







摘要
DENSE的主要特点
- 单轮通信学习:
- DENSE允许中央服务器在单次通信轮次中学习全局模型,有效降低了通信成本。
- 现有单轮FL方法的局限性:
- 大多数现有的单轮FL方法不切实际或存在固有限制,例如需要公共数据集,客户端模型同质化,以及需要上传额外的数据或模型信息。
- DENSE的创新解决方案:
-
采用两阶段框架:数据生成阶段和模型蒸馏阶段。
数据生成阶段:使用客户端上传的本地模型集合训练生成器(训练了一个同时考虑相似性、稳定性和可转移性的生成器),生成合成数据。
模型蒸馏阶段:将集合模型的知识蒸馏到全局模型中。
-
无需额外信息交换:只需在客户端和服务器之间传输模型参数。
-
无需辅助数据集:不需要额外的训练数据。
-
考虑模型异质性:适应不同客户端拥有不同的模型架构。
-
DENSE的实际应用优势
- 实际应用中的适用性:DENSE方法能够在现实世界中应用,解决了传统FL方法的一些核心问题。
- 实验结果证明其优越性:
- 在多个真实世界数据集上的实验显示了DENSE的优越性。
- 在CIFAR10数据集上,DENSE比最佳基线方法Fed-ADI性能高出5.08%。
背景
单轮FL的挑战
- 单轮FL的动机:在某些场景中,如模型市场,多轮训练不切实际。此外,频繁通信增加了被攻击的风险。比如模型市场[45],用户只能从市场购买训练前的模型,没有任何真实的数据。此外,频繁的通信造成了被攻击的高风险。例如,频繁的通信很容易被攻击者截获,攻击者可以发起中间人攻击[47],甚至可以通过梯度[54]重建训练数据。这样一来,一次性FL由于其“一轮”特性,可以降低被恶意攻击者拦截的概率。因此,在本文中,我们主要关注的是一次性FL。
- 现有单轮FL方法的局限性:例如需要公共数据集,只支持同质化模型,以及可能导致隐私泄露和额外通信成本。
- 异质性的考虑:现有方法通常不考虑模型异质性,即不同客户可能有不同的模型架构。
Method
我们提出了一种名为DENSE的新方法,该方法在考虑模型异质性的同时,不需要共享额外的信息或依赖任何辅助数据集,即可进行一次性FL。学习过程如图1所示,DENSE的整个训练过程如图算法1所示。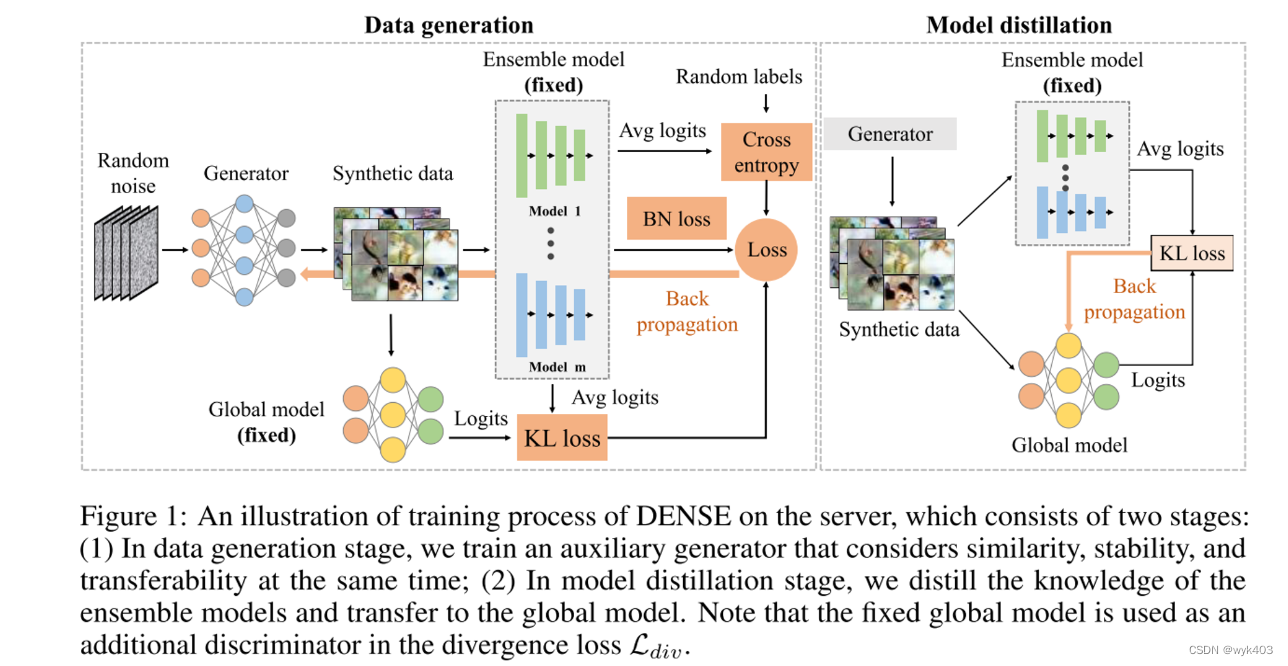

数据生成阶段
- 随机噪声:从随机噪声开始,这是生成合成数据的初始输入。
- 生成器:噪声通过一个训练有素的生成器,生成合成数据。
- 合成数据:生成器输出的合成数据将被用于模型蒸馏阶段。
