






今天给大家分享一个超强的算法模型, Transformer
Transformer 模型是一种用于自然语言处理(NLP)任务的深度学习模型,它由 Vaswani 等人在2017年提出。
Transformer 模型的核心思想是利用自注意力机制(self-attention)来捕捉输入序列中的全局依赖关系,取代传统的循环神经网络(RNN)和长短期记忆网络(LSTM)。
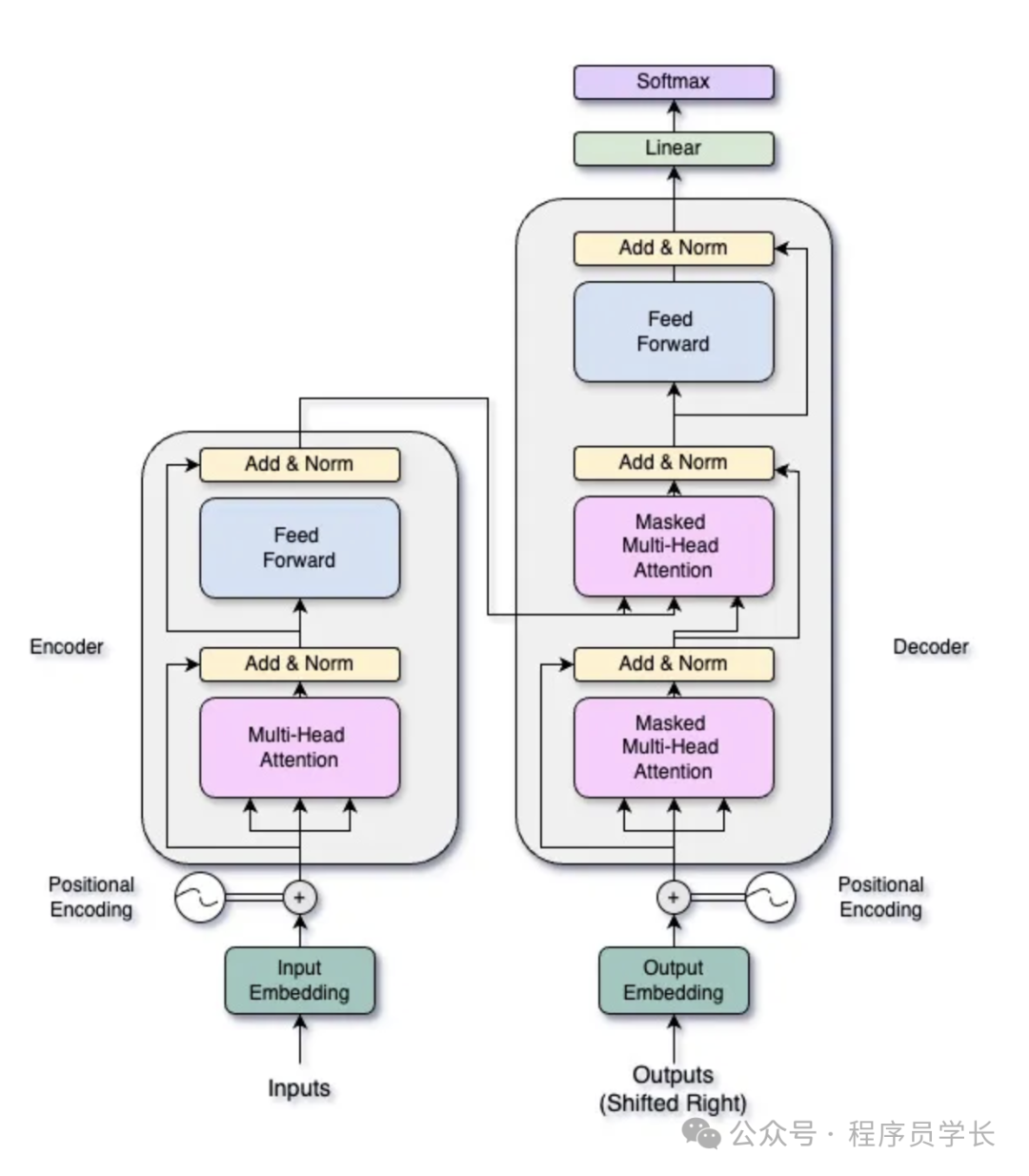
1.Transformer 模型架构
Transformer 模型的架构如下图所示
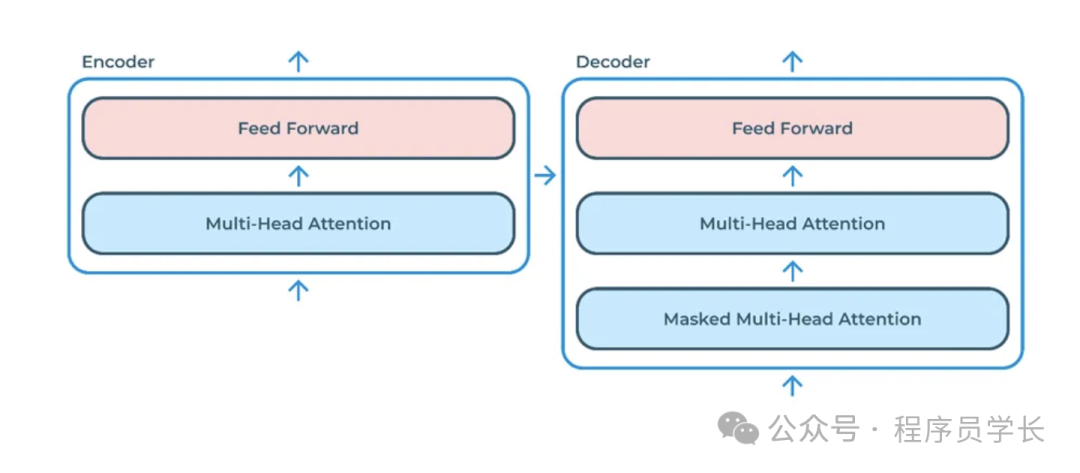
编码器(Encoder)
编码器由多个相同的层(layers)堆叠而成,每层由两部分组成:
-
多头自注意力机制(Multi-Head Self-Attention Mechanism)
-
前馈神经网络(Feed-Forward Neural Network)
