






 本文简要介绍下基于LLaMA-Factory的llama3 8B模型的微调过程
本文简要介绍下基于LLaMA-Factory的llama3 8B模型的微调过程
环境配置
# 1. 安装py3.10虚拟环境 conda create -n py3.10-torch2.2 python=3.10 source activate conda activate py3.10-torch2.2 # 2. 安装cuda12.2 gpu版torch2.2 conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=12.1 -c pytorch -c nvidia
模型文件下载
基于Modelscope
https://modelscope.cn/models/LLM-Research/Meta-Llama-3-8B/files # git git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B.git
基于Huggingface
https://huggingface.co/meta-llama/Meta-Llama-3-8B # git git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B
- 下载模型文件完成后本地运行,注意官方example运行使用的是original中的模型文件,即*.pth,而不是*.safetensors
# 官方demo torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir Meta-Llama-3-8B/original/ --tokenizer_path Meta-Llama-3-8B/original/tokenizer.model --max_seq_len 512 --max_batch_size 6 torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir Meta-Llama-3-8B-Instruct/original/ --tokenizer_path Meta-Llama-3-8B-Instruct/original/tokenizer.model --max_seq_len 512 --max_batch_size 6
- 也可使用transformers库运行本地大模型
# run_llama3_demo.py from transformers import AutoModelForCausalLM, AutoTokenizer device = "cuda" model_dir = "/home/your_name/llama3/llama3/Meta-Llama-3-8B-Instruct" model = AutoModelForCausalLM.from_pretrained( model_dir, torch_dtype="auto", device_map="auto" ) # 加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处理的格式。 tokenizer = AutoTokenizer.from_pretrained(model_dir) # 加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处理的格式 prompt = "你好,请介绍下你自己。" messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] # 使用分词器的 apply_chat_template 方法将上面定义的消息列表转换为一个格式化的字符串,适合输入到模型中。 # tokenize=False 表示此时不进行令牌化,add_generation_prompt=True 添加生成提示。 text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # 将处理后的文本令牌化并转换为模型输入张量,然后将这些张量移至之前定义的设备(GPU)上。 model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512 ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)
- 运行中占用存储约17G
LLaMA-Factory下载
https://github.com/hiyouga/LLaMA-Factory
升级pip
升级到24.0版本
export PIP_REQUIRE_VIRTUALENV=false python -m pip install --upgrade pip
安装依赖
