






 本文详细介绍了CUDA编程中的内核函数,它是GPU并行计算的核心,支持并行执行、异步操作和内存管理。文章还探讨了threadIdx,blockIdx,blockDim,和gridDim等重要概念,以及如何利用它们确定线程在数据处理中的作用和内存管理策略。
本文详细介绍了CUDA编程中的内核函数,它是GPU并行计算的核心,支持并行执行、异步操作和内存管理。文章还探讨了threadIdx,blockIdx,blockDim,和gridDim等重要概念,以及如何利用它们确定线程在数据处理中的作用和内存管理策略。
内核函数 __global__
在CUDA中,内核函数定义了一种在GPU上执行的操作,它通常被设计为处理大量的数据。这些函数被主机(CPU)调用并在设备(GPU)上执行。在编程时,开发者会编写这些内核函数来执行特定的计算任务,然后将这些任务分发到GPU的多个处理核心上进行并行处理。
内核函数的特点包括:
-
并行执行:内核函数被设计为在多个线程上同时执行,其中每个线程处理数据集的一部分。
-
特殊的语法:在CUDA C/C++中,内核函数使用
__global__声明符定义,这表明这些函数将在GPU上执行,而不是CPU上。 -
线程索引:在内核函数内部,可以使用特殊的内置变量(如
threadIdx,blockIdx,blockDim和gridDim)来确定当前线程的唯一索引,这对于确定当前线程应该处理数据集中的哪一部分是必要的。 -
异步执行:从CPU调用内核函数通常是异步的,这意味着CPU发起调用后不会等待内核执行完成就继续执行。如果需要,开发者必须显式同步CPU和GPU。
-
内存管理:在调用内核函数之前,通常需要将数据从主机内存复制到GPU内存,执行完毕后再将结果从GPU内存复制回主机内存。
计算唯一线程ID索引
unsigned int tid = blockIdx.x * blockDim.x + threadIdx.x;
tid 是线程的全局唯一索引,它由其线程块的索引 (blockIdx.x) 乘以每个块的线程数 (blockDim.x) 再加上线程在其块内的索引 (threadIdx.x) 来计算得出。这种计算模式使得每个线程都可以通过 tid 知道自己负责处理数据中的哪一部分。
threadIdx, blockIdx, blockDim, 和 gridDim 是 CUDA 编程中的四个关键概念,它们用于在编写 CUDA 内核函数时管理和控制线程。在 CUDA 中,执行一个内核函数的每个线程都有一个独特的索引,用于决定它应该处理数据的哪一部分。这些索引是通过 threadIdx, blockIdx, blockDim, 和 gridDim 这些内置变量来计算得到的。
threadIdx:这是一个三维向量 (threadIdx.x, threadIdx.y, threadIdx.z),代表当前线程在其线程块内的索引。例如,threadIdx.x 是线程在 X 维度上的索引。这些索引通常从 0 开始。
blockIdx:这也是一个三维向量 (blockIdx.x, blockIdx.y, blockIdx.z),代表当前线程块在整个网格中的索引。就像线程被组织成线程块一样,线程块也被组织成一个网格。
blockDim:这是一个三维向量 (blockDim.x, blockDim.y, blockDim.z),表示每个线程块中的线程数目。例如,blockDim.x 是线程块在 X 维度上的线程数目。