解码器(Decoder)
解码器也由多个相同的层堆叠而成,但每层有三部分:
-
多头自注意力机制(Masked Multi-Head Self-Attention Mechanism)
-
编码器-解码器注意力机制(Encoder-Decoder Attention Mechanism)
-
前馈神经网络(Feed-Forward Neural Network)
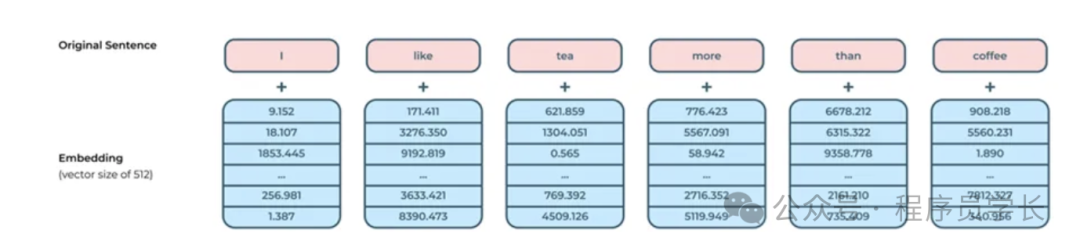
2.什么是输入嵌入
Transformer 模型架构的第一部分是输入嵌入。
输入嵌入(Input Embeddings)是将离散的输入数据(如单词、字符或其他符号)转换为连续的向量表示的方法。
这种表示方式在深度学习模型中非常重要,特别是在自然语言处理(NLP)任务中,常用于将单词或句子转换为能够被神经网络处理的数值形式。
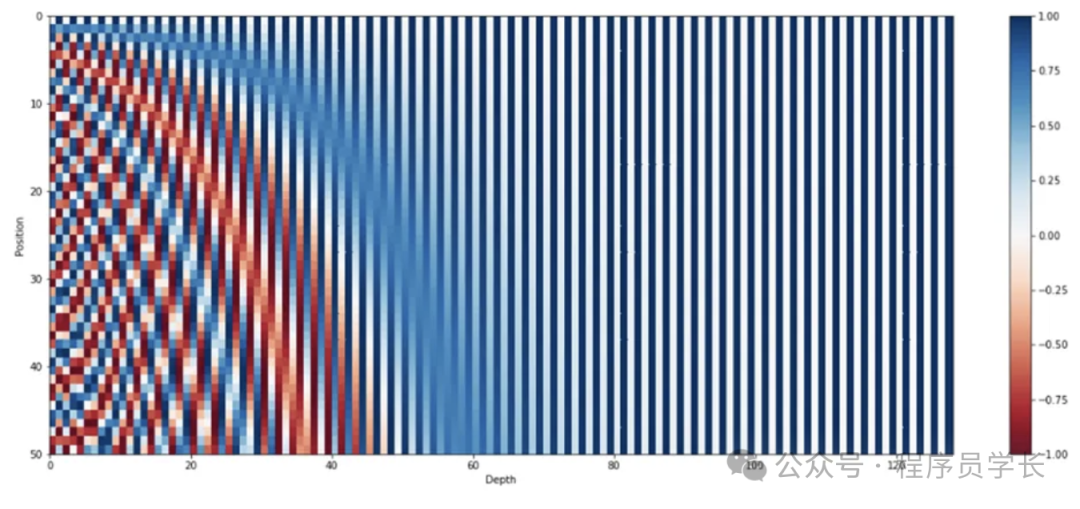
