







一、引言
这篇论文是CVPR2017年的文章,采用特征金字塔做目标检测,有许多亮点,特来分享。
特征金字塔(Feature Pyramid Networks, FPN)的基本思想是通过构造一系列不同尺度的图像或特征图进行模型训练和测试,目的是提升检测算法对于不同尺寸检测目标的鲁棒性。但如果直接根据原始的定义进行FPN计算,会带来大额的计算开销。为了降低计算量,FPN采用一种多尺度特征融合的方法,能够在不大幅度增加计算量的前提下,显著提升特征表达的尺度鲁棒性。
R-CNN系列在单个scale的feature map做检测,尽管conv已经对scale有些鲁棒了,但是还是不够。物体各种各样的scale还是是个难题,尤其是小物体,所以有很多论文在这上面做工作,最简单的做法就是类似于数据增强了,train时把图片放缩成不同尺度送入网络进行训练,但是图片变大很吃内存,一般只在测试时放缩图片,这样一来测试时需要测试好几遍实践就慢了。
另一种是SSD的做法,在不同尺度的feature map上做检测,按理说它该在计算好的不同scale的feature map上做检测,但是它放弃了前面的low-level的feature map,而是从conv4_3开始用而且在后面加了一些conv,生成更多高层语义的feature map在上面检测(我猜想是因为这些low-level的feature map一是太大了很大的拖慢SSC最追求的速度,二是这些low-level的语义信息太差了,效果没太大提升)。所以FPN就想既利用conv net本身的这种已经计算过的不同scale的feature,又想让low-level的高分辨的feature具有很强的语义,所以自然的想法就是把high-level的低分辨的feature map融合过来。
二、论文概述
作者提出的多尺度的object detection算法:FPN(feature pyramid networks)。
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。
另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
2.1 图像金字塔

如上图所示,这是一个图像金字塔,在很多的经典算法里面都有它的身影,比如SIFT、HOG等算法。
我们常用的是高斯金字塔,所谓的高斯金字塔是通过高斯平滑和亚采样获得一些下采样图像,也就是说第K层高斯金字塔通过平滑、亚采样操作就可以获得K+1层高斯图像,高斯金字塔包含了一系列低通滤波器,其截止频率从上一层到下一层是以因子2逐渐增加,所以高斯金字塔可以跨越很大的频率范围。
总之,我们输入一张图片,我们可以获得多张不同尺度的图像,我们将这些不同尺度的图像的4个顶点连接起来,就可以构造出一个类似真实金字塔的一个图像金字塔。通过这个操作,我们可以为2维图像增加一个尺度维度(或者说是深度),这样我们可以从中获得更多的有用信息。整个过程类似于人眼看一个目标由远及近的过程(近大远小原理)。如上图所示,我们可以看到一个图像金字塔,中间是原始图像,最上边是下采样后的图像,最下边是上采样后的图像。
2.2 为什么需要构造特征金字塔
前面已经提到了高斯金字塔,由于它可以在一定程度上面提高算法的性能,因此很多经典的算法中都包含它。但是这些都是在传统的算法中使用,当然也可以将这种方法直应用在深度神经网络上面,但是由于它需要大量的运算和大量的内存。但是我们的特征金字塔可以在速度(cnn随着网络层数增加可直接得到特征金字塔)和准确率之间进行权衡,可以通过它获得更加鲁棒的语义信息,这是其中的一个原因。
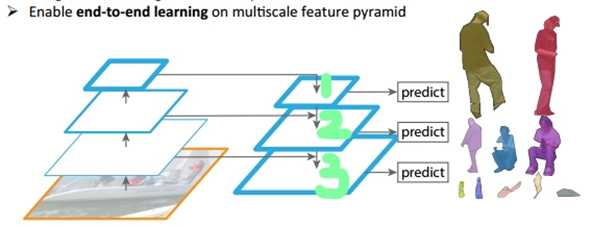
如上图所示,我们可以看到我们的图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。图中我们在第1层(请看绿色标注)输出较大目标的实例分割结果,在第2层输出次大目标的实例检测结果,在第3层输出较小目标的实例分割结果。检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。
