







摘要
这篇论文提出了一个名为 COMET 的个性化联合学习(PFL)框架,专注于在边缘设备(如物联网设备和智能手机)上进行高效的模型训练。这些边缘设备通常具有不同的系统能力和有限的通信带宽。COMET 框架的独特之处在于,它允许不同的客户端使用自选的异构模型进行训练,而不是直接交换模型参数。这通过一种称为集群共蒸馏(clustered codistillation)的技术实现,其中客户端通过知识蒸馏将自己的知识传递给数据分布相似的其他客户端。
该框架的主要优势是:
- 客户端可以根据自己的需求和能力,选择不同的模型架构。
- COMET 通过传输知识而非高维模型参数,显著降低了通信成本。
- 理论上证明了 COMET 的收敛和泛化性能。
- 实验表明,COMET 在测试精度上表现优异,并且与其他先进的 PFL 方法相比,通信成本降低了几个数量级,同时允许客户端模型异构。
总的来说,COMET 提供了一个既实用又高效的个性化联合学习框架,适用于资源受限的边缘设备,如物联网网络中的设备。
背景
现有的个性化联合学习方法包括应用元学习、在每个客户端训练单独的模型并与其他客户端模型进行加权聚合、使用全局目标作为训练各个客户端个体模型的正则化器,或者使用模型/数据插值与聚类来实现个性化。然而,这些方法通常要求部署在客户端的模型具有相同的架构,即同质化模型,并且要求客户端直接传输其模型参数。
针对这些限制,论文中的 COMET 框架放宽了这些约束,允许异构模型在客户端之间部署,并通过集群共蒸馏来训练个性化模型。共蒸馏通过在客户端之间交换对共同无标签数据集的模型预测,而不是模型参数,从而减少通信成本。然而,在传统的共蒸馏中,一个正则化项被加入到每个客户端的标准交叉熵损失中,以惩罚客户端的预测与所有客户端预测的平均值显著不同。但在联合学习中,由于客户端可能拥有高度异质的数据,因此不能直接应用这种传统共蒸馏。强迫每个客户端遵循所有客户端的平均预测可能会因为从数据分布显著不同的客户端学习而恶化其泛化性能。因此,COMET 通过集群共蒸馏解决了这一问题,更适合于数据分布异质性的场景。
优点
COMET 是一种针对个性化联合学习(PFL)的新型框架,它通过利用客户端间的数据关联来实现更高效的学习。在 COMET 中,每个客户端只使用数据分布相似的其他客户端的平均预测,从而避免了从数据关联度较低的客户端学习不相关的知识。这种方法的优点包括:
- 模型异构性: COMET 允许客户端之间的模型异构,即不同的客户端可以根据其资源能力选择不同的模型架构和大小。这对于资源受限的边缘设备尤为重要。
