







浅识神经网络在信用评级上的应用
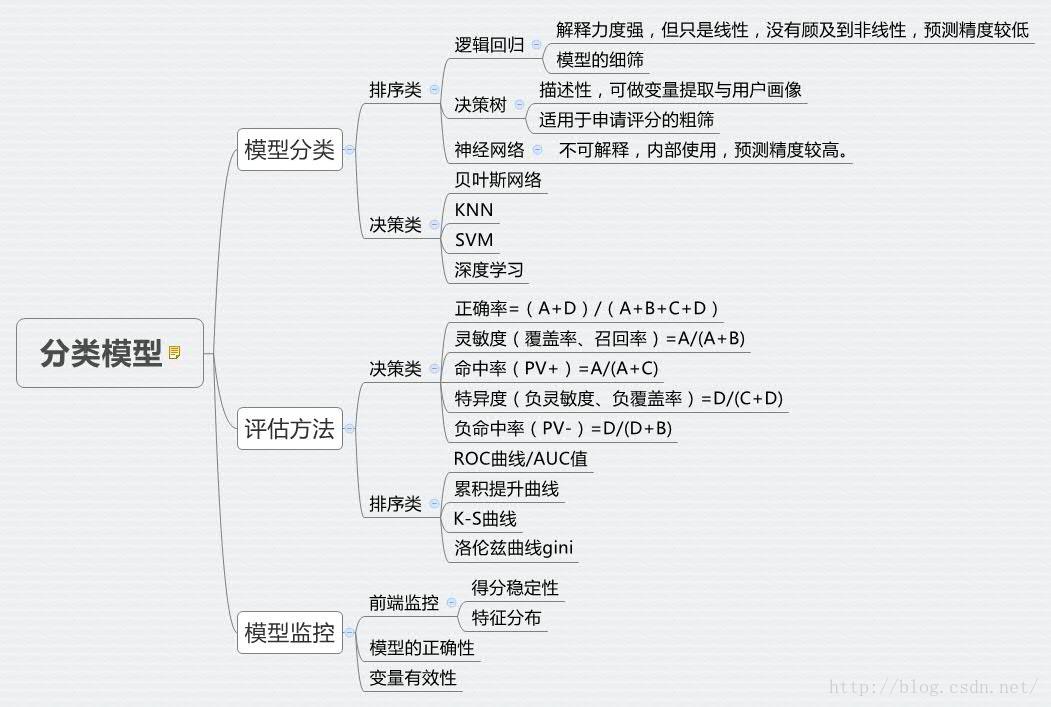
第一部分:常用风控分类模型
第二部分:一般企业对信用评级的要求及医疗行业信用评级的假想
一、一般企业
1.管理风险:金融机构在为中小企业提供贷款时将面临很大的不确定性和风险,因此在授信前必须对其进行信用评级和风险分析评估
2.成本评估:金融机构需要建立一套完整有效的信用评级机制,来审定中小企业的贷款风险,以帮助作出正确的信贷决策,降低贷前调查和贷后监管的成本
3.企业能力评估:信用评级指标体系的建立应当立足于中小企业本身特点和发展规律,合理并全面的反映影响评价对象信用的所有因素,遵循一致性,系统性,可比性和可测性等原则,从而形成客观,科学和公正的评估标准和评级方法
二、医疗行业
1.管理风险:确定提供贷款方究竟是政府(含银行),还是医院自资,还是第三方金融机构?
2.成本评估:1)医院自身评估 2)患者经济能力评估 3)数据源?数学模型?