3.什么是位置编码?
位置编码(Positional Encoding)是 Transformer 模型中的一个关键组件,用于在模型中引入序列位置信息。
由于 Transformer 模型本质上不包含任何循环(如RNN)或卷积(如CNN)操作,它无法像这些传统模型那样通过其结构直接捕获输入数据的位置信息。因此,需要通过位置编码来显式地提供序列中的位置信息。
位置编码补充了输入嵌入并确保两者具有相同的维度。
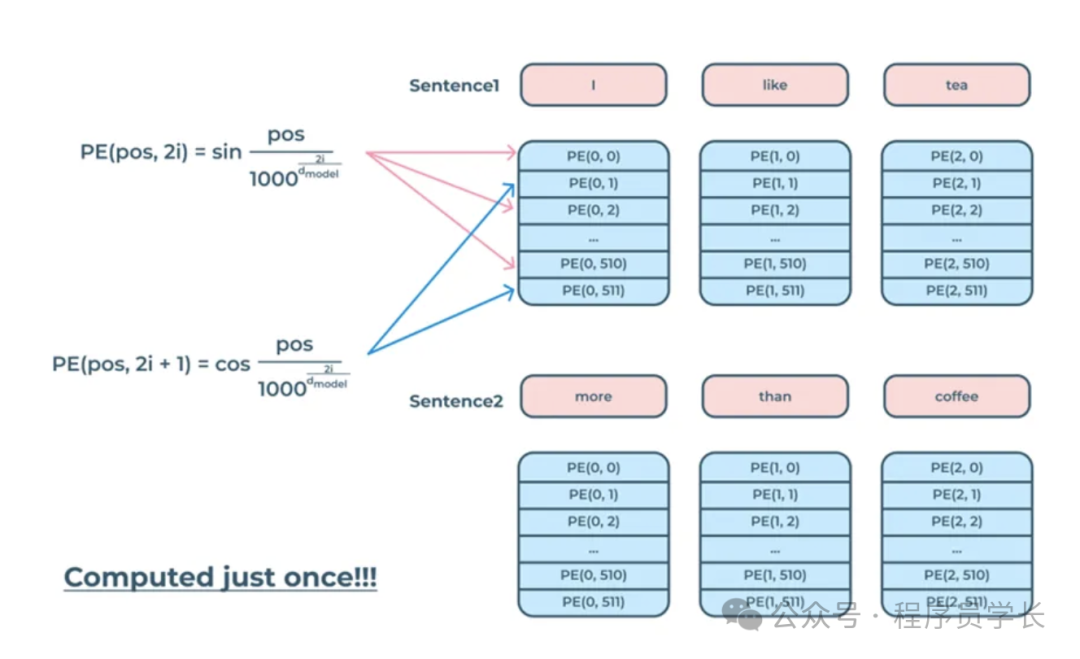
位置编码的公式
位置编码通常使用正弦和余弦函数来生成。
这些函数可以确保编码在不同位置之间具有一定的规律性和独特性。
具体公式如下:
对于位置 pos 和嵌入维度中的第 个维度
对于位置 pos 和嵌入维度中的第 2i + 1 个维度:
其中:
-
pos 是位置索引。
-
i 是维度索引。
-
是嵌入向量的维度。
为什么使用正弦和余弦函数?