三、论文详解
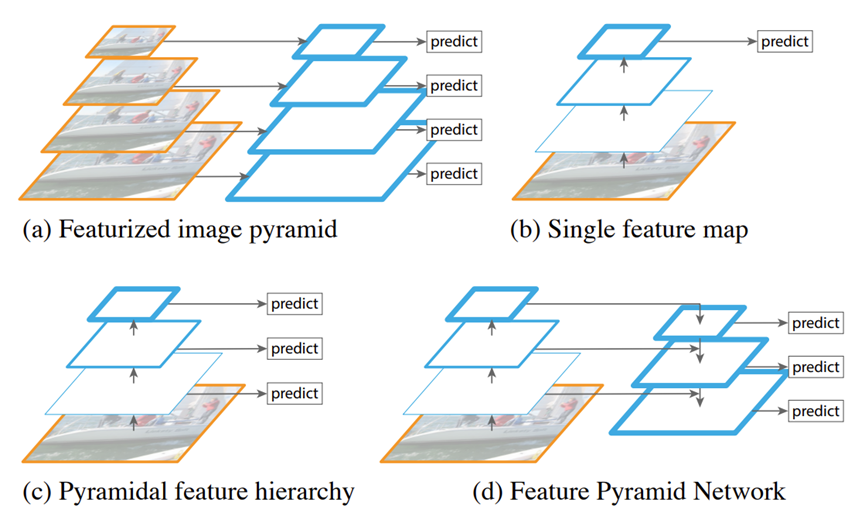
上图展示了四种利用特征的形式:
(a) 对图像金字塔的每一层提取特征,应用检测算法只要在任意层检测到了目标,都算检测成功。但是,在实际应用中,基于神经网络的方法本身就非常耗时,如果再使用多个尺度的图像特征进行训练和测试,时间和内存的开销就更大了,因此这种方法很少被真正使用。
(b) 像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。卷积神经网络本身也具有金字塔结构,在特征图的不同层上,同样大小的检测窗口在原图的感受野的尺度是不同的。
(c) 像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。但这也存在一个问题,特征图不同层次特征的表达能力不同,浅层特征主要反映明暗、边缘等细节,深层特征则反映更丰富的整体结构。单独使用浅层特征是无法包含整体结构信息的,会减弱特征的表达能力。
(d) 因为深层特征本身就是由浅层特征构建的,所以天然包含了浅层特征的信息,一个很自然的想法是,如果再把深层特征融合到浅层特征中,就兼顾了细节和整体,融合后的特征会具有更为丰富的表达能力。本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
如下图, 上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。而下面一个网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面有这两种结构的实验结果对比,非常有意思,因为之前只见过使用第一种特征融合的方式。

作者的主网络采用ResNet。
作者的算法大致结构如下图所示:一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。
图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
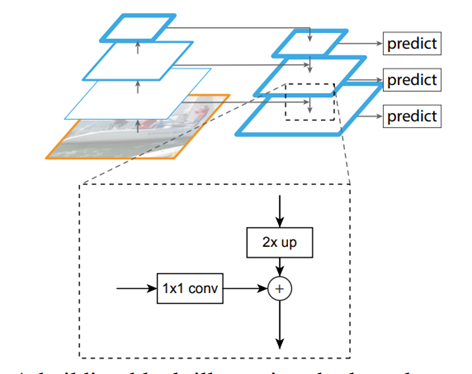
自下而上的过程实质上是卷积网络前向传播的过程。比如ResNet网络在前向传播的过程中,包含若干个stride=1和stride=2的卷积,经过stride=1的卷积后,特征图的尺度保持不变,经过stride-2的卷积后,特征图的尺度缩小为原来的1/2。我们称连续的尺度不变的各个特征图处于一个网络阶段,对于每个阶段,最后一层特征图包含了这个阶段中最具表达能力的特征。
FPN构造特征金字塔时,选取每个阶段的最后一层特征图构建层级结构。对于ResNet网络而言,用来构造特征金字塔的特征图,就是每个阶段的最后一个残差块(residual block)。直接选取各个特征图的通道数是不同的,这是因为负责后续处理的网络需要在不同层的特征图上滑窗截取特征,这就要求所有层的特征图具有相同的深度(通道数),为了使得各个特征图具有相同的深度,FPN对选取的每个特征图增加一次1×1的卷积操作,以此转化成统一的通道数。
分别在conv2、conv3、conv4、conv5对应阶段的最后一个残差块上使用一个1×1卷积变换成d维通道(比如d=256),并分别标记为C1、C2、C3、C4。因为相邻两个阶段之间的特征图有2倍的尺度缩放,所以C1、C2、C3、C4,的宽、高尺度分别为原图的1/4、1/8、1/16和1/32,深度全都等于d维。此处之所以没有选择convl,是为了避免过大的内存消耗,如果不考虑内存的问题,使用convl也是没有问题的。
