令: {' '.join(marp_command)}")result = subprocess.run(marp_command, check=False, cwd=os.path.dirname(input_file), capture_output=True, text=True)if result.returncode != 0:print(f"错误: Marp 命令失败")print(f"标准输出: {result.stdout}")print(f"标准错误: {result.stderr}")sys.exit(1)pdf_generated = Truepages = convert_from_path(pdf_file, dpi=300)for i, page in enumerate(pages):image_file = os.path.join(output_dir, f"{filename}_{i + 1}.{format}")page.save(image_file, format.upper())print(f"已生成 {format.upper()} 文件在 {output_dir}")except Exception as e:print(f"发生错误: {str(e)}")sys.exit(1)def process_input(input_path, output_dir, formats, theme_file):input_path = os.path.abspath(input_path)output_dir = os.path.abspath(output_dir)theme_file = os.path.abspath(theme_file)if os.path.isfile(input_path):convert_md_to_formats(input_path, output_dir, formats, theme_file)elif os.path.isdir(input_path):for filename in os.listdir(input_path):if filename.endswith('.md'):file_path = os.path.join(input_path, filename)file_output_dir = os.path.join(output_dir, os.path.splitext(filename)[0])convert_md_to_formats(file_path, file_output_dir, formats, theme_file)else:print(f"错误:{input_path} 既不是文件也不是目录")if __name__ == "__main__":parser = argparse.ArgumentParser(description="将Markdown文件转换为指定格式(PDF、PPTX、HTML、PNG和JPEG)")parser.add_argument("input_path", help="输入的Markdown文件或目录路径")parser.add_argument("output_dir", help="输出目录路径")parser.add_argument("--formats", nargs='+', default=['pdf', 'pptx', 'png'],help="输出格式,可选 pdf, pptx, html, png, jpeg,可以多选")parser.add_argument("--theme", default="default", help="自定义主题CSS文件路径")args = parser.parse_args()process_input(args.input_path, args.output_dir, args.formats, args.theme)
使用方法
- 1. 转换单个文件到所有格式:
python md_to_ppt.py input.md output_dir - 2. 转换单个文件到指定格式:
python md_to_ppt.py input.md output_dir --formats pdf png - 3. 使用自定义主题:
python md_to_ppt.py input.md output_dir --theme path/to/custom-theme.css - 4. 处理整个目录:
python md_to_ppt.py input_directory output_dir - 5. 组合使用:
python md_to_ppt.py input_directory output_dir --formats pptx png --theme custom-theme.css
自定义主题
如果想自定义主题,就创建一个custom-theme.css文件,来调整演示文稿的样式。比如:
/* custom-theme.css */@import 'default';section {background: #f5f5f5;font-family: Arial, sans-serif;}h1 {color: #333;font-size: 2.5em;}h2 {color: #666;font-size: 2em;}
4、效果
直接用 AI 生成的 Markdown 大纲,按照上面的方法,就能直接生成 PPT。

5、总结
用这个方法,朋友的培训视频内容很快就整理成了文章和 PPT,只能说现在 AI 真的是太提效了!
往期精彩
从公式到语音:如何用 AI 把 LaTeX 数学试卷变成自然语言讲稿?
自媒体人必备!公众号文章自动采集神器,3 步搞定批量离线保存



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