我们在位置编码中使用正弦和余弦函数,因为它们具有能够有效表示位置信息的数学特性。
这些函数可帮助模型学习和概括序列内的不同位置,从而增强 Transformer 高效处理和理解自然语言和其他基于序列的数据的能力。
-
周期性
正弦和余弦函数具有周期性,这使得位置编码在不同位置之间具有规律性和周期性。这种周期性有助于模型捕捉序列中的相对位置关系。
例如,相隔固定步数的位置将具有相似的编码,这对序列建模非常有用。
-
唯一性和分离性
通过使用正弦和余弦函数,位置编码在每个维度上都具有不同的频率组合,从而确保了每个位置的编码在高维空间中是唯一的。这种唯一性有助于模型区分序列中不同位置的元素,同时不同位置的编码也具有较好的分离性。
-
光滑性
正弦和余弦函数是光滑的(即连续可微的),这使得位置编码在相邻位置之间具有平滑的变化。这种平滑变化有助于模型更容易捕捉和学习位置之间的关系。
-
无需训练
正弦和余弦函数的参数是固定的,不需要通过训练来学习位置编码。这减少了模型训练的复杂度和参数量,使得模型在训练过程中更加高效。
class PositionalEncoding(nn.Module):
def \_\_init\_\_(self, d\_model, max\_len=5000, dropout:float = 0.1):
super(PositionalEncoding, self).\_\_init\_\_()
self.dropout = nn.Dropout(p=dropout)
