



点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群LLM的局限性
随着算法架构的革新,数据规模和数据质量、硬件计算能力的不断提高,LLM表现出来了强大的推理能力。但是,LLM是基于已有的数据进行训练的,所以LLM的知识仅限于训练数据的截止日期,无法获取真实世界最新的数据和信息,也不能对外界的进行任何的操作。
为了突破这一限制,人们提出了function call、MCP、A2A等方案增加LLM获取实时数据的能力。接下会详细介绍一下这些交互方式的内容。
function calling
function calling是OpenAI在2023年提出的功能,最初用于支持 ChatGPT 插件系统。OpenAI的模型经过训练,可以根据用户的提示检测需不需要调用用户提供的函数,并且用一个很规范的结构返回,而不是直接返回常规的文本。
这项能力使 LLM能够通过结构化输入连接到外部系统,从而突破模型固有知识边界和算力限制,从而使LLM的能力更加的智能。简单来说,function calling就是提供了一种方式,教大模型怎么样和外面的系统进行交互。

图中加入了function calling的调用过程,在向大模型提问的时候除了用户的提示词外 还加上了可用的工具函数。
在代码层面的体现,就是会带一个tools的参数,tools参数的每一项都是一个功能的函数描述,通过这个对象来向大模型描述外部函数库的功能。
response = requests.post(
"https://api.deepseek.com/v1/chat/completions",
headers=headers,
json={
"messages": [{"role": "user", "content": question.question}],
"model": "deepseek-chat",
"tools": [
{
"type": "function",
"function": {
"name": "get_current_time",
"description": "获取现在的时间",
"parameters": {
"type": "object",
"properties": {},
"required": []
},
}
},
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取今天的天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "获取天气情况的城市或者国家,比如北京、东京、新加坡"
}
},
"required": ["location"]
},
}
},
],