cd LLaMA-Factory pip install -e .[metrics] # or pip install -r requirements.txt --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
基于LLaMA-Factory微调Llama3
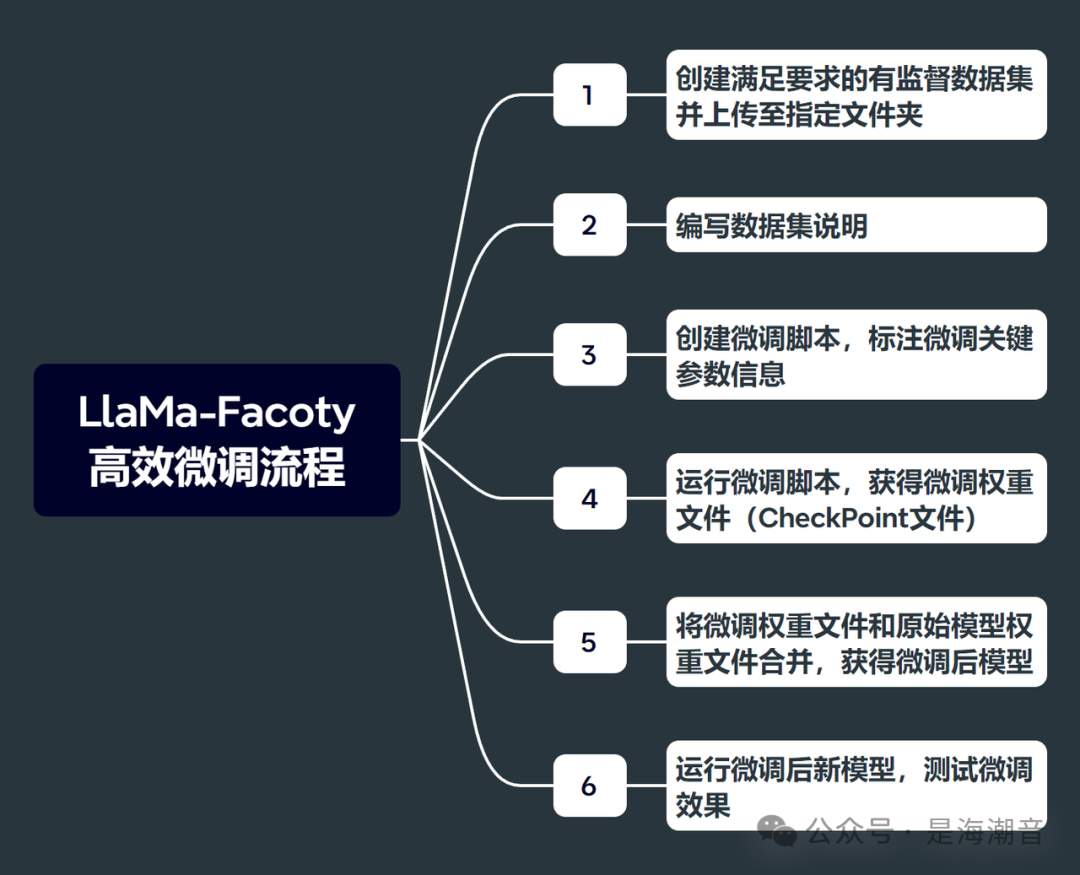
这里以微调中文为例:
Step 1. 查看微调中文数据集数据字典
`cd /home/your_name/LLaMA-Factory/data cat dataset_info.json`
- 这里我们使用alpaca_zh, alpaca_data_zh_51k.json数据
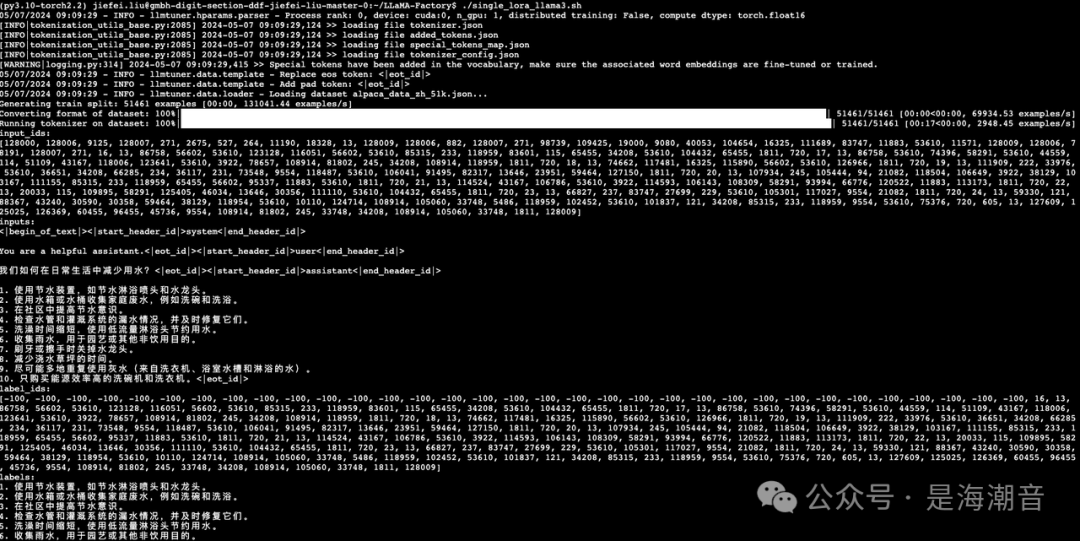
Step 2. 使用中文数据
head alpaca_data_zh_51k.json

Step 3. 创建微调脚本
创建微调脚本
- 单卡微调template
# single_lora_llama3.sh #!/bin/bash export CUDA_DEVICE_MAX_CONNECTIONS=1 export NCCL_P2P_DISABLE="1" export NCCL_IB_DISABLE="1" # 添加 --quantization_bit 4 就是4bit量化的QLoRA微调,不添加此参数就是LoRA微调 \ CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \ ## 单卡运行 --stage sft \ ## --stage pt (预训练模式) --stage sft(指令监督模式) --stage rm(奖励模型) --do_train True \ ## 执行训练模型 --model_name_or_path /your model path/Meta-Llama-3-8B-Instruct \ ## 模型的存储路径 --dataset alpaca_zh \ ## 训练数据的存储路径,存放在 LLaMA-Factory/data路径下 --template llama3 \ ## 选择llama factory支持的模版 --lora_target q_proj,v_proj \ ## 默认模块应作为 --output_dir /save output model/single_lora_llama3_checkpoint \ ## 微调后的模型保存路径 --overwrite_cache \ ## 是否忽略并覆盖已存在的缓存数据 --per_device_train_batch_size 2 \ ## 用于训练的批处理大小。