gridDim:这同样是一个三维向量 (gridDim.x, gridDim.y, gridDim.z),代表整个网格中的线程块数量。例如,gridDim.x 是网格在 X 维度上的线程块数目。 使用这些变量,你可以计算出一个全局唯一的线程索引,这对于确定每个线程应该处理数据的哪一部分至关重要。
unsigned int thread_stride = blockDim.x * gridDim.x;
blockDim.x * gridDim.x:当你将每个块的线程数乘以网格中的块数时,你得到的是网格中线程的总数。这表示在 X 方向上的总线程数。 代表了在处理数据时每个线程应该跳过的元素数目来到达它下一个处理的元素。 例如,假设你有一个很大的数组,你想让每个线程处理数组中的一个元素。由于线程的总数可能少于数组的长度,因此每个线程可能需要处理多个元素。在这种情况下,thread_stride 就是每个线程在处理完一个元素后跳过的元素数目,以便处理下一个元素。
计算当前线程所在的单元索引。
int icell = (tid >> 5) * (32 / (nthread / ncell)) + (tid & 31);
tid >> 5: >> 是位右移操作符。在这里,tid >> 5 相当于将 tid 除以 25=3225=32。 这个操作通常用于快速计算除法,这里用来获取线程所在的 warp(线程束)的索引。CUDA 中的一个 warp 包含 32 个线程,所以通过 tid >> 5,我们可以确定给定线程属于哪个 warp。
32 / (nthread / ncell): 首先,nthread / ncell 计算每个 cell 分配到的线程数。 接着,32 / (nthread / ncell) 计算每个 warp 需要处理的 cell 数量。由于一个 warp 包含 32 个线程,这个结果表示一个 warp 可以完整处理多少个 cell。
(tid >> 5) * (32 / (nthread / ncell)): 这部分计算当前线程所在 warp 的起始 cell 索引。如果每个 warp 处理多个 cell,这个值就是当前 warp 处理的第一个 cell 的索引。
tid & 31: & 是位与操作符。tid & 31 的效果相当于 tid % 32,它得到 tid 相对于其 warp 的局部索引。 在一个 warp 中,线程的 ID 从 0 到 31。这个操作确定了线程在其所在 warp 中的相对位置。
(tid >> 5) * (32 / (nthread / ncell)) + (tid & 31): 最后,将 warp 的起始 cell 索引与线程在 warp 中的局部索引相加,得到线程应该处理的 cell 的全局索引
CUDA中每个部分,如wrap,thread,cell
1. Thread(线程)
在 CUDA 中,线程是执行操作的最小单元。每个线程执行相同的代码(即内核函数)但通常会处理不同的数据。 CUDA 通过线程来实现数据的并行处理,每个线程独立执行一部分任务。这使得处理大量数据时能够显著提高性能,特别是在需要对大型数据集进行相同操作的情况下。 CUDA 中的线程组织为更大的结构,称为线程块(thread blocks)和网格(grids)。
2. Warp(线程束)