"tool_choice": 'auto'
}
)其中tool_choice 参数用于控制模型对函数调用的选择,有3种值:
默认值 auto:模型会依据上下文信息自主判断是否返回函数调用。
指定函数:当设置为 {"name": "your_function_name"} 时,能强制 API 返回特定函数的调用。
禁用函数调用:若设置为 "none",则强制 API 不返回任何函数调用。
大模型根据提示词和tools,判断出是否是否需要使用function calling。如果大模型推理出需要function calling, 返回返回一个带有tool_calls的结构化的响应。
{
"id": 'a48ab60a-48a7-4f7b-a09e-dd93eead3c4d',
"object": 'chat.completion',
"created": 1746185211,
"model": 'deepseek-chat',
"choices": [
{
"index": 0,
"message": {
"role": 'assistant',
"content": '',
"tool_calls": [
{
"index": 0,
"id": 'call_0_3b76f546-f8c3-4f67-93cd-9bffb62dc1bf',
"type": 'function',
"function": {
"name": 'get_current_time',
"arguments": '{}'
}
}
]
},
"logprobs": None,
"finish_reason": 'tool_calls'
}
],
"usage": {
"prompt_tokens": 80,
"completion_tokens": 17,
"total_tokens": 97,
"prompt_tokens_details": {'cached_tokens': 64},
"prompt_cache_hit_tokens": 64,
"prompt_cache_miss_tokens": 16
},
"system_fingerprint": 'fp_8802369eaa_prod0425fp8'
}Chat Server在接收到响应后,根据响应里tool_calls选择执行相应的function获得结果。然后再将function执行的结果和用户的提示词,再次发送大模型由大模型推理出结果。
// 定义get_current_time函数
def get_current_time():
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if response.status_code == 200:
result = response.json()
print("result", result)
# 检查是否有函数调用指令
if"tool_calls"in result["choices"][0]["message"]:
tool_call = result["choices"][0]["message"]["tool_calls"][0]
if tool_call["function"]["name"] == "get_current_time":
# 调用实际的函数获取当前时间
current_time = get_current_time()
# 构建新的请求数据,将函数调用的结果返回给模型
new_data = {
"messages": [
{"role": "user", "content": question.question},
result["choices"][0]["message"],
{"role": "tool", "tool_call_id": tool_call["id"], "content": current_time}
],
"model": "deepseek-chat",
"tools": tools
}
# 再次调用API获取最终回复
new_response = requests.post(
"https://api.deepseek.com/v1/chat/completions",
headers=headers,
json=new_data
)
if new_response.status_code == 200:
new_result = new_response.json()
return {"answer": new_result["choices"][0]["message"]["content"]}
else:
raise HTTPException(status_code=new_response.status_code, detail="API调用失败")
else:
return {"answer": result["choices"][0]["message"]["content"]}
else:
raise HTTPException(status_code=response.status_code, detail="API调用失败")以上,就是Function Call在调用过程中交互数据的过程。
在open AI后,Claude、Gemini 等多个模型也支持了类似机制,同时 LangChain、LlamaIndex 等框架也构建了丰富的 Tool 封装能力,使 Tool Calling 成为 LLM 应用开发的重要基础设施。