- 集合模型:集合模型由客户端上传的本地模型组成,这些模型固定不变,并用来指导生成器的训练。
- 平均对数(Avg logits):来自集合模型的输出被平均,生成一个统一的输出预测。
- 损失计算:合成数据和随机标签被用来计算交叉熵损失和批量归一化(BN)损失。
- 反向传播:损失通过反向传播更新生成器的参数。
模型蒸馏阶段
- 合成数据:在数据生成阶段训练好的生成器再次产生合成数据。
- 集合模型:固定的集合模型产生对合成数据的预测输出。
- 平均对数:这些预测输出被平均,并作为知识蒸馏的基础。
- 全局模型:全局模型接收合成数据,并生成自己的预测输出(logits)。
- KL损失:计算全局模型预测和集合模型平均预测之间的Kullback-Leibler损失。
- 反向传播:KL损失用于更新全局模型的参数。
工作流程概述
- 初始化:所有客户端并行更新它们的本地模型,然后将这些模型参数上传至中央服务器。
- 训练生成器:服务器采用这些模型参数作为集合模型,使用随机噪声和标签来训练一个生成器,该生成器学会生成类似于真实数据的合成数据。
- 模型蒸馏:生成器产生的合成数据被用于训练全局模型,这个过程包括将集合模型的知识(通过平均logits表示)转移到全局模型上。
- 反复迭代:这两个阶段在多个周期(epoch)中反复进行,每个周期包含多轮生成器训练($T_G$)和模型蒸馏。
- 最终模型:经过多个训练周期后,全局模型学习到了集合模型的知识,并准备在现实世界数据上进行预测。
这个流程旨在提高全局模型的性能,同时减少了对真实数据的需求,这对于保护隐私和减少通信成本尤为重要。通过这种方式,DENSE方法在只需单次通信的情况下,允许客户端保持它们的数据隐私,同时仍能共同训练出一个强大的全局模型。
Data Generation
数据生成阶段的目标
- 生成合成数据:目标是训练一个生成器来产生与客户端训练数据分布相似的合成数据。
- 保护隐私信息:生成的数据不应泄露任何客户端的敏感信息,即使在面对攻击者时也应确保隐私信息的安全。
- 考虑模型异质性:在实际应用中,客户端模型可能具有不同的架构,这需要在生成数据时加以考虑。
数据生成方法
- 利用集合模型:使用客户端上传的一系列训练良好的模型作为基础来训练生成器。
- GAN的局限性:虽然最近有研究使用预训练的生成对抗网络(GAN)来生成数据,但由于这些GAN是在公共数据集上训练的,其生成的数据分布可能与客户端的训练数据不同。
- 生成器训练:
- 输入:随机噪声 z(来自标准高斯分布)和随机的独热编码标签 y(来自均匀分布)。
- 过程:生成器 G(⋅) 使用这些输入生成合成数据 x^=G(z),以使得 x^ 与客户端带有标签 y 的训练数据相似。
- 因为是合成图片,所以攻击者无法从合成图片中取得任何客户端信息
- 生成器必须具有相似、稳定、可迁移的能力,因此使用三个损失函数
- 将噪音图片输入生成器得到合成图片,再将合成图片送入客户端模型中计算平均logits值,选取logits而不是Pred的类别是因为Pred会泄露客户端信息,然后与随机标签计算交叉熵,该损失函数相当于用于分类的主损失函数,但只有该损失函数无法取得良好训练,因为客户端存在non-IID数据
相似性
首先,我们需要考虑合成数据ˆx与训练数据之间的相似性。由于我们无法访问到客户端的训练数据,所以我们无法直接计算合成数据与训练数据的相似度。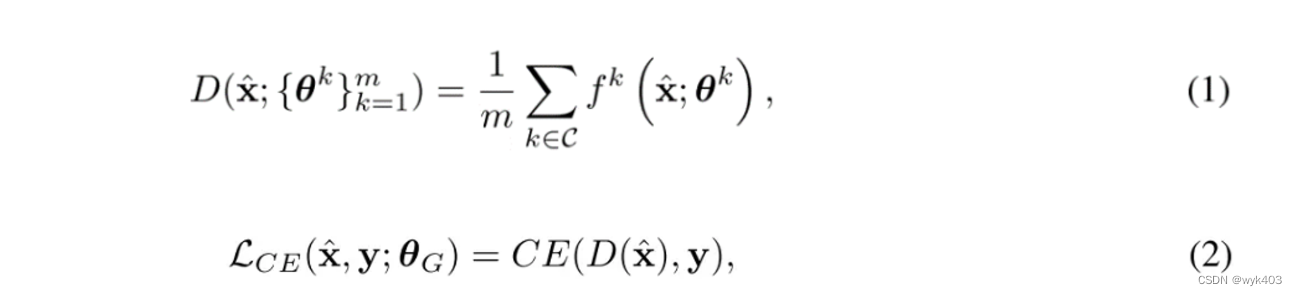
交叉熵损失的最小化旨在训练生成器,以使集合模型能够以高概率将合成图像分类到某个特定类别。
相似性计算的逻辑
- 间接相似性:
- 如果合成数据 x^ 能够被集合模型准确分类,这意味着它们在分布上与训练数据相似。
- 通过最小化合成数据和随机标签之间的交叉熵损失,合成数据被引导以更贴近客户端实际数据的方式生成。
- 隐私保护:
- 由于不直接比较合成数据和实际训练数据,这种方法减少了客户端敏感信息泄露的可能性。
挑战
- 非IID数据:
- 集合模型是在非IID数据上训练的,因此仅使用交叉熵损失可能导致生成器不稳定,陷入次优的局部最小值或过拟合于合成数据。
稳定性
其次,为了提高生成器的稳定性,我们建议增加一个额外的正则化来稳定训练。特别地,我们利用批归一化损失使合成数据符合批归一化统计量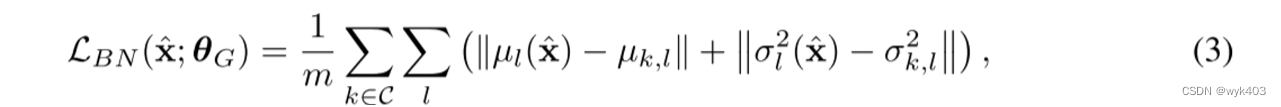

转移性问题的核心:
- 合成数据与决策边界的关系:通过使用交叉熵(CE)损失和批量归一化(BN)损失,虽然可以训练出能够生成合成数据的生成器,但观察到这些合成数据通常距离集合模型(作为教师模型)的决策边界较远。这导致了一个问题:教师模型难以将其知识有效地传递给全局模型(即学生模型)。我们的目标是学习全局模型的决策边界,并对真实的测试数据(蓝钻)具有较高的分类精度。
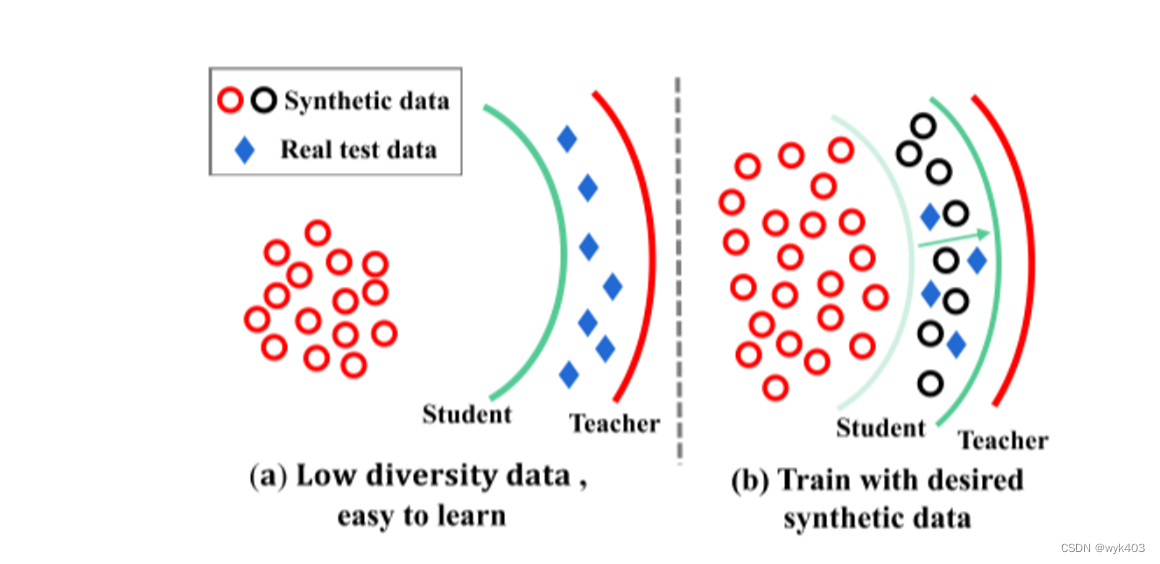
知识蒸馏的本质:
- 决策边界信息的转移:知识蒸馏的本质是将教师模型的决策边界信息传递给学生模型。决策边界是模型用来区分不同类别的界线。
