







一般生成影像的需要三个component:
- **Encoder:**对文字和图像做embedding
- **Generation Model:**Encoder的输入作为输出,然后输出作为中间结果
- **Decoder:**对中间结果做Decode
Encoder:最常用的就是text encoder,其实就是NLP了,像gpt、bert等等(encoder对生成的图片质量影响很大)
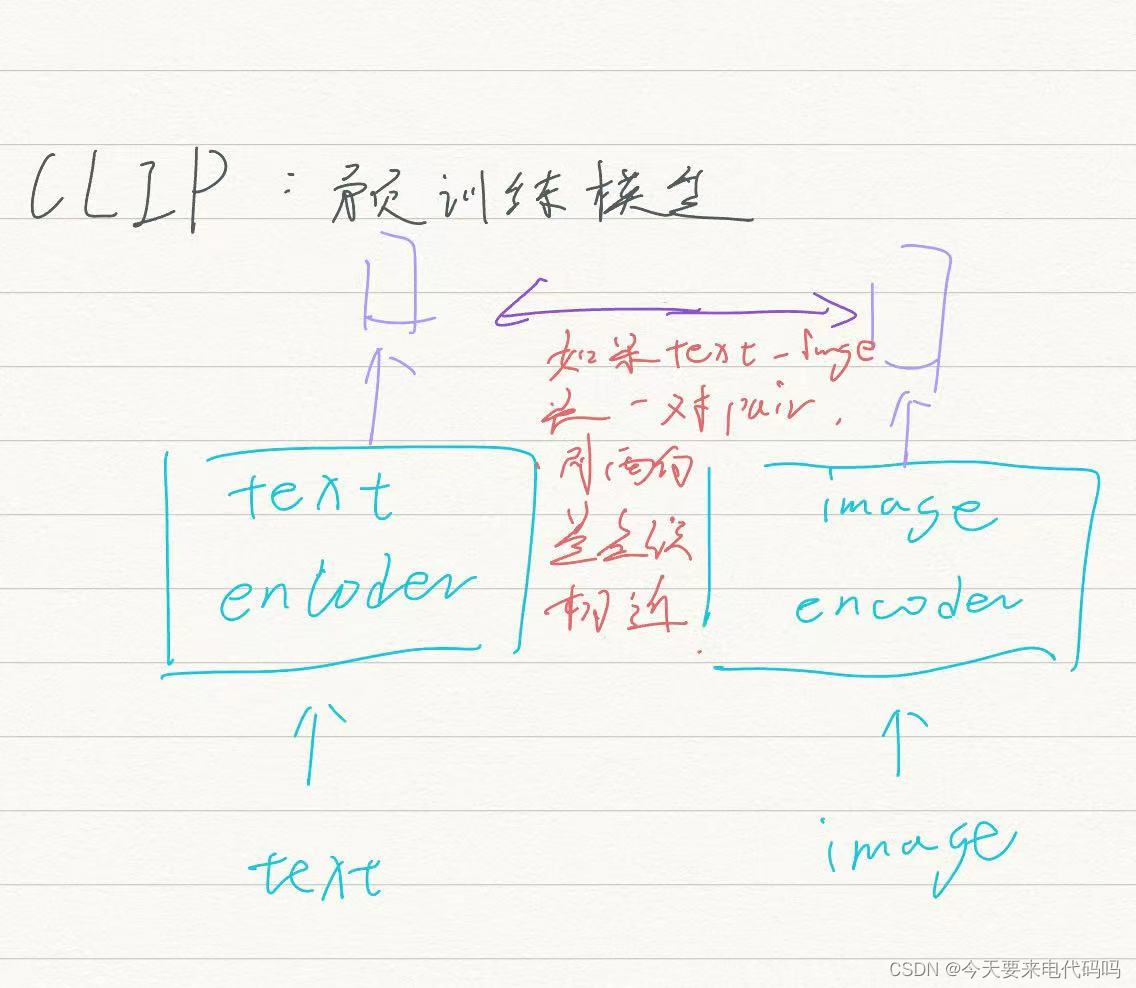
常用的encoder有CLIP(预训练模型),属于一对pair的text和image的向量相近,否则相反
Decoder:不需要标签数据,只需要原始图片即可
Decoder根据中间产物进行训练
● 中间产物是小图片:我们就把原始图片缩小,然后组成一对pair丢给Decoder进行训练
● 中间产物是representation,我们做如下流程:
image->encoder->representation->decoder->image(这个image和原始image距离越近越好)
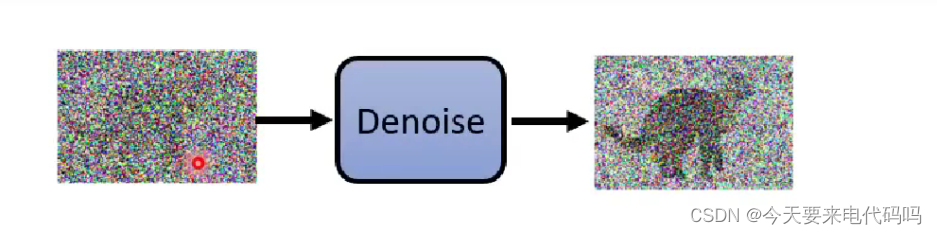
Diffusion Model运作流程(生成流程):
-
首先通过高斯噪音分布进行取样,得到一个完全噪音的图像表示