尽管 function calling功能强大,但也有以下不足:
缺乏统一标准:各大模型平台的调用机制、参数格式等不同,难以实现完全兼容;
上下文不统一:每个模型对工具行为的解释可能不同,可能出现调用失败、误判等情况;
扩展复杂度提升:当工具数量众多或有调用依赖关系时,开发者需要构建中间调度逻辑,增加了代码复杂度和维护成本;
因此,在构建大型、多工具、多数据源的 LLM 系统时,仅依赖function calling会显得吃力。
MCP
MCP(Model Context Protocol)是 Anthropic 提出的协议,它标准化了应用程序如何向大型语言模型 (LLM) 提供上下文和工具的方式。
我们可以将 MCP 理解为 AI 应用的"USB-C 接口"——就像 USB-C 为各种设备提供了标准化的连接方式,使 LLM 能够动态访问和集成以下内容:
外部数据源:如数据库、API、文档库等,为 LLM 提供实时或历史数据。
工具和服务:如计算工具、搜索引擎、第三方服务等,扩展 LLM 的功能。
上下文管理:动态维护 LLM 的对话上下文,确保连贯性和一致性。
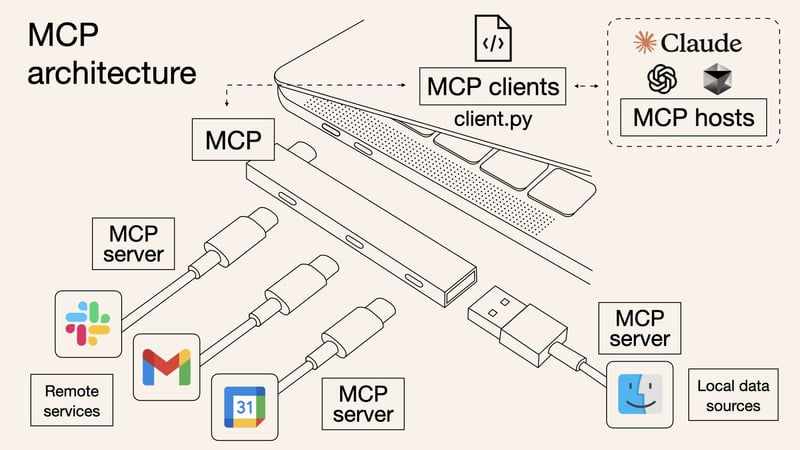
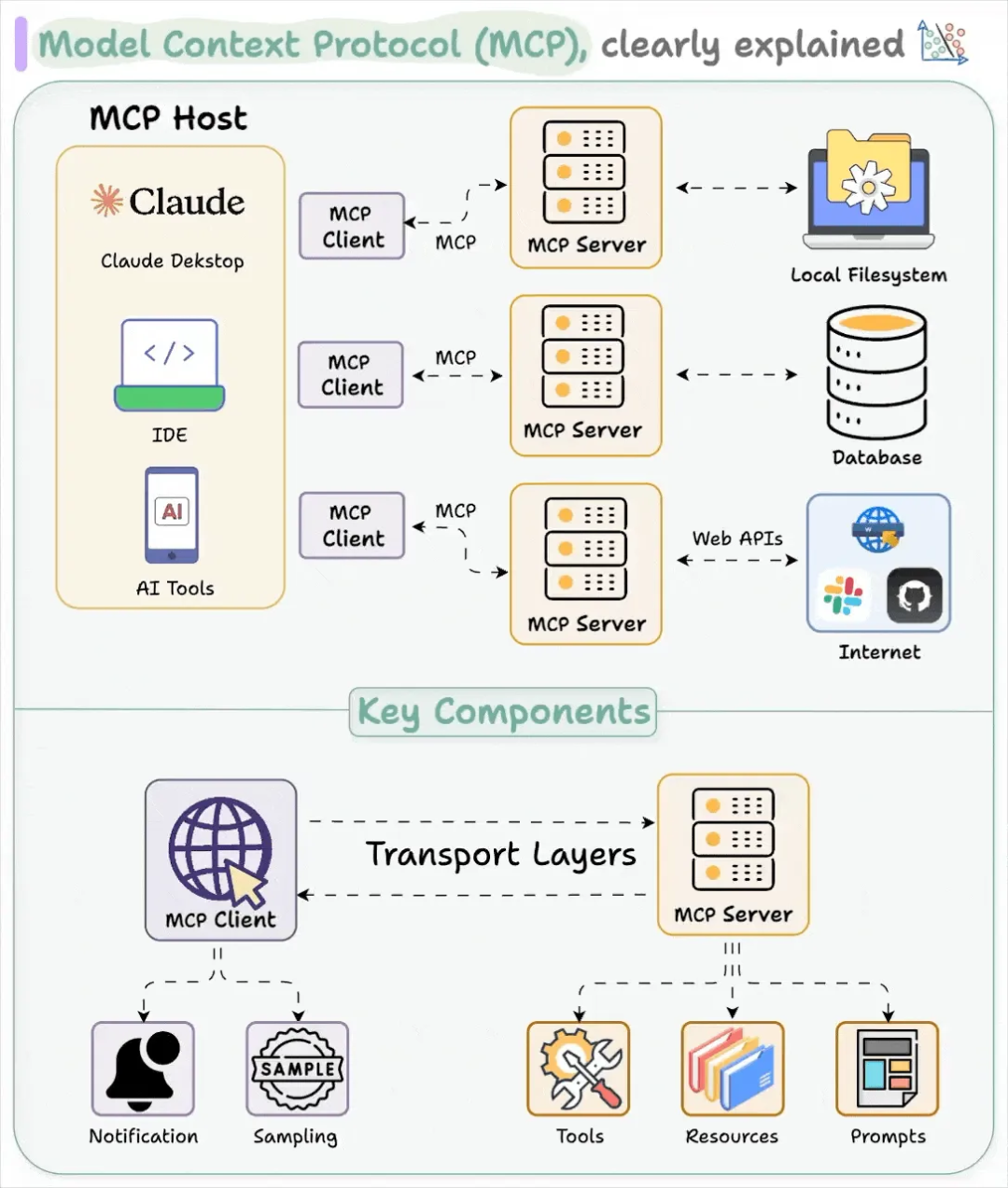
MCP 的架构由四个关键部分组成:
MCP 主机(Host):主机是期望从服务器获取数据的人工智能应用,例如Claude Desktop、IDE 或 AI 工具等。
MCP 客户端(Client):客户端是主机与服务器之间的桥梁。它与服务器保持1:1的连接,负责消息路由、能力管理、协议协商和订阅管理等。
MCP 服务器(Server):服务器是提供外部数据和工具的组件。它通过工具、资源和提示模板为大型语言模型提供额外的上下文和功能。例如,一个服务器可以提供与Gmail、Slack等外部服务的API调用。
基础协议(Base Protocol):基础协议定义了主机、客户端和服务器之间如何通信。它包括消息格式、生命周期管理和传输机制等。
MCP的优点:
一次对接,多端复用:Server 写一次,任何 Client 可用
本地优先:敏感数据留在端侧,满足合规
天然多步:Server 可内部再调用其他 Server,形成链式调用
生态累积:社区已有大量开源 Server,可即插即用
如果说MCP关注的是如何让LLM标准化地"使用工具",那么下一步,自然就是如何让Agent之间标准化地"相互调用"。
A2A
Agent to Agent(A2A)是 Google 于2025 年 4 月 9 日推出的一种开放协议,旨在让不同框架和供应商的 AI Agents 能够互相通信和协作。A2A 的目标是建立一个通用的通信语言,让 Agents 能够发现彼此、展示能力、协调任务,并在安全的环境中合作。