# (max\_len, d\_model)
pe = torch.zeros((max\_len, d\_model)) # empty matrix for positional encoding values
# (max\_len, 1)
position = torch.arange(0, max\_len, dtype=torch.float).unsqueeze(1)
# (d\_model // 2, )
division = 10000 \*\* (-np.arange(0, d\_model, 2) / d\_model)
pe\[:, 0::2\] = np.sin(position \* division) # (seq\_len, d\_model), where all pe\[:, 1::2\] = 0
pe\[:, 1::2\] = np.cos(position \* division) # (seq\_len, d\_model), where pos\_enc is not empty anymore
pe = pe.unsqueeze(0).transpose(0, 1)
self.register\_buffer("pe", pe) # buffer of positional encoding
def forward(self, x):
x = x + self.pe\[:x.size(0), :\]
return self.dropout(x)
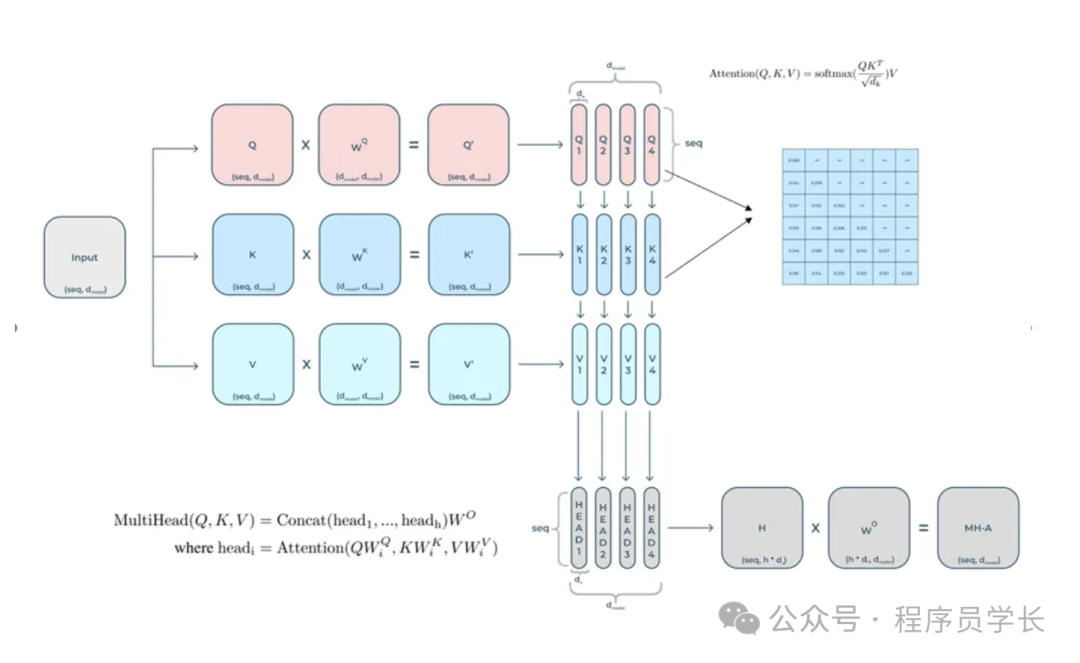
4.什么是自注意力机制?
自注意力机制(Self-Attention Mechanism)是 Transformer 模型的核心组件之一,它使模型能够有效地捕捉序列中任意两个位置之间的依赖关系。
在自注意力机制中,每个输入元素都能够关注序列中的其他元素,从而在全局范围内进行信息整合。
自注意力机制的基本思想是,对于每个输入向量,计算它与所有其他输入向量的相关性,并根据这些相关性进行加权平均。
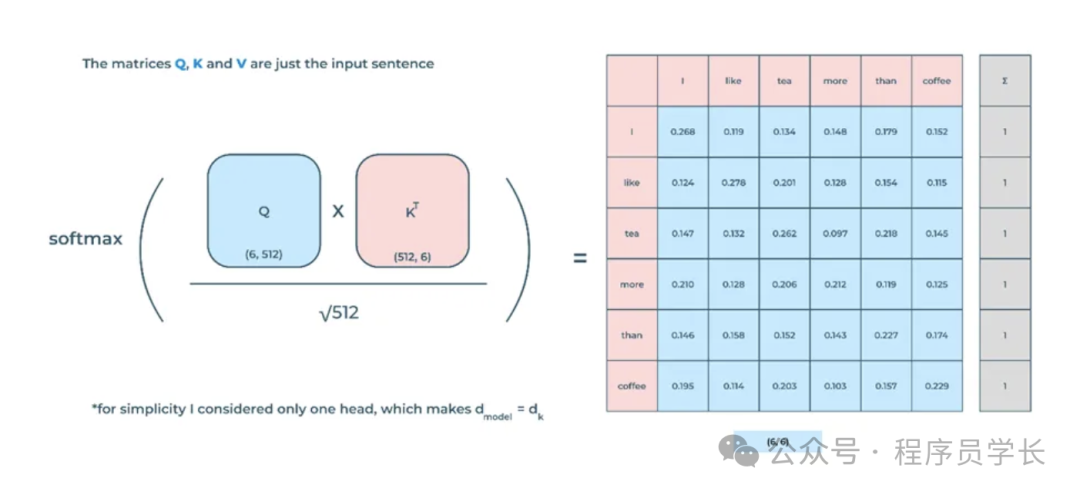
计算过程
自注意力机制的计算过程可以分为以下几个步骤:
-
计算查询(Query)、键(Key)和值(Value)
对于输入序列中的每个元素,首先通过三个不同的线性变换映射到查询、键和值向量。
假设输入序列为 X ,其维度为 ,其中 n 是序列长度, 是嵌入维度。
查询、键和值的计算公式如下:
其中, , 和 分别是查询、键和值的权重矩阵,维度均为 。
-
计算注意力得分
使用查询和键计算注意力得分,这里的注意力得分表示查询与键的相似度。
使用点积(Dot-Product)来计算:
为了避免数值过大,这里使用了缩放因子 。
-
对注意力得分进行 Softmax 操作,得到注意力权重。
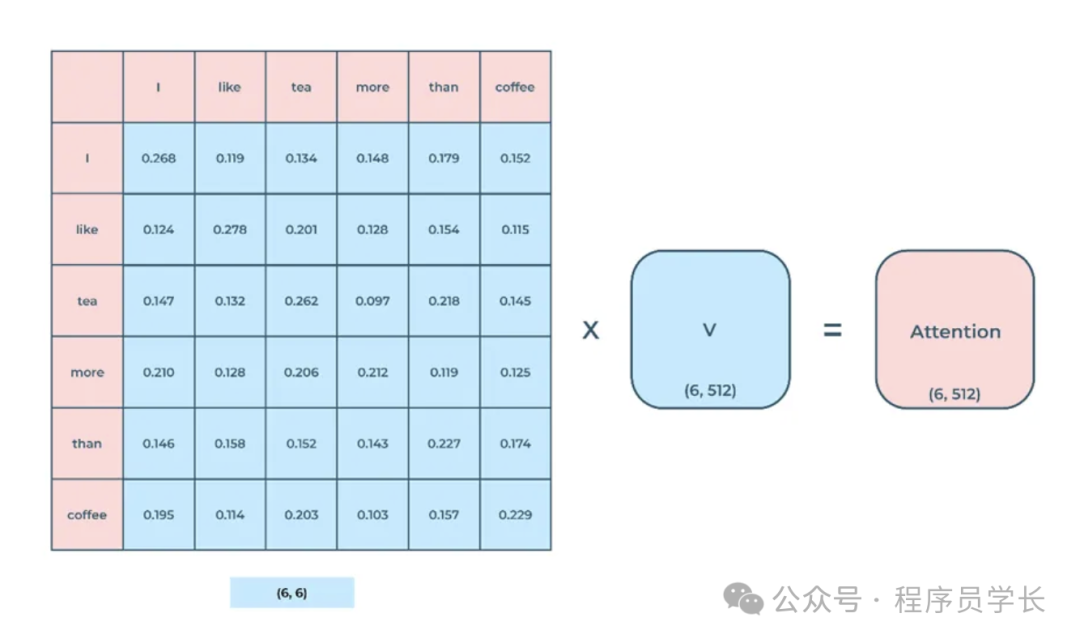
-
计算加权和
5.什么是多头注意力?
