







在利用pandas进行数据分析时,有时需要计算某一列数据的标准差,我们常用std()函数来实现,但是一般都没有关注过里面的一个重要参数ddof,本文就来介绍一下这个参数的理解。
ddof参数的取值一般有两个,即ddof=0或者ddof=1。
ddof=0时:
当我们的参数取ddof=0时,计算的是总体标准差,计算公式为:
∑
i
=
1
n
(
x
i
−
x
^
)
2
n
\sqrt{\frac{\sum \limits_{i=1}^{n}(x_i-\hat{x})^2}{n}}
ni=1∑n(xi−x^)2
其中,
X
=
{
x
1
,
x
2
,
⋯
,
x
n
}
X=\{x_1,x_2,\cdots,x_n\}
X={x1,x2,⋯,xn},
x
^
\hat{x}
x^表示为数据
x
x
x的均值,计算公式为:
x
^
=
∑
i
=
1
n
x
i
n
\hat{x}=\frac{\sum \limits_{i=1}^nx_i}{n}
x^=ni=1∑nxi
其中,
n
n
n为总体个数。
ddof=1时:
当ddof=1时,计算的是样本的标准差,计算公式为:
∑
i
=
1
n
(
x
i
−
x
^
)
2
n
−
1
\sqrt{\frac{\sum \limits_{i=1}^n(x_i-\hat{x})^2}{n-1}}
n−1i=1∑n(xi−x^)2
字母的代表方式与上文一样,只不过这里的
n
n
n表示的是样本的个数。
举例说明
我们在实际应用中看不同的计算方式得到的结果:
首先展示我们的数据集:
import numpy as np
import pandas as pd
data = pd.read_excel('EXE5_1.xlsx')
data
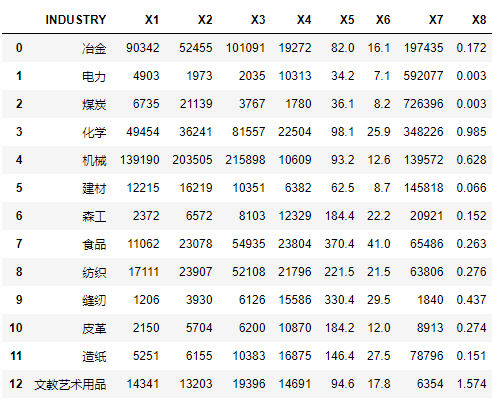
我们分别考虑不同的ddof,并计算出标准差的数值:
std_ddof0 = np.std(data.iloc[:,1],ddof=0)
std_ddof0
40280.5706797213
std_ddof1 = np.std(data.iloc[:,1],ddof=1)
std_ddof1
41925.34721153412
可以明显的看出,ddof=1时,计算的数值偏大,是因为分母为 n − 1 n-1 n−1。


















 3919
3919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