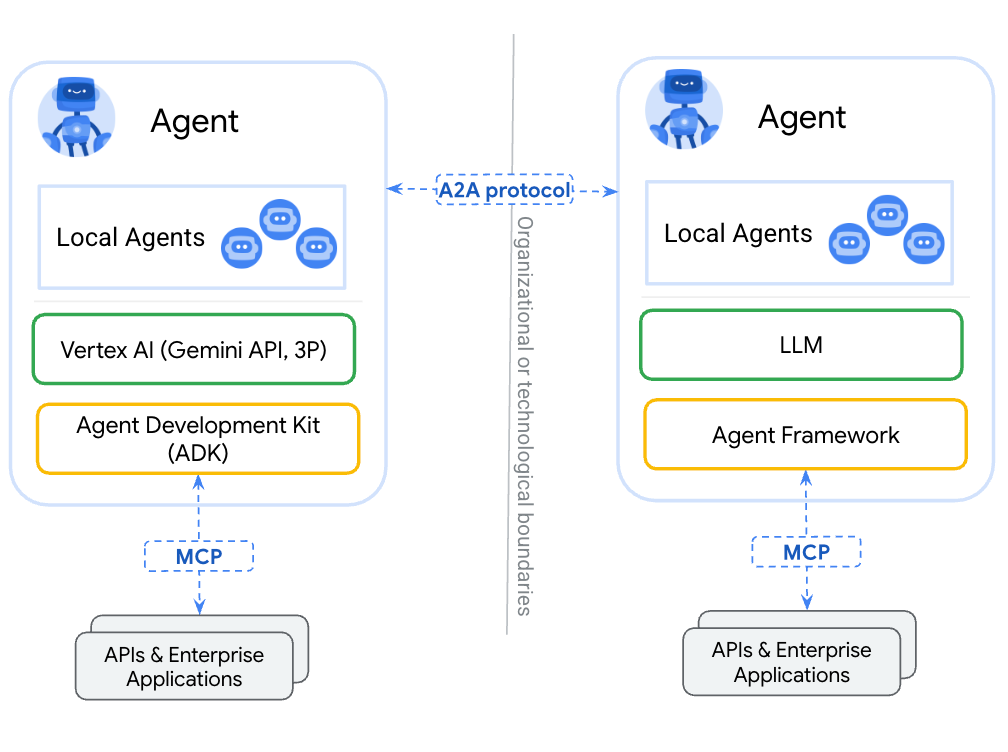
A2A协议与MCP是互补而不替代关系,A2A负责解决Agent间的通信问题,MCP解决的是Agent与工具间的通信问题。
A2A核心架构
A2A协议的核心是建立两类智能体之间的通信,Client Agent与Remote Agent的"对话模型"。
Client Agent:负责接收用户请求、制定具体任务,并向远程代理提出需求(比如"帮我订会议室")
Remote Agent:根据接收到的任务,执行相应操作或产出结果(比如会议室预订系统AI)
每个智能体需要具备以下的核心组件:
Agent Card:是一个JSON 文件,用于描述该智能体的能力(capabilities/skills)以及身份认证机制。官方建议将AgentCard托管在Agent服务的基础URL下的特定路径:"https:///.well-known/agent.json",客户端通过简单的 HTTP Get请求获取此文件,了解 Agent 功能并选择合适的合作伙伴。也可以通过私有注册中心 (Registry)、Agent 目录 (Catalog) 或市场 (Marketplace) 来发现和管理 Agent Card。
标准消息与任务结构 (JSON-RPC 2.0) :所有通信基于 JSON-RPC 2.0,定义了 Task (核心单元)、Message (交互)、Part (内容单元)、Artifact (产物) 等标准结构。
多内容类型支持:通过 TextPar, FilePart, DataPart支持文本、文件、结构化 JSON 等多种内容。
流式通信 (SSE):通过 tasks/sendSubscribe 和 tasks/resubscribe 实现 Server-Sent Events,实时推送任务状态和产物。
推送通知(Webhook):通过tasks/pushNotification/set配置,Agent 可主动将更新推送到客户端指定的 URL。
统一的任务管理与生命周期:定义了清晰的任务状态(TaskState)流转。
认证与安全机制:支持在AgentCard和推送配置中声明认证需求。
通用库与示例实现 :提供了Python和JS/TS的通用库及多种框架(ADK, CrewAI, LangGraph, Genkit, LlamaIndex, Marvin, Semantic Kernel)的集成示例。
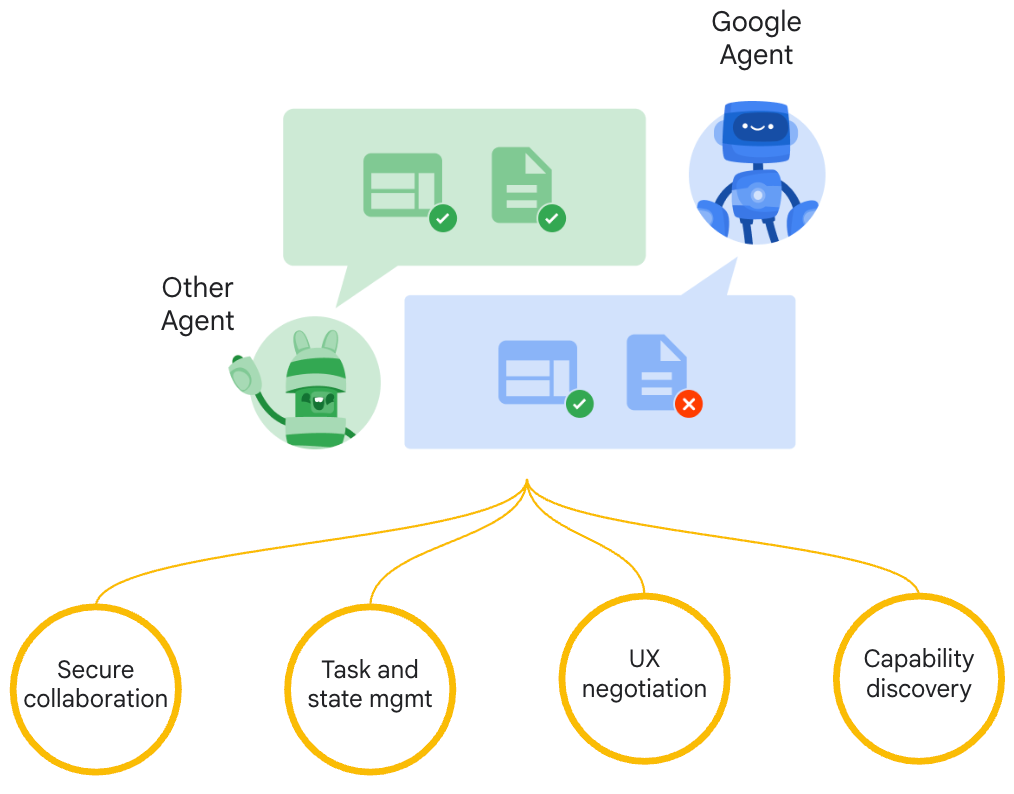
这些机制共同保证了协议的互操作性、灵活性和实际落地能力。
A2A的工作流程