- 通信效率: COMET 显著减少了通信成本,通过传输逻辑值(logits)而非高维模型参数来实现这一点。通信效率的提升与模型参数维度相比逻辑空间维度的大小成正比。
- 泛化性能: COMET 通过数据关联改进了泛化性能,防止客户端从数据关联度较低的客户端学习,特别是在数据异质性的情况下。
此外,论文还提供了 COMET 的理论分析,包括其收敛保证和泛化属性。这些分析表明,通过数据关联进行聚类可以改善数据异质客户端的泛化属性,并且每个客户端可以通过不同程度的正则化来最大化其个性化性能。实验结果显示,无论是在模型同质还是模型异构环境中,COMET 都能在通信成本大幅减少的同时,实现高测试精度,与其他SOTA FL方法相比具有显著优势。论文中还展示了COMET 框架的概览图。
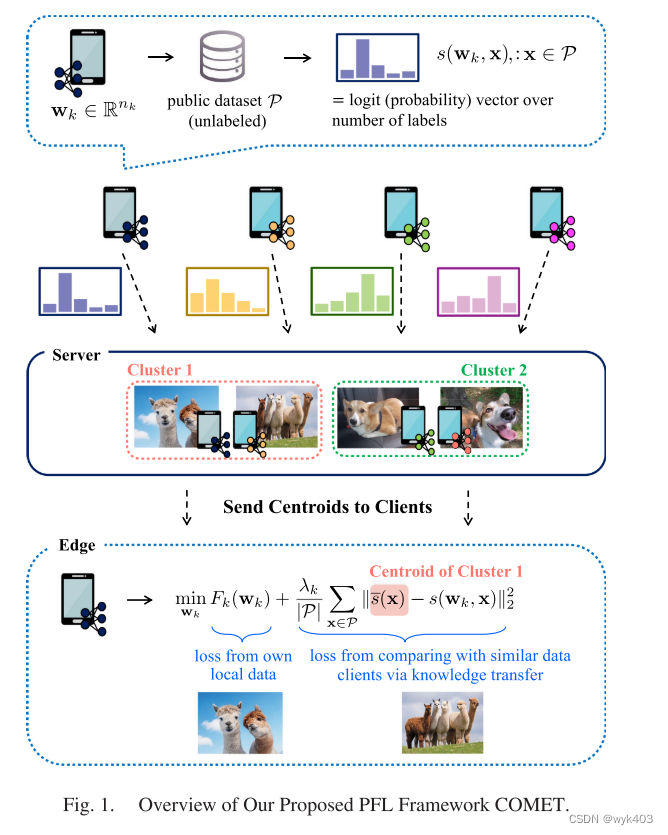
相关工作
一些最新研究提出使用知识蒸馏(KD)来训练具有客户端模型异构性的个性化模型,但它们通常依赖于不切实际的假设(如全部客户端参与或有大量标记的公共数据)。此外,这些方法没有考虑客户端间的数据关联,即客户端可以通过与数据相关联的其他客户端而非数据分布大不相同的客户端来改善个性化。
COMET 框架克服了这些限制,提出了一种结合数据关联的集群共蒸馏方法。在传统的知识转移和共蒸馏中,知识从一个在大规模数据集上训练的模型转移到其他任务的模型上。共蒸馏则是同时训练多个模型,并添加正则化项以鼓励模型产生类似的输出。然而,标准的共蒸馏方法在PFL中面临挑战,因为每个客户端的数据分布可能与其他客户端截然不同。COMET 通过对有相似数据分布的客户端进行聚类,然后在这些聚类内进行共蒸馏,从而显著改善了个性化模型的性能。这一点在论文中的理论和实证结果中都得到了证明。
PROPOSED PFL FRAMEWORK:COMET
数据异质性问题
在这种情况下,拥有大量训练样本的客户端可能选择退出联合学习,转而训练自己选择的模型 ,通过最小化其本地目标来实现。但对于只有少量训练样本的客户端,
和 $D_k$ 可能差异很大,因此仅使用本地数据集
训练的模型
可能泛化得很差。这样的客户端虽然有动力参与联合学习,但由于其他数据分布差异较大的客户端带来的不良泛化属性,他们可能无法从联合学习中获益。
COMET 通过将客户端与数据分布相似的其他客户端聚类,解决了这个问题。不论数据样本多寡,所有客户端都可以通过与数据分布相似的客户端进行聚类,从而提高泛化性能。
COMET Objective
- 共蒸馏和个性化模型训练:COMET 使用共蒸馏来训练个性化模型,其中每个客户端与其模型输出与自身相似或相关的其他客户端进行共蒸馏。