可根据 GPU 显存大小自行设置。 --gradient_accumulation_steps 64 \ ## 梯度累加次数 --lr_scheduler_type cosine \ ## 指定学习率调度器的类型 --logging_steps 5 \ ## 指定了每隔多少训练步骤记录一次日志。这包括损失、学习率以及其他重要的训练指标,有助于监控训练过程。 --save_steps 100 \ ## 每隔多少训练步骤保存一次模型。这是模型保存和检查点创建的频率,允许你在训练过程中定期保存模型的状态 --learning_rate 5e-5 \ ## 学习率 --num_train_epochs 1.0 \ ## 指定了训练过程将遍历整个数据集的次数。一个epoch表示模型已经看过一次所有的训练数据。 --finetuning_type lora \ ## 参数指定了微调的类型,lora代表使用LoRA(Low-Rank Adaptation)技术进行微调。 --fp16 \ ## 开启半精度浮点数训练 --lora_rank 4 \ ## 在使用LoRA微调时设置LoRA适应层的秩。
Step 4. 运行微调脚本,获取模型微调权重
# 对齐格式 sed -i 's/\r$//' ./single_lora_llama3.sh # 修改文件权限 chmod +x ./single_lora_llama3.sh # 运行微调脚本 ./single_lora_llama3.sh
- 开始微调
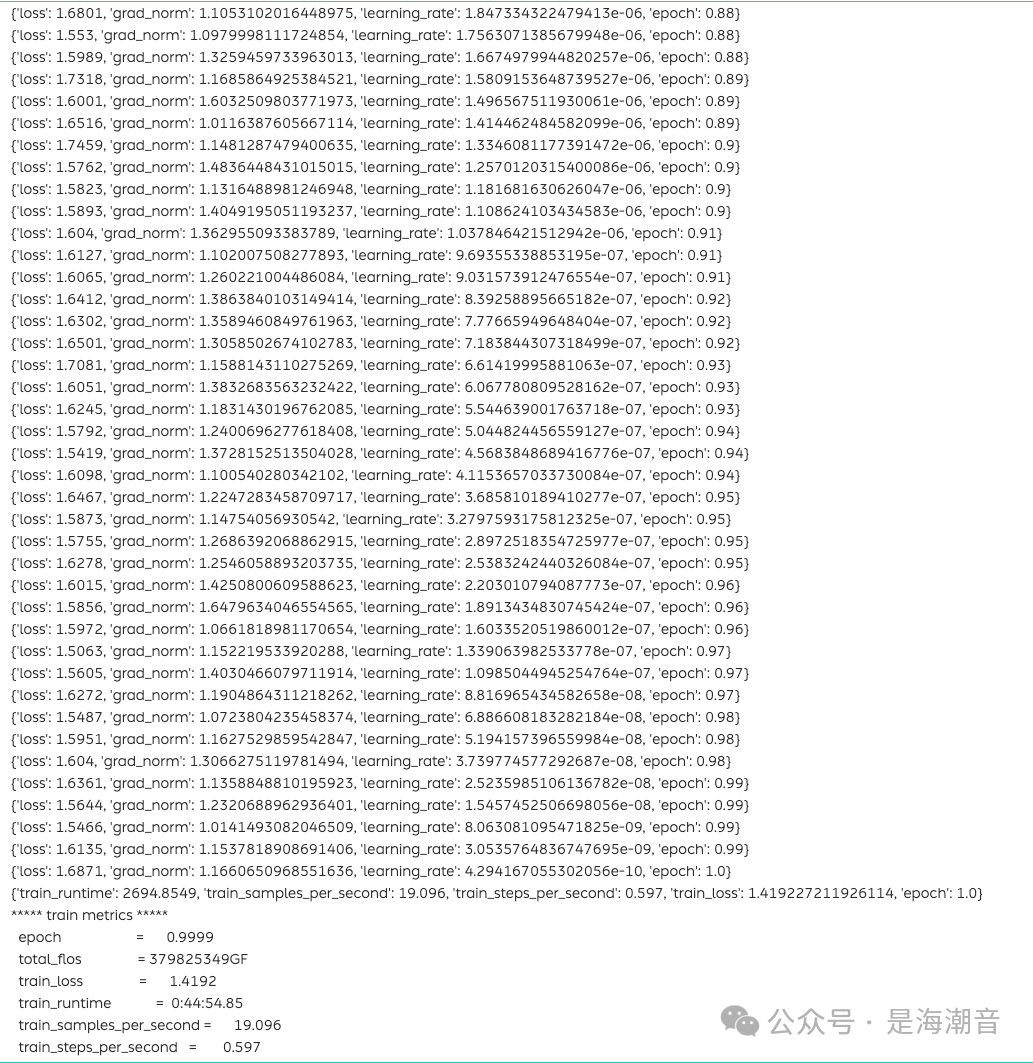
- 微调完成 耗时44分钟
- 微调完成后文件出现
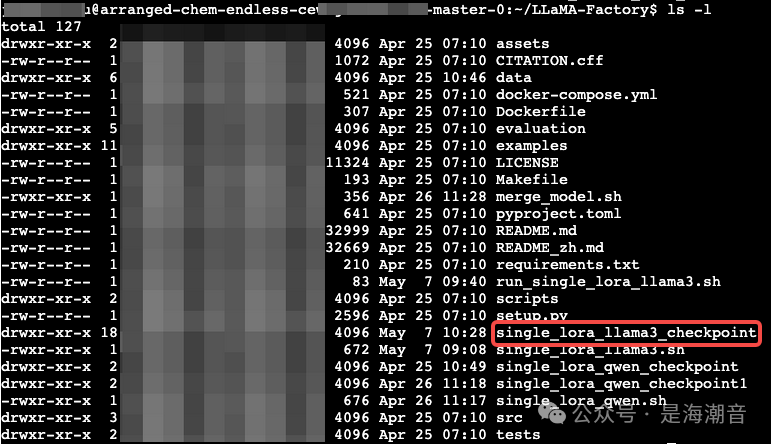
Step 5. 合并模型权重,获得微调模型
-
合并模型权重脚本
-
Merge template
# llama3_merge_model.sh #!