







 本文讲述了在Android项目中如何应对大数据处理需求,选择使用A72大核+算法优化,同时探讨了CMake编译优化的困惑与解决,包括Debug与Release编译下-Ofast配置失效的问题。作者发现需修改NDK中的android.toolchain.cmake,最终手动指定-Ofast提升算法性能。
本文讲述了在Android项目中如何应对大数据处理需求,选择使用A72大核+算法优化,同时探讨了CMake编译优化的困惑与解决,包括Debug与Release编译下-Ofast配置失效的问题。作者发现需修改NDK中的android.toolchain.cmake,最终手动指定-Ofast提升算法性能。
问题背景
在近期的一个Android App项目中,遇到了需要快速处理大批量数据的需求。对于上述需求,考虑使用目标SOC上的硬件加速单元进行加速,如本项目使用RockChip的RK3399 SOC,搭载了2颗A72大核,主频默认1.8Ghz,以及四颗A53小核,主频最高默认1.4GHz,由于是ARM V8架构,还搭载了128bits的SIMD的NEON协处理器。此外还有一颗Mali T860 MP4,最高主频800MHz的GPU,支持OpenGL ES3.2(最高)和OpenCL 1。因此本项目就有三个备选方案可以尝试:
- 使用A72大核+算法优化的方案,该方案实现难度较低,同时可以把代码算法中优化中的一部分交给编译器来做(之后要着重说的,本项目最后也采用了此方案)
- 使用Neon协处理,对数据进行并行处理,但是由于本项目中处理数据的方式不仅有运算量大的要求,还存在对内存的分散写入,因此不适合使用该方案进行加速。
- 使用OpenGL中的Compute Shader或OpenCL进行加速,但是由于MaliT860该SOC不支持ComputeShader,同时OpenCL对目标算法的性能优化有限,因此该方案也被弃用。
确定方案后,迎面而来的又是一个新的问题:
在算法定型后,仍有两条路可以进行优化,一是手动进行汇编优化,着重优化循环控制、Cache和寄存器变量复用、流水控制、内存页优化等;二是将代码在高级语言层面进行时间复杂度优化后,剩下的交给强大的Clang编译器进行。
对于前者,经过手动优化,数据吞吐量从20MByte/s提升到150MByte/s,就在笔者准备使用编译器自动优化时发现了问题。
在Android Studio中,配置了CMake&Ninja&Clang进行Native层的编译,在CMakeList.txt中对项目的编译参数进行了配置,分别测试了 -O0,-O1,-O2, -Os, -O3和-Ofast对算法运行效率的影响。在测试过程中发现,处于Debug编译时,无论编译优化选项为任何配置,均不生效,即都为-O0的速度,同时由于启用了debug -g的选项,运行速度约只有17MByte/s。
在配置为Release编译后,系统吞吐率得到了提高,能达到约100Mbyte/s,但是仍发现配置的编译优化选项并不生效。便对此展开了研究。
参考文章中的介绍,依次分析过程文件。https://blog.csdn.net/shift_wwx/article/details/84770716 https://blog.csdn.net/shift_wwx/article/details/84770716
https://blog.csdn.net/shift_wwx/article/details/84770716
分析过程中发现了一个奇怪的现象,在CMakeList中指定了使用-Ofast优化选项,如图
![]()
但是在最后的build.ninja中发现在配置的 -Ofast之后紧跟了一个-O2

在编译参数中,多次配置一个选项 如-O0 -O2,只有最后一个配置选项会生效,也就验证了为什么无论如何改变CMakeList中的参数,最后的效果都没有变化的现象了。于是找到这个-O2是在哪里被拼接到编译指令中的也就可以解决问题了。
通过一步步分析,发现所有的编译指令是通过CMakeCache控制生成的,而CMakeCache中的配置又是由.ExternalNativeBuild目录中的cmake_build_command.txt配置生成的,继续看发现其连关联了AndroidSDK中NDK中的android.toolchain.cmake文件
查看文件中内容发现了端倪(此处文件已经被修改,原本-O2的部分已经被修改为了-Ofast)
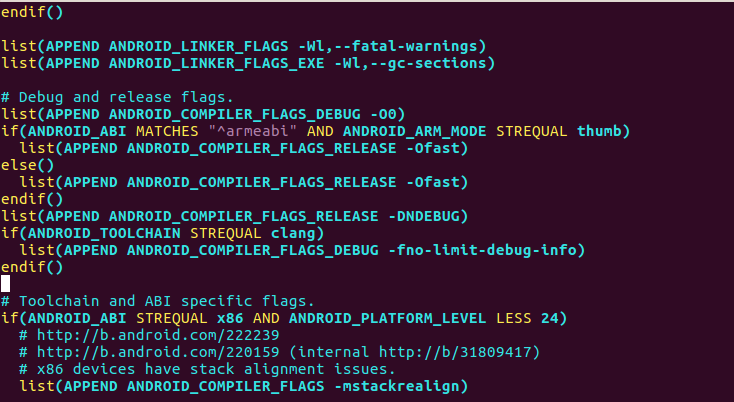
再次编译

-O2选项消失,我们手动指定的-Ofast生效
生效后算法吞吐率提升到110MByte/s,可以看到哪怕已经使用了-Ofast的方式编译,仍不如手动进行优化。
总结:
因此若要手动配置Android Native中的编译优化配置,需要在对应的SDK-NDK中修改,可以手动指定需要的编译优化配置(如上图中修改的-Ofast部分),也可直接去掉“-O2”的配置,在CMakeList中手动添加即可。

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