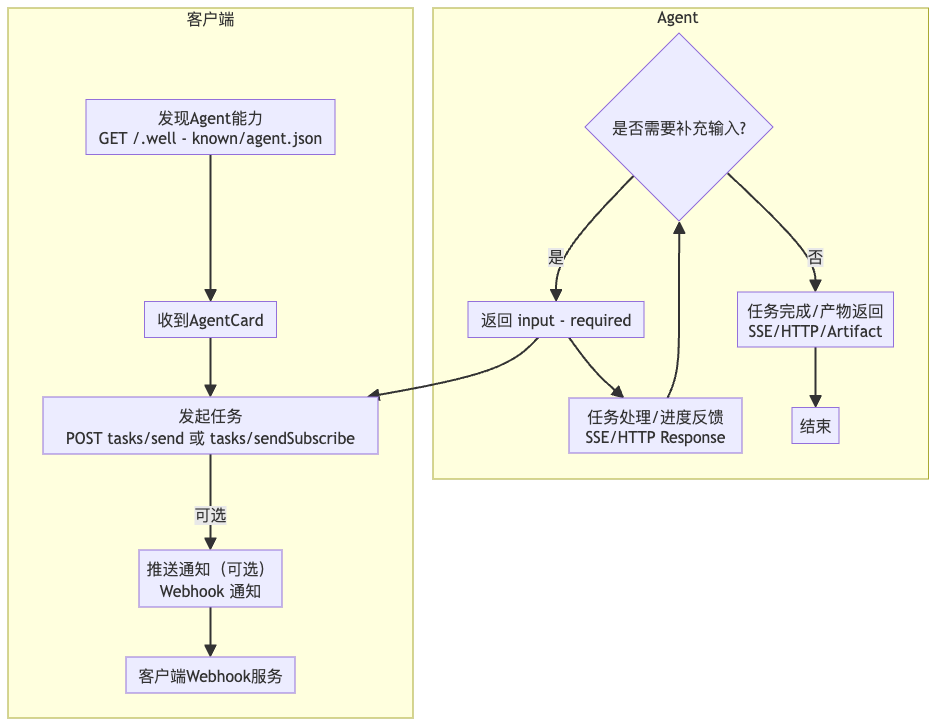
Agent 发现(Discovery):客户端获取目标 Agent 的 AgentCard(/.well-known/agent.json),了解其能力。
任务发起(Initiation):客户端调用tasks/send(同步)或tasks/sendSubscribe (异步流式)发起任务。
任务处理与状态流转 (Processing) :
Agent状态从submitted->working。
若需用户输入,变为input-required,等待客户端再次调用 tasks/send。
通过SSE(对sendSubscribe)推送状态(TaskStatusUpdateEvent) 和产物(TaskArtifactUpdateEvent)。
任务最终进入终态(completed, failed, canceled)。
任务查询与管理 (Query&Management):客户端可调用tasks/get查询状态,tasks/cancel取消任务,tasks/resubscribe重新订阅流。
推送通知(Push Notification, 可选):若客户端配置了Webhook,Agent可主动推送状态更新。
任务产物(Artifacts):任务完成后返回结果,支持多种内容类型。
三者的对比
纬度 | function calling | MCP | A2A |
|---|---|---|---|
关注点 | 模型<->单工具 | 模型<->多工具 | Agent <->Agent |
通信模式 | 单次RPC | 双工JSON-RPC/webSocket | HTTP+SSE/gPRC-stream |
扩展 | M x N | M + N | K(agent数量) |
调用 | 应用层的显式排列 | mcp server内部可递归 | 异步的任务订阅 |
适用场景 | 单Agent扩能。适合给单一大模型助手增添技能 | 工具/数据整合。适合需要整合多数据源、工具的复杂应用,尤其在企业环境下 | 多Agent协作。适合复杂任务拆解给多个AI智能体的场景 |
三条协议并非此消彼长,而是逐层补位:
Function Calling 让模型先"动手"使用工具;
MCP 让所有手都能用同一"插口"使用不同的工具,提升了使用工具的效率
A2A 让多双手排成流水线、真正高效协作,共同完成复杂任务。
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
“分享、点赞、在看” 支持一波👍

















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