3.医院评估:1)医院等级->医院可承受的处理相关疾病的能力 2)科室分类
第三部分:信用评级一般方法
1.专家判断法:突出的优点是具有较好的灵活性,以及在处理定性指标上的优势, 但是存在着不连续性和主观性,评级效率较低、 成本较高
2.财务比率分析:是属于古典信用分析评估方法,是将各项财务指标作为一个整体,系统、综合、全面地对贷款人财务状况进行分析、评价
3.数学建模:基于较为严谨的统计模型分析方法,是根据历史数据库来构建概率统计模型,主要是一些判别分析模型、违约概率度量模型和违约损失率度量模型
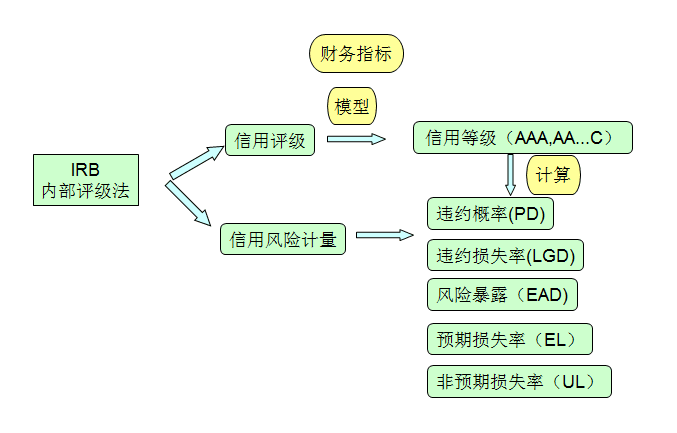
4.IRB:
第四部分:浅识神经网络及其企业应用
1.基本原理
三层
四层
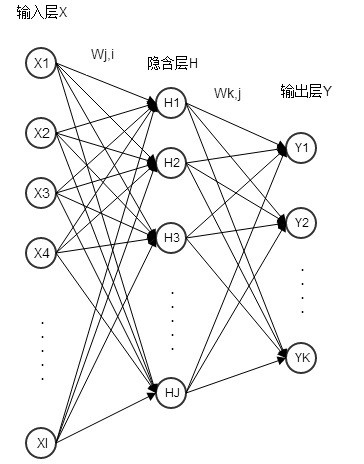
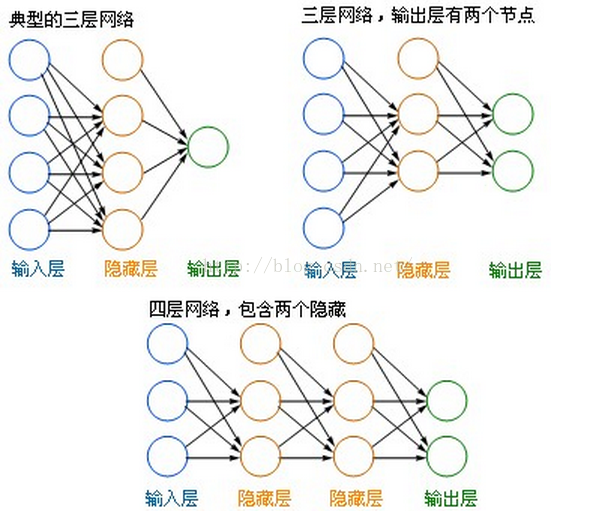
1)左边蓝色的圆圈叫“输入层”,中间橙色的不管有多少层都叫“隐藏层”,右边绿色的是“输出层”。
2)每个圆圈,都代表一个神经元,也叫节点(Node)。
3)输出层可以有多个节点,多节点输出常常用于分类问题。
4)理论证明,任何多层网络可以用三层网络近似地表示。
5)一般凭经验来确定隐藏层到底应该有多少个节点,在测试的过程中也可以不断调整节点数以取得最佳效果。
计算方法:
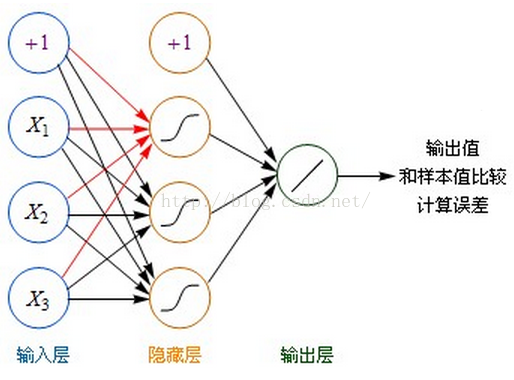
- 虽然图中未标识,但必须注意每一个箭头指向的连线上,都要有一个权重(缩放)值。
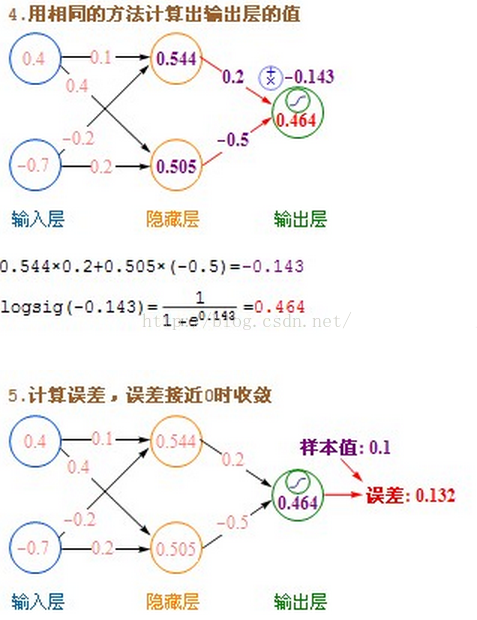
- 输入层的每个节点,都要与的隐藏层每个节点做点对点的计算,计算的方法是加权求和+激活,前面已经介绍过了。(图中的红色箭头指示出某个节点的运算关系)
- 利用隐藏层计算出的每个值,再用相同的方法,和输出层进行计算。
- 隐藏层用都是用Sigmoid作激活函数,而输出层用的是Purelin。这是因为Purelin可以保持之前任意范围的数值缩放,便于和样本值作比较,而Sigmoid的数值范围只能在0~1之间。