/bin/bash python src/export_model.py \ ## 用于执行合并功能的Python代码文件 --model_name_or_path /your_src_model/Meta-Llama-3-8B-Instruct \ ## 原始模型文件 --adapter_name_or_path /your_lora_model/single_lora_llama3_checkpoint \ ## 微调模型权重文件 --template llama3 \ ## 模型模板名称 --finetuning_type lora \ ## 微调框架名称 --export_dir /output_model/llama3_lora \ ## 合并后新模型文件位置 --export_size 2 \ --export_legacy_format false
- 合并模型
sed -i 's/\r$//' ./llama3_merge_model.sh chmod +x ./llama3_merge_model.sh ./llama3_merge_model.sh
- 开始合并
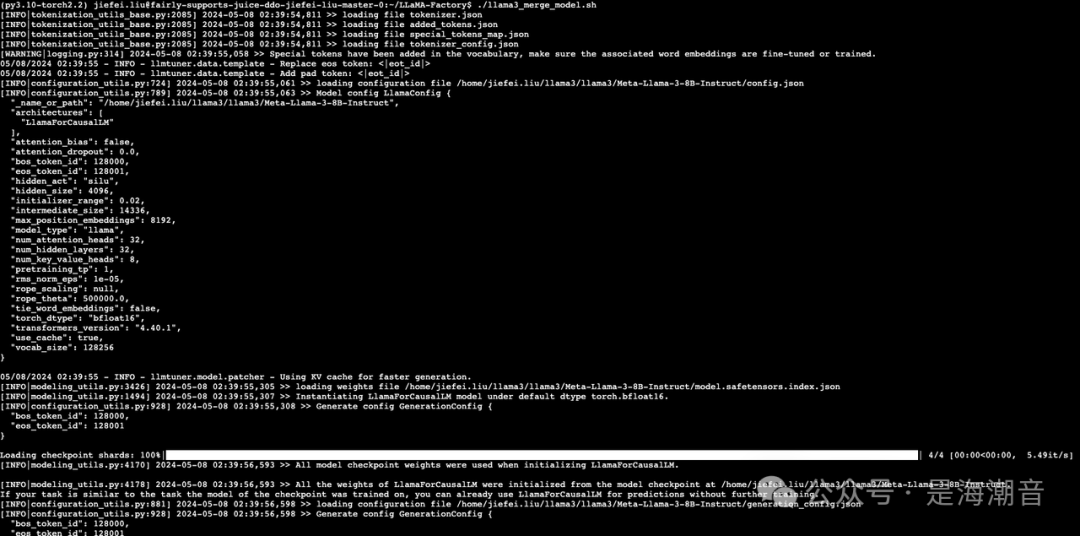
- 合并完成

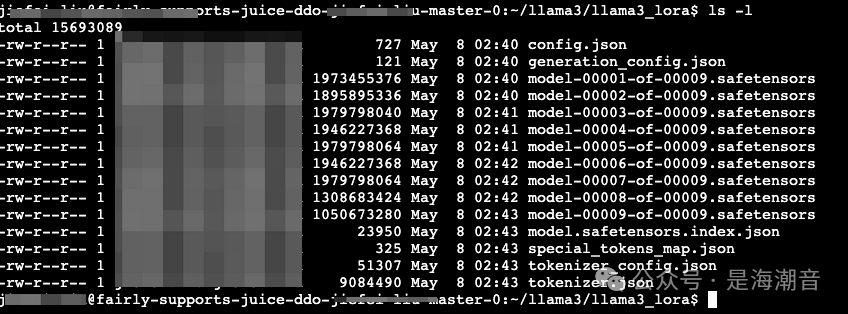
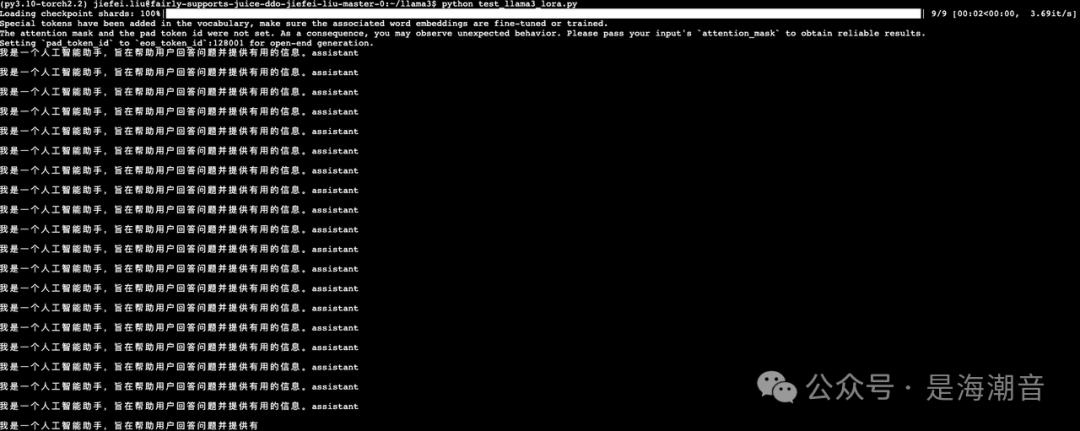
Step 6. 测试微调效果
# test_llama3_lora.py llama3_lora = '/home/your_name/llama3/llama3_lora' from transformers import AutoModelForCausalLM, AutoTokenizer device = "cuda" # the device to load the model onto model = AutoModelForCausalLM.from_pretrained( llama3_lora, torch_dtype="auto", device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(llama3_lora) prompt = "请介绍下你自己" messages = [ {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512 ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)
- 测试结果发现微调后的模型部分实现了预期,输出的结果为中文,但是出现了结果重复出现的问题
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