- 私有和公共数据集的使用:每个客户端拥有私有数据集 Bk 和包含未标记数据的公共数据集 P。公共数据集 P 用作跨客户端共蒸馏的参考数据集。
- 模型输出和正则化:客户端的分类模型输出预定义数量类别 N 上的软决策(logits),即 N 类上的概率向量。模型训练中包含正则化项,该项基于客户端之间共享的 logits 平均值。
- 基于聚类的权重分配:正则化项的计算基于客户端 logits 之间的L2-范数距离聚类得出的权重。因此,具有相似 logits 的客户端在彼此的 logits 上具有更高的权重。
- 提升模型的个性化性能:通过线性回归示例说明,当使用聚类来确定权重
时,每个客户端的输出模型将更接近其真实模型。这表明 COMET 能够通过考虑数据分布的相似性来提高模型的个性化性能。
直观理解
COMET Solver
client update:
在每个通信轮次 t 和本地迭代 r 中,客户端 k 在其设备上最小化公式 (1),同时仅与服务器交换逻辑值 ,而不是模型参数
。每个客户端的本地更新规则为:
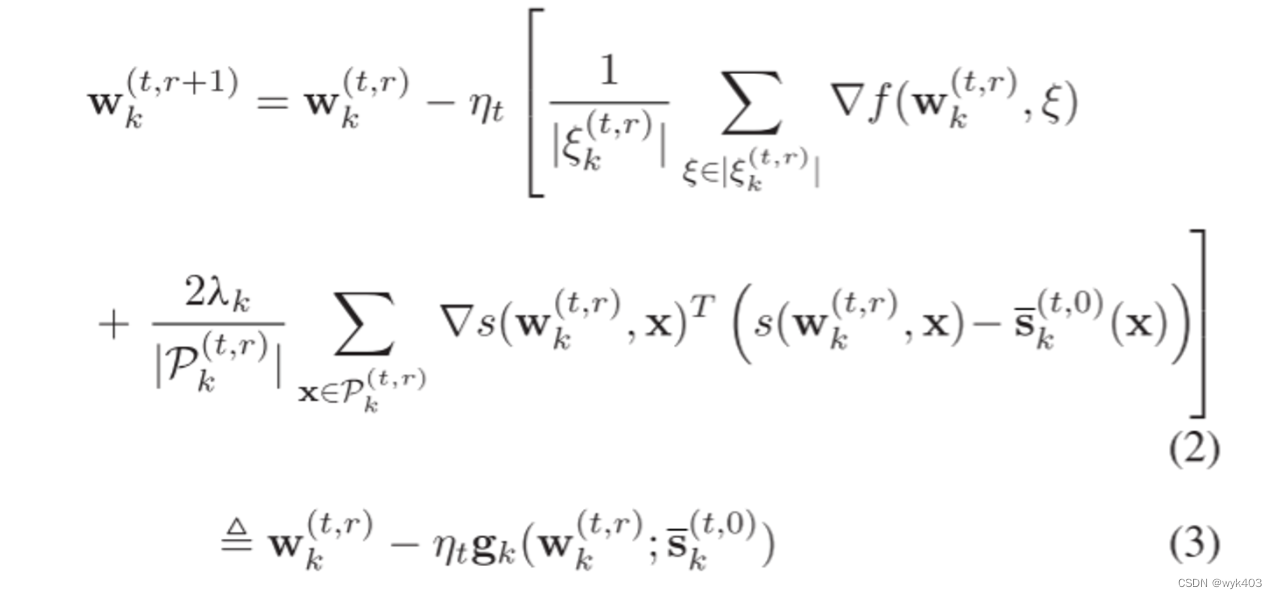
 服务器端的聚类知识聚合:
服务器端的聚类知识聚合:



实验结果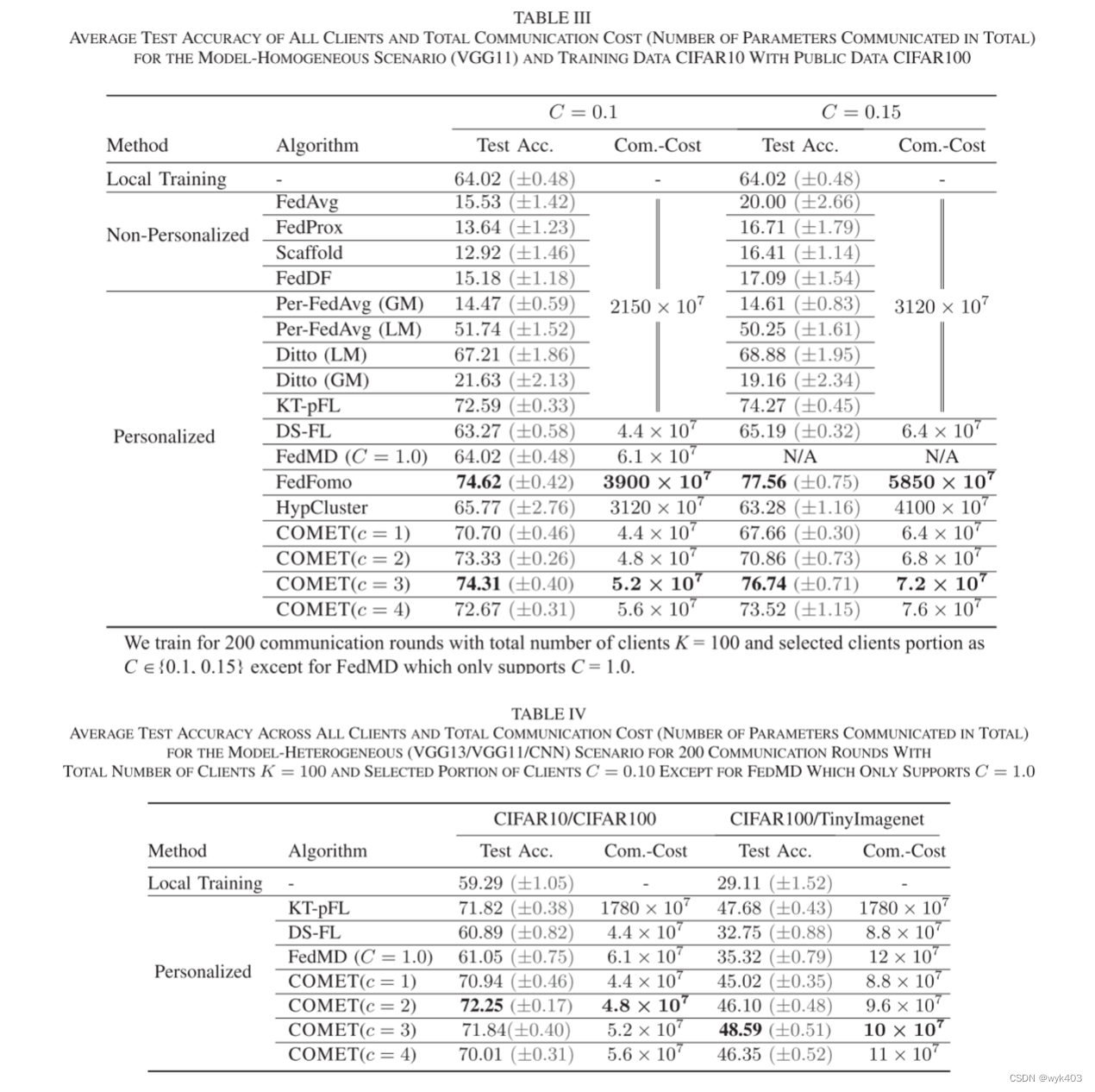
-
通信效率:
- 在不同客户端选中比例(C = 0.1 和 C = 0.15)下,COMET 与其他最先进算法相比表现出高测试准确率和低通信成本。
- 对于 C = 0.1,COMET 在聚类数 c = 3 时达到 74.31% 的测试准确率,相比其他算法节省了高达 750 倍的通信成本。
- 尽管 FedFomo 在测试准确率上略高(74.62%),但其通信成本(3900 × 10^7 参数)远高于 COMET(5.2 × 10^7 参数)。
- 对于 C = 0.15,COMET 同样在低通信成本下(7.2 × 10^7 参数)实现了 76.74% 的高测试准确率,而 FedFomo 虽准确率略高(77.56%),但通信成本更高(5850 × 10^7 参数)。
-
客户端模型异质性:
- COMET 在客户端模型异质性的情况下表现出色,这是联合学习中的一个现实场景,即客户端根据其数据集大小或系统能力选择不同大小的模型。
- 在模型异质性下,COMET 的测试准确率达到 CIFAR10/CIFAR100 数据集组合的 72.25% 和 CIFAR100/TinyImagenet 的 48.59%,通信成本分别为 4.8 × 10^7 和 10 × 10^7。