- 起初输入层的数值通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值和样本值作比较,计算出误差,这个过程叫前向传播(Forward Propagation)。
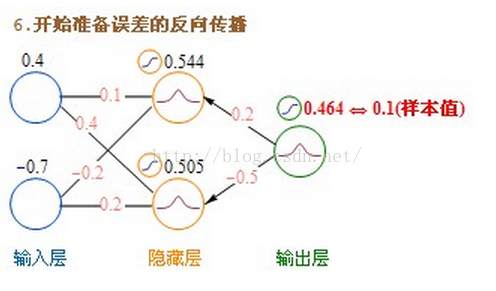
使用梯度下降的方法,要不断的修改k、b两个参数值,使最终的误差达到最小。神经网络可不只k、b两个参数,事实上,网络的每条连接线上都有一个权重参数,如何有效的修改这些参数,使误差最小化,成为一个很棘手的问题。从人工神经网络诞生的60年代,人们就一直在不断尝试各种方法来解决这个问题。直到80年代,误差反向传播算法(BP算法)的提出,才提供了真正有效的解决方案,使神经网络的研究绝处逢生。
BP算法是一种计算偏导数的有效方法,它的基本原理是:利用前向传播最后输出的结果来计算误差的偏导数,再用这个偏导数和前面的隐藏层进行加权求和,如此一层一层的向后传下去,直到输入层(不计算输入层),最后利用每个节点求出的偏导数来更新权重。
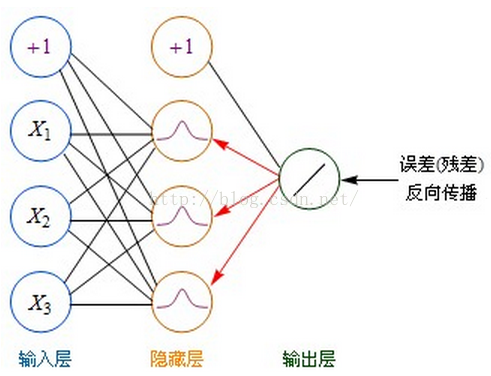
为了便于理解,后面一律用“残差(error term)”这个词来表示误差的偏导数。
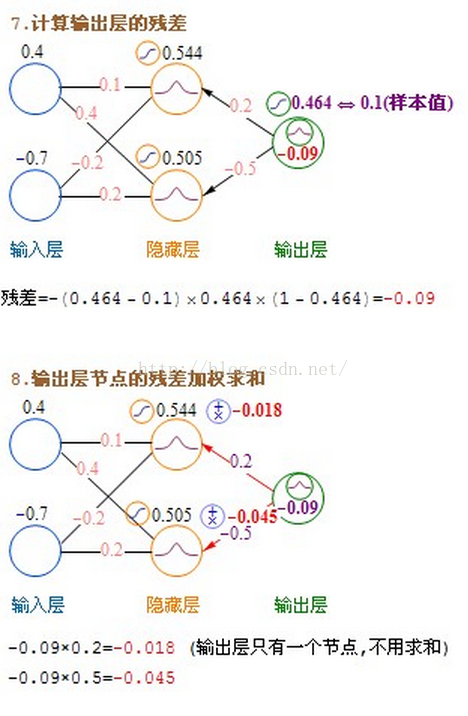
输出层→隐藏层:残差 = -(输出值-样本值) * 激活函数的导数
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 激活函数的导数
例如:如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差 = -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么:Sigmoid导数 = Sigmoid*(1-Sigmoid)
输出层→隐藏层:残差 = -(Sigmoid输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)*输出值*(1-输出值)
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数 = 1 - tansig^2