Warp 是 CUDA 中的一个核心概念,它代表一组同时执行的线程。 每个 warp 包含固定数量的线程,通常是 32 个。这意味着 warp 中的所有线程同时执行相同的指令,但可能在不同的数据上操作。 Warp 是调度和执行的基本单位。GPU 在执行时会按 warp 为单位调度线程。这就要求在编写 CUDA 程序时考虑到 warp 的特性,以优化性能。
3. Thread Block(线程块)
线程块是一组线程的集合,这些线程可以协同执行任务,并且能够通过共享内存和同步操作进行通信。 一个线程块中的线程数量是可配置的,但有最大限制(例如,最多 1024 个线程)。 线程块内的线程可以通过三维索引(threadIdx.x, threadIdx.y, threadIdx.z)来标识。
4. Grid(网格)
网格是线程块的集合。当一个 CUDA 内核函数被调用时,它在一个网格中执行,网格中包含多个线程块。 网格的维度(即包含多少个线程块)也是可配置的,并且线程块可以通过三维索引(blockIdx.x, blockIdx.y, blockIdx.z)来标识。
5. Cell
"Cell" 不是 CUDA 中的一个官方术语,它可能是特定程序或应用中使用的术语。 在许多情况下,"cell" 可能指的是数据集的一个元素或一个数据点,例如在图像处理中的一个像素,或在物理仿真中的一个网格点。 在 CUDA 程序中,线程通常被用来独立处理一个或多个 "cell",这样可以高效地并行处理大量数据。
GPU 关键组件
关键组件层级关系
- GPU
- Global Memory
- L2 Cache
- GPC
- SM
- SP
- L1/Shared Memory
- Reg
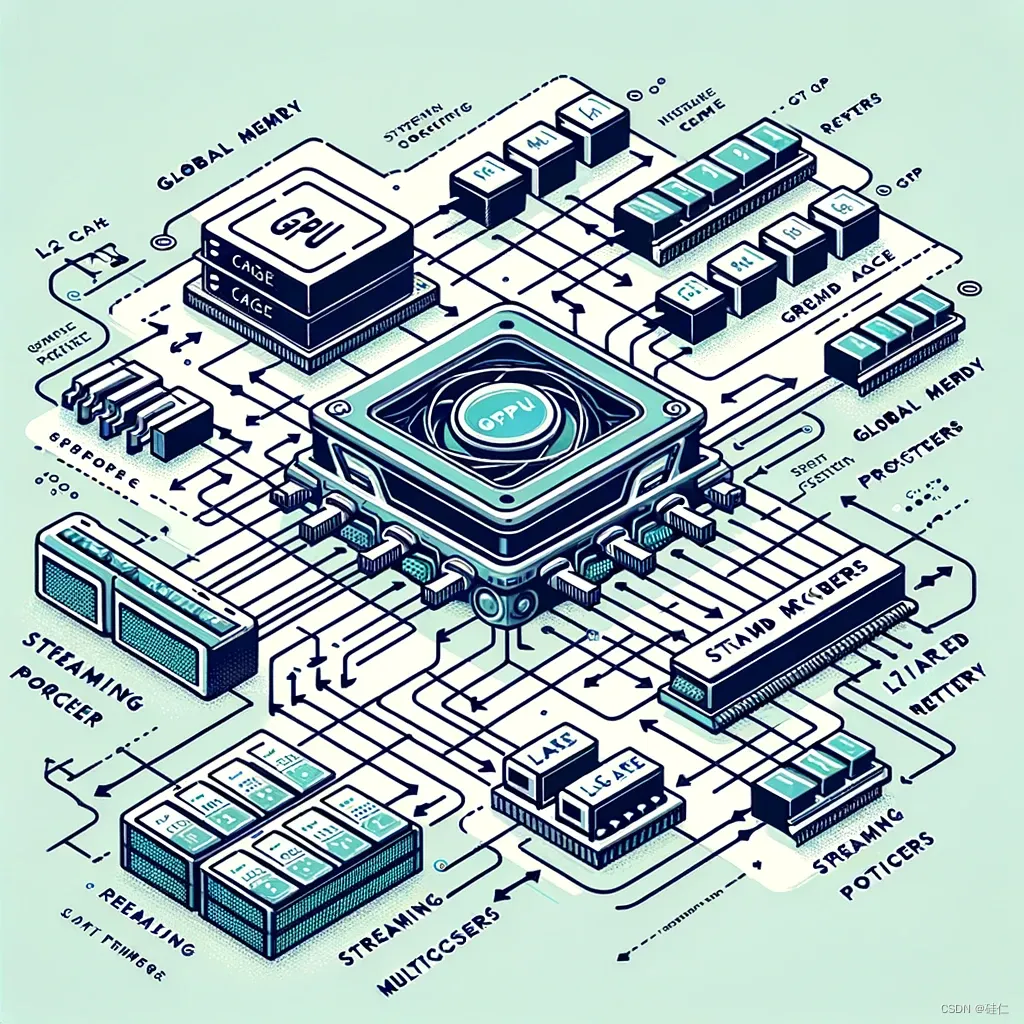
组件介绍
- Global Memory(全局内存)
功能:GPU 的主内存区域,用于存储处理过程中的数据。
关系:所有 SM 共享全局内存。
- L2 Cache(二级缓存)
功能:为 GPU 提供一个大型、高速的缓存区域,用于存储频繁访问的数据。
关系:为所有 SM 提供服务,优化访问全局内存的性能。
- GPC(Graphics Processing Cluster)
功能:GPC 是处理图形和通用计算任务的高级单元。
关系:包含多个 SM(Streaming Multiprocessors)。
- SM(Streaming Multiprocessor)
功能:SM 是 GPU 中的核心组件,用于并行执行线程。
关系:包含多个 SP(Streaming Processors),以及 L1/共享内存和寄存器(Reg)。
- SP(Streaming Processor)
功能:SP,也称为 CUDA 核心,是执行实际计算任务的基本单元。
关系:组成 SM 的一部分。
- L1/Shared Memory(一级缓存/共享内存)
功能:为 SM 上运行的线程提供快速数据访问和线程间通信的内存空间。
关系:直接与 SM 中的线程交互。
- Reg(寄存器)
功能:为 GPU 上的每个线程提供快速访问的存储空间。
关系:每个 SM 配备一定数量的寄存器,供其线程使用。















 4430
4430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









