







 本文介绍了如何使用PyOpenGL和PBO(Pixel Buffer Object)以异步方式高速保存OpenGL渲染的像素数据到内存,避免了glReadPixels造成的渲染管道阻塞。通过对比单个PBO和异步双PBO的方法,阐述了异步PBO的优势在于能够实现GPU和CPU的并行处理,从而提高效率。此外,文章还提到了在使用PyOpenGL过程中遇到的glReadPixels参数问题及其解决方案。
本文介绍了如何使用PyOpenGL和PBO(Pixel Buffer Object)以异步方式高速保存OpenGL渲染的像素数据到内存,避免了glReadPixels造成的渲染管道阻塞。通过对比单个PBO和异步双PBO的方法,阐述了异步PBO的优势在于能够实现GPU和CPU的并行处理,从而提高效率。此外,文章还提到了在使用PyOpenGL过程中遇到的glReadPixels参数问题及其解决方案。
用Pyopengl高速保存像素到内存(保存成图片)
最近用到Pyopengl需要将实时渲染窗口保存成array以便进一步对图片操作处理,基于对速度上的需求,采用PBO的方式。将直接glreadpixels, 单个PBO,异步双PBO分别进行速度比较,异步PBO速度最快。
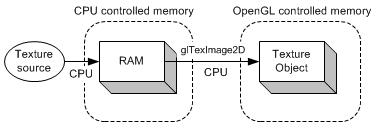
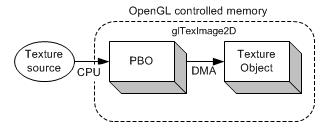
传统使用glReadPixels将阻塞渲染管道(流水线),直到所有的像素数据传递完成,才会将控制权交还给应用程序。相反,使用PBO的glReadPixels可以调度异步DMA传递,能够立即返回而不用等待。因此,CPU可以在OpenGL(GPU)传递像素数据的时候进行其它处理。
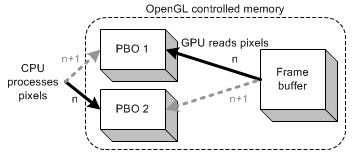
用两个PBO异步glReadPixels
例子程序也使用了两个PBO,在第n帧时,应用帧缓存读出像素数据到PBO1中,同时在PBO2中对像素数据进行处理。读与写的过程可同时进行,是因为,在调用glReadPixels时立即返回了,而CPU立即处理PBO2而不会有延迟。在下一帧时,PBO1和PBO2的角色互换。
渲染模型的代码来自dalong10
https://blog.csdn.net/dalong10/article/details/94183092
参考FBO PBO
http://blog.sina.com.cn/s/blog_4062094e0100alvt.html
1、对于直接读数据到内存,全部都是由CPU执行的,速度很慢。
对于单个PBO和异步PBO的速度差异上的理解,我的理解是:
2、对于单个PBO,传递1帧数据到CPU的时间为:帧缓存写到PBO的时间加上PBO到CPU的时间,总是先写,再读,这里CPU就要等待帧缓存写到PBO;
对于异步PBO,传递1帧数据到CPU的时间仅为PBO到CPU的这段时间,帧缓存到PBO由GPU执行,从PBO到CPU由CPU执行,两者同步执行,互不干扰,所以速度上更快了。
说实话pyopengl资料太少,有些bug根本不知道怎么改,比如glreadpixels用在PBO上的话,最后一个参数得填成0,或者c_void_p(0),如果写成None的话就会报错。上stackoverflow上查了半天没查到,上github上搜了一下有人用过,最后才改出来…,这个坑填了两天。
OpenGL.error.GLError: GLError(
err = 1282,
description = b'\xce\xde\xd0\xa7\xb2\xd9\xd7\xf7',
baseOperation = glReadPixels,
cArguments = (
0,
0,
800,
600,
GL_RGB,
GL_UNSIGNED_BYTE,
array([[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[...,
)
)
下面是C++实现:
// "index" is used to copy pixels from a PBO to a texture object
// "nextIndex" is used to update pixels in the other PBO
index = (index + 1) % 2;
nextIndex = (index + 1) % 2;
// bind the texture and PBO
glBindTexture(GL_TEXTURE_2D, textureId);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pboIds[index]);
// copy pixels from PBO to texture object
// Use offset instead of ponter.
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, WIDTH, HEIGHT, GL_BGRA, GL_UNSIGNED_BYTE, 0);
// bind PBO to update texture source
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pboIds[nextIndex]);
// Note that glMapBuffer() causes sync issue.
// If GPU is working with this buffer, glMapBuffer() will wait(stall)
// until GPU to finish its job. To avoid waiting (idle), you can call
// first glBufferData() with NULL pointer before glMapBuffer().
// If you do that, the previous data in PBO will be discarded and
// glMapBuffer() returns a new allocated pointer immediately
// even if GPU is still working with the previous data.
glBufferData(GL_PIXEL_UNPACK_BUFFER, DATA_SIZE, 0, GL_STREAM_DRAW);
// map the buffer object into client's memory
GLubyte* ptr = (GLubyte*)glMapBuffer(GL_PIXEL_UNPACK_BUFFER, GL_WRITE_ONLY);
if(ptr)
{
// update data directly on the mapped buffer
updatePixels(ptr, DATA_SIZE);
glUnmapBuffer(GL_PIXEL_UNPACK_BUFFER); // release the mapped buffer
}
// it is good idea to release PBOs with ID 0 after use.
// Once bound with 0, all pixel operations are back to normal ways.
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0);
下面是Python实现方式:
#前半部分渲染模型的代码来自 @dalong10 这个博主
import glutils # Common OpenGL utilities,see glutils.py
import sys, random, math
import OpenGL
from OpenGL.GL import *
from OpenGL.GL.shaders import *
from OpenGL.GLU import *
import numpy
import numpy as np
import glfw
from PIL import Image
import cv2
import time
strVS = """
#version 330 core
layout(location = 0) in vec3 position;
layout (location = 1) in vec2 inTexcoord;
out vec2 outTexcoord;
uniform mat4 uMVMatrix;
uniform mat4 uPMatrix;
uniform float a;
uniform float b;
uniform float c;
uniform float scale;
uniform float theta;
void main(){
mat4 rot1=mat4(vec4(1.0, 0.0,0.0,0),
vec4(0.0, 1.0,0.0,0),
vec4(0.0,0.0,1.0,0.0),
vec4(a,b,c,1.0));
mat4 rot2=mat4(vec4(scale, 0.0,0.0,0.0),
vec4(0.0, scale,0.0,0.0),
vec4(0.0,0.0,scale,0.0),
vec4(0.0,0.0,0.0,1.0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