残差全部计算好后,就可以更新权重了:
输入层:权重增加 = 当前节点的Sigmoid * 右层对应节点的残差 * 学习率
隐藏层:权重增加 = 输入值 * 右层对应节点的残差 * 学习率
偏移值的权重增加 = 右层对应节点的残差 * 学习率
学习率前面介绍过,学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
以上介绍的是目前最常见的神经网络类型,称为前馈神经网络(FeedForward Neural Network),由于它一般是要向后传递误差的,所以也叫BP神经网络(Back Propagation Neural Network)。
BP神经网络的特点和局限:
- BP神经网络可以用作分类、聚类、预测等。需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。
- BP神经网络主要是在实践的基础上逐步完善起来的系统,并不完全是建立在仿生学上的。从这个角度讲,实用性 > 生理相似性。
- BP神经网络中的某些算法,例如如何选择初始值、如何确定隐藏层的节点个数、使用何种激活函数等问题,并没有确凿的理论依据,只有一些根据实践经验总结出的有效方法或经验公式。
- BP神经网络虽然是一种非常有效的计算方法,但它也以计算超复杂、计算速度超慢、容易陷入局部最优解等多项弱点著称,因此人们提出了大量有效的改进方案,一些新的神经网络形式也层出不穷。
详细的计算过程图:
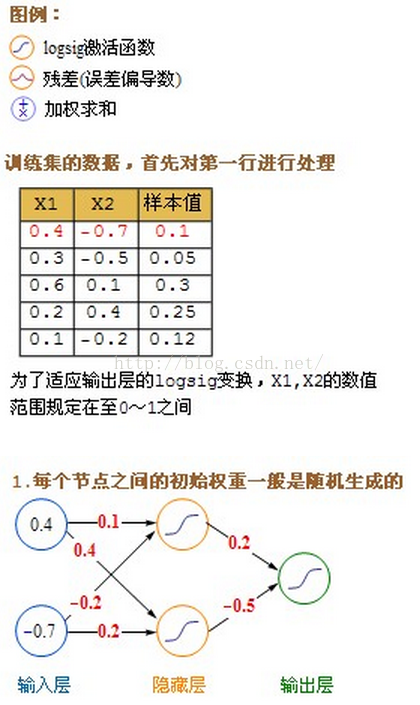
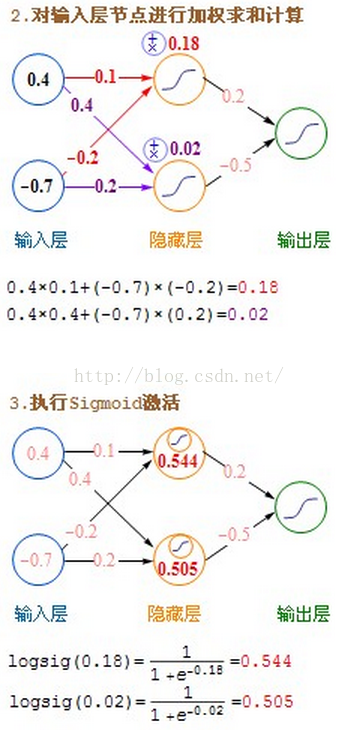



一般企业应用:
1.输入输出变量
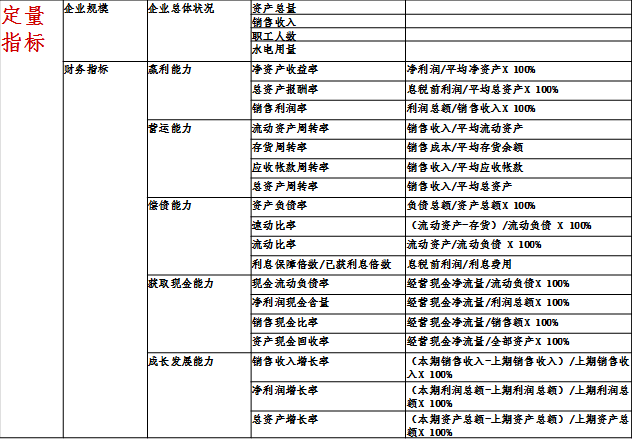
2.算法流程图
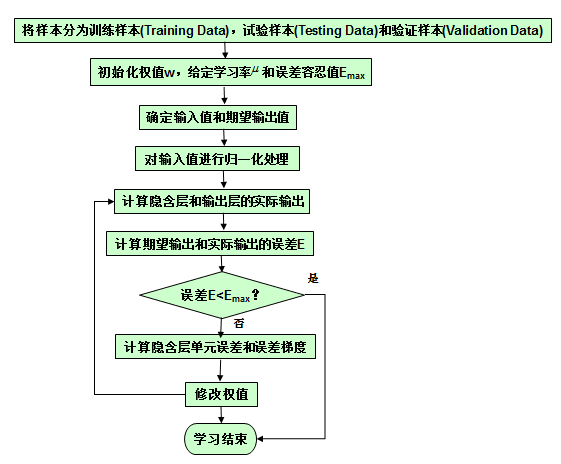
To be continued(医疗输入输出变量的假想)















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