解决方法:
-
引入边界支持损失:为了解决上述问题,提出了一种新的边界支持损失。这种损失鼓励生成器生成更多位于集合模型和全局模型决策边界之间的合成数据。
-
合成数据的两个集合:
- 第一集合:全局模型和集合模型对数据的预测相同(表示这些数据在两个决策边界的同一侧)。
- 第二集合:两模型对数据的预测不同(表示这些数据位于两个决策边界之间)。
损失函数:
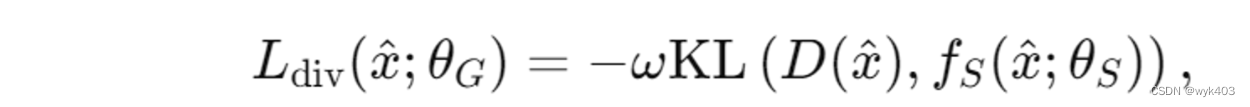
对第一集合中的数据输出0,对第二集合中的数据输出1。
目的:通过最大化 KL 散度损失,生成器可以生成对模型蒸馏阶段更有帮助的合成数据,从而提高集合模型的知识转移能力。
关键在于通过引入新的损失函数(边界支持损失),使得生成器能够产生更有助于全局模型学习集合模型决策边界的合成数据。

将上述损失综合,可得生成器的损失如下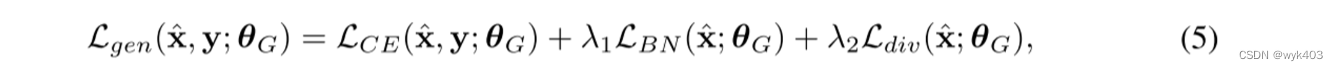
Model Distillation
模型蒸馏阶段的目标
- 使用集合模型和生成器训练全局模型:在此阶段,全局模型(学生模型)通过结合先前讨论的生成器产生的合成数据和集合模型(教师模型)的知识进行训练。
模型蒸馏的方法
- 集合模型作为教师:受先前研究启发,提出使用集合模型作为教师来训练全局模型(学生模型)。
- 传统聚合方法的局限性:
- 传统的参数聚合方法(如FedAvg)在处理不同架构的模型时受限。
- 非IID数据的存在使得FedAvg无法提供良好的性能,甚至可能导致性能分歧。
- 知识蒸馏的实施:
- 通过最小化集合模型和全局模型在相同合成数据上的预测之间的差异来蒸馏知识。
- 使用平均对数(Eq. (1))来计算合成数据的预测,并应用于知识蒸馏。
- 这种方法适用于异质和同质的联合学习系统。
- 目标函数:
- 使用Kullback-Leibler(KL)损失函数
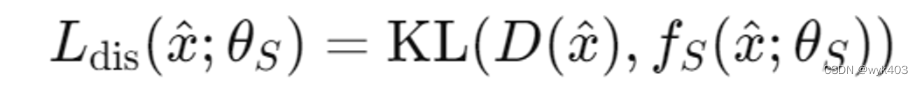
来最小化集合模型和全局模型之间的差异。
DENSE的兼容性和灵活性
- 无限制的客户端本地模型:客户端可以使用任意技术训练他们的本地模型。
- 兼容性:DENSE可以与任何本地训练技术结合使用,以进一步提高全局模型的性能。
在DENSE框架的模型蒸馏阶段,通过使用集合模型(作为教师模型)和合成数据来训练全局模型(学生模型),克服了传统聚合方法在异质模型和非IID数据背景下的局限性。这一阶段通过最小化KL损失来实现知识蒸馏,使全局模型能够学习集合模型的知识,同时允许客户端模型的多样性和灵活性。这种方法强调了DENSE在实际应用中的广泛适用性和高度兼容性。