-
通过denoise操作,较少噪音
-
不断重复下去直到获得最终的图像
Denoise操作并不是直接生成一张去噪后的图像,而是通过网络预测添加的噪音,然后再减去这个噪音
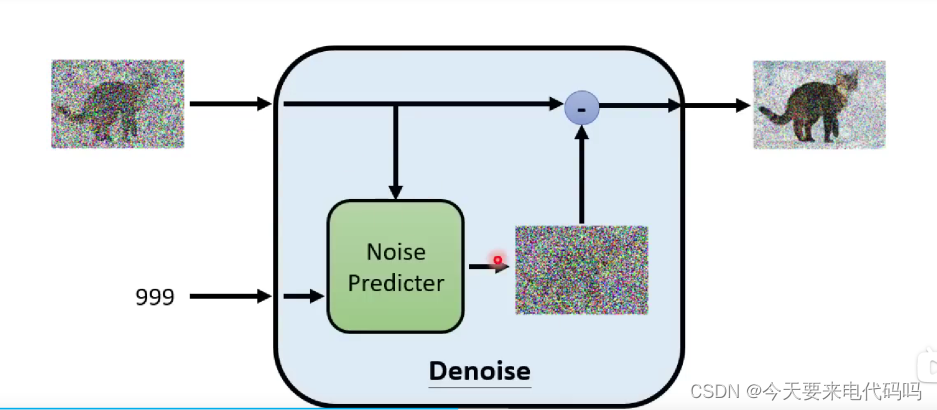
那么关键点就在于如何训练这个Noise Predicter了
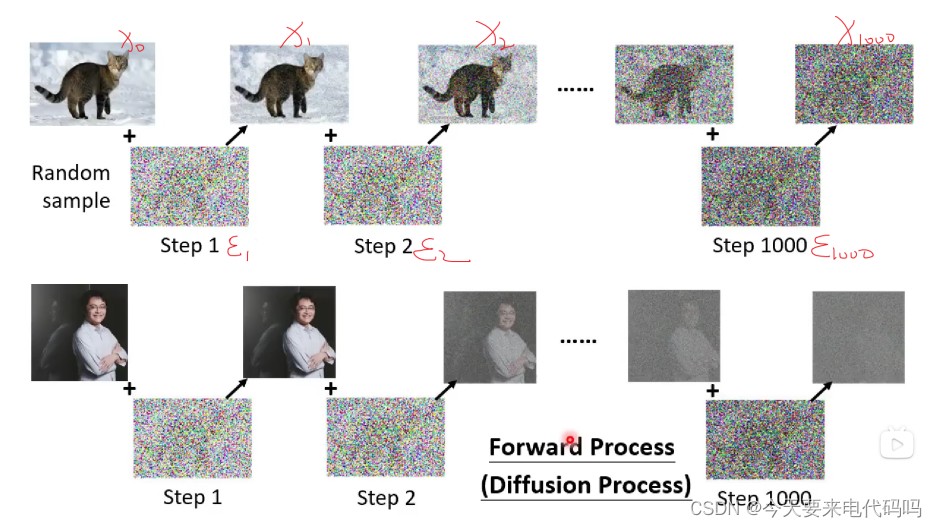
Noise Predicter训练过程:
-
从网络上得到图片,然后做diffusion process,这样我们就有了noise信息了
-
我们利用( ϵ t , x t , t e x t , t \epsilon_{t}, x_{t}, text, t ϵt,xt,text,t )来进行训练
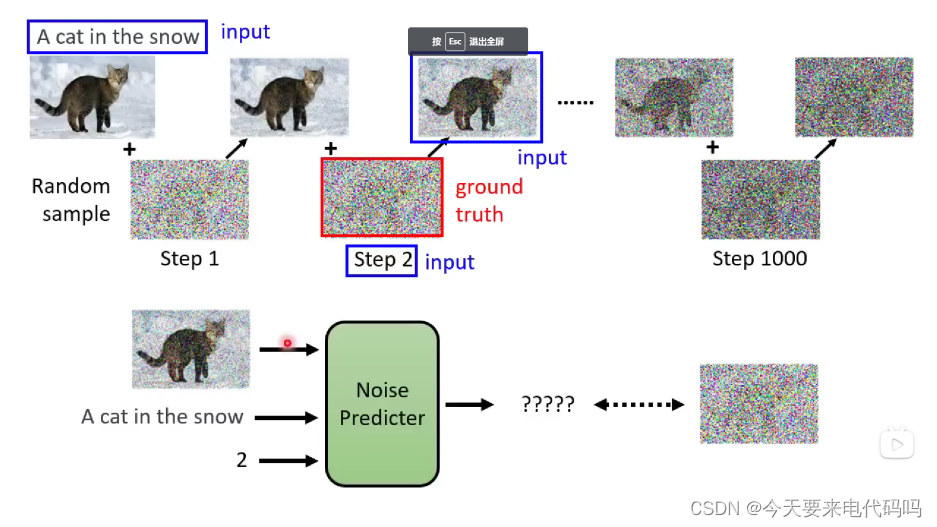
Diffusion Model的训练过程:

x
0
x_{0}
x0是我们从世界图片样本
q
(
x
0
)
q(x_{0})
q(x0)中抽样得到的图片;t也是1~T的一个数字;
ϵ
\epsilon
ϵ是生成的高斯噪声,是我们要加在图片上的。
我们训练的目标就是让我们预测的
ϵ
0
\epsilon_{0}
ϵ0与实际
ϵ
\epsilon
ϵ更相近
TODO:数学推导















 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