- COMET 在模型异质性情况下的测试准确率接近于模型同质性情况,说明模型异质性虽然提高了 COMET 的可行性,但并未大幅影响客户端的局部性能。
-
数据关联度和聚类数量:
- COMET 在服务器端执行聚类,将不同客户端的逻辑值按照 c 个聚类分组。c 的大小直接影响每个聚类中数据的关联度。
- 实验表明,对于 C = 0.1 和 C = 0.15,当 c=3 时,COMET 取得最佳测试准确率。当 c 增加超过 3 后,测试准确率下降且通信成本上升。
- 这表明适当增加数据关联度可以提高性能,但超过一定阈值后会因减少每个聚类中信息的多样性而损害泛化性能。
-
确定聚类数量 c:
- 尽管 c 可以作为一个超参数在验证数据集上调整,但在已知客户端数据分布异质性的情况下,可以根据数据分布的大致群组将 c 设置为相应的聚类数量。
- 在不清楚数据分布的情况下,可根据数据异质性的强度比例设置 c,其中 C 是每轮通信选中的客户端比例,K 是客户端总数。
总结
COMET 框架在处理联合学习(FL)中客户端数据和系统异质性时的优势和局限性。以下是主要内容的总结:
- 处理数据和系统异质性:
- 在资源受限的联合学习环境中,客户端的数据和系统异质性是设计个性化联合学习(PFL)算法时必须考虑的关键因素。
- 许多先前的工作强制客户端使用同质化模型并直接交换模型参数,这可能导致沉重的通信成本。
- COMET 通过集群共蒸馏应对客户端的数据和系统异质性,允许在客户端上使用异质模型,且无需直接通信模型参数。
- 性能和通信成本:
- 相比其他最先进的联合学习方法,COMET 在竞争性能方面表现出色,并且通信成本更小。
- 局限性和未来发展方向:
- COMET 的一些关键局限性包括需要较小的标签空间和与训练任务相关的公共数据,以保持通信效率和在个性化方面的有效性。
- 如果标签空间过大(例如 Glink360 K 数据集),COMET 可能不再通信高效。
- 如果公共数据与感兴趣的任务完全不相关,则可能不会提高客户端的泛化性能。
- 未来的研究方向包括解决这些局限性,并深入理解 COMET 的隐私影响以及确定最优的数据关联度,以最大化客户端个性化模型的性能。
总的来说,虽然 COMET 在处理客户端的数据和系统异质性方面表现出色,并在保持较低通信成本的同时达到与最先进技术相竞争的性能,但它也有一些局限性,需要在未来的工作中加以解决。















 2486
2486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