隐私保护方面的讨论
- 隐私泄露的风险:
- 使用生成对抗网络(GANs)攻击:存在恶意用户利用 GANs 重建其他参与者私有数据集的样本的风险。
- 模型交换:在FL中,服务器和客户端之间交换模型可能导致潜在的隐私泄露。
- 本文方法的隐私保护措施:
- 生成器不直接接触真实数据:这减少了直接泄露私有数据的风险。
- 单轮通信:只进行一次通信轮次,从而降低隐私泄露的风险。
- 展示生成的图像:这些图像不直接泄露任何真实数据的信息。
- 未来工作:
- 可以将现有的多种隐私保护方法融入到本框架中,以更好地保护客户端免受对手的攻击。
知识蒸馏方面的讨论
- 传统FL中的模型异质性问题:
- 在传统FL框架中,所有用户必须同意全局模型的特定架构。
- Li等人提出了一种允许参与者独立设计模型的新FL框架,使用知识蒸馏。
- 代理数据集的局限性:
- 使用代理数据集进行知识蒸馏可以缓解非IID数据引起的模型漂移问题,但这种方法在实际应用中不总是可行的,因为服务器上不总是有精心设计的数据集可用。
- 无数据知识蒸馏:
- 这是一个有前景的方法,可以在没有任何真实数据的情况下将教师模型的知识传递给学生模型。
- Lin等人提出了一种通过合成数据进行模型融合的无数据集合蒸馏方法,尽管这种方法在每轮通信中需要较高的通信和计算成本。
- 本文更关注在异质模型情况下通过单轮通信获得良好的全局模型,这是更具挑战性和实用性的。
- 针对FL的无数据知识蒸馏的问题:
- Zhu等人提出了一种FL的无数据知识蒸馏方法,其中学习的生成器来自于本地模型的预测。
- 但是,这种方法需要将学习的生成器广播给所有客户端,然后客户端需要将它们的生成器发送给服务器,这增加了通信负担。
- 生成器直接访问本地数据可能会引起隐私问题。
总体分析
这段文字强调了在设计联合学习算法时考虑隐私保护和知识蒸馏的重要性。它指出了现有方法的限制,并提出了改进方案,特别是在处理模型异质性和减少通信成本方面。本文方法通过在中央服务器上存储生成器并限制其对真实本地数据的访问,有效地增强了隐私保护。同时,通过只进行一次通信轮次,减少了隐私泄露的风险,同时降低了通信成本。















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