自上而下的过程实质上是通过把上层的特征图进行尺度变换,来构造新的特征图,新的特征图需要和下层的特征图保持一致的尺度,从而保证特征图可以融合在一起。在长、宽方向上,采用向上采样(upsample)的方法,和下层特征图的宽、高拉成一样大小;在深度方向上,通过一个1×1的卷积,把上层特征图的深度压缩到和下层特征图的深度相同。综合使用上采样操作和1×1的卷积 操作,就从上层特征图构造出了一个和下层特征图尺度完全一致的新的特征图。
经过自上而下的过程,基于上层特征图构建的新特征图和原始的下层特征图具有了同样的尺度。如图2所示,先把新的特征图和原始的下层特征图中每个对应元素相加(element-wise add),就实现了上层特征和下层特征的融合,再把融合后的每层特征图都输出为一个深度为d(比如d=256)的新特征图。
为了消除两个特征图对应元素直接相加可能带来的融合不充分的问题,FPN在融合之后的特征图上使用一个3×3卷积进行平滑处理,从而得到一个融合得更加充分的特征图。至此,完成了特征金字塔的构建,特征金字塔每一层特征图都融合了低维和高维的特征,各层的长、宽尺度不同,但通道数相同。后续任务的网络分别在特征金字塔的各个特征图上进行特征截取,就能得到多个尺度的特征。 FPN是使用卷积神经网络构建特征金字塔,用于多尺度目标检测的通用方法,可以广泛地应用于候选框的筛选(RPN)、Fast R-CNN 检测等场景中,如图2所示。多组实验结果表明 2xup,在不明显增加计算开销和内存开 lxl conv销的情况下,FPN能够明显提升多尺度目标检测算法的性能。
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
四、FPN框架解析
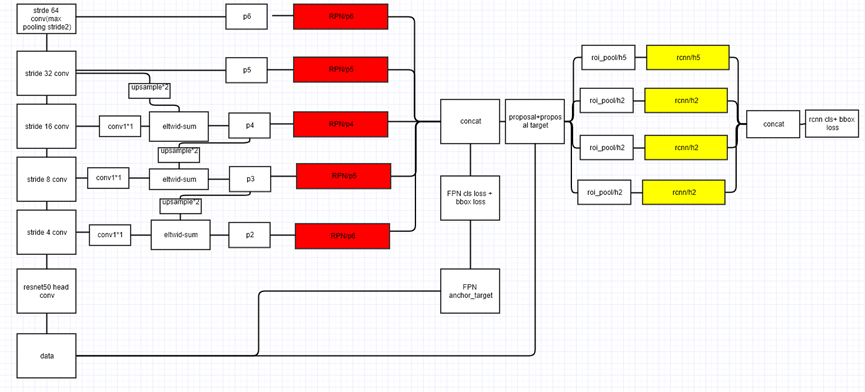
利用FPN构建Faster R-CNN检测器步骤:
首先,选择一张需要处理的图片,然后对该图片进行预处理操作;
然后,将处理过的图片送入预训练的特征网络中(如ResNet等),即构建所谓的bottom-up网络;
接着,如下图所示,构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作,最后);
接着,在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作;
接着,将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(固定为7x7的特征);
最后,在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层;
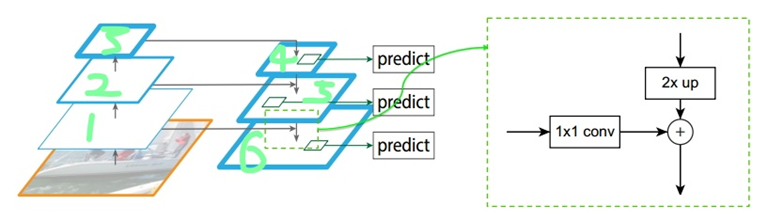
注:层1、2、3对应的支路就是bottom-up网络,就是所谓的预训练网络,文中使用了ResNet网络;由于整个流向是自底向上的,所以我们叫它bottom-up;层4、5、6对应的支路就是所谓的top-down网络,是FPN的核心部分,名字的来由也很简单。
五、为什么FPN能够很好的处理小目标?
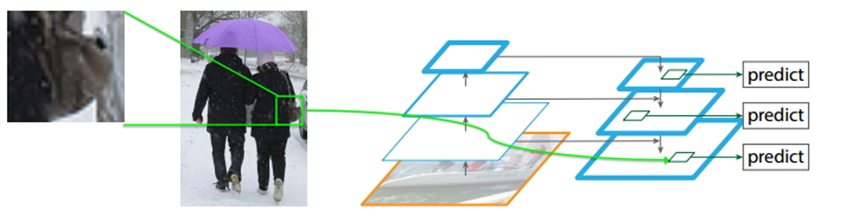
如上图所示,FPN能够很好地处理小目标的主要原因是:
FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息);
对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息),如图中所示;
六、FPN总结
FPN 构架了一个可以进行端到端训练的特征金字塔;
通过CNN网络的层次结构高效的进行强特征计算;
通过结合bottom-up与top-down方法获得较强的语义特征,提高目标检测和实例分割在多个数据集上面的性能表现;
FPN这种架构可以灵活地应用在不同地任务中去,包括目标检测、实例分割等;
以下是FPN网络的架构细节图:

















 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