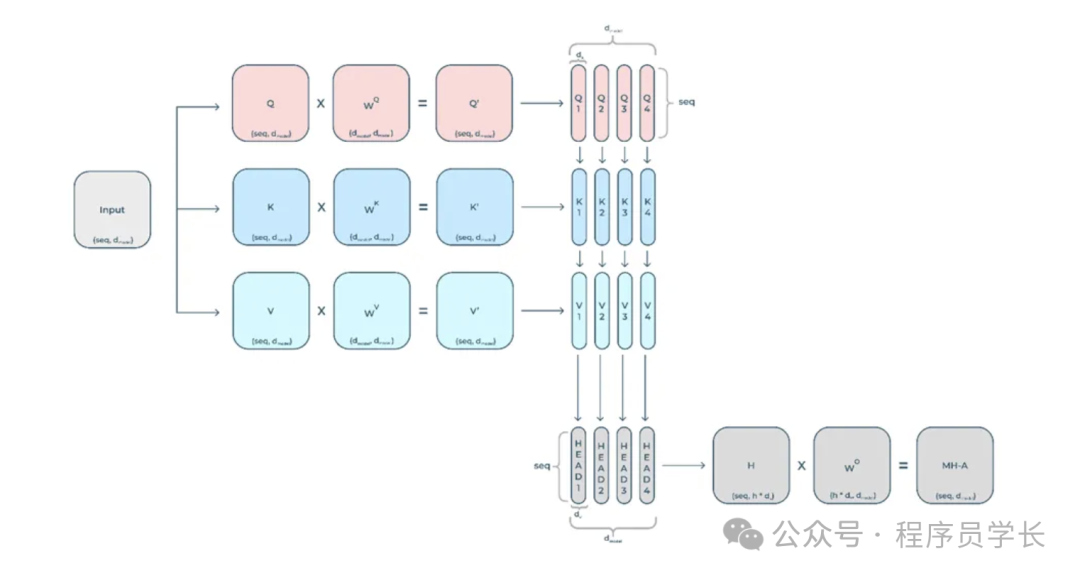
为了增强模型的表达能力,Transformer 使用了多头自注意力机制。
在这种机制中,多个独立的自注意力头并行地计算注意力,然后将结果连接起来,通过线性变换得到最终输出。
具体来说,假设有 h 个注意力头,每个头分别计算如下:
其中, , , 是第 i 个头的查询、键和值的权重矩阵。
然后,将所有头的输出连接起来,并通过线性变换:
其中, 是输出的权重矩阵。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(torch.device("cuda" if torch.cuda.is_available() else "cpu"))
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
Q = self.W_Q(query)
K = self.W_K(key)
V = self.W_V(value)
Q = Q.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = torch.softmax(scores, dim=-1)
output = torch.matmul(attention, V)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
output = self.out_linear(output)
return output
6. 什么是 Add&Norm
在 Transformer 模型中,添加和规范化(Add & Norm)是构建模型中每一层的关键步骤。
这两个步骤分别是残差连接(Residual Connection)和层归一化(Layer Normalization)。
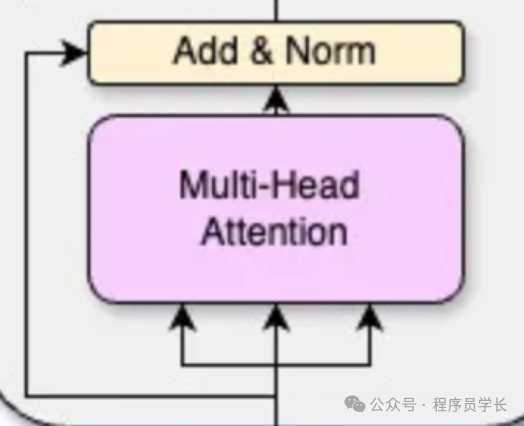
残差连接
残差连接是指在每个子层(例如多头注意力层和前馈神经网络层)之后添加输入。
其目的在于缓解深度网络中梯度消失的问题,促进信息的流动,使得训练更稳定、更快速。
其中, 是经过子层(如自注意力机制或前馈神经网络)处理后的输出, 是进入该子层的输入。
层归一化
层归一化是在残差连接之后进行的一种标准化方法。它通过对每个子层的输出进行归一化,使得每个神经元的输入具有零均值和单位方差,从而加速训练收敛,稳定模型性能。
层归一化的公式如下:
其中:
-
x 是子层输出加上残差连接后的值。
-
是 x 的均值。
-
是 x 的标准差。
-
是一个小常数,防止除零。
完整的添加和规范化步骤可以表示为:
这里的 可以是多头注意力机制或前馈神经网络。
class AddNorm(nn.Module):
def __init__(self, model_dim, epsilon=1e-6):
super(AddNorm, self).__init__()
self.norm = nn.LayerNorm(model_dim, eps=epsilon)
def forward(self, x, sublayer_output):
return self.norm(x + sublayer_output)
7.什么是 FeedForward
在 Transformer 模型中,FeedForward(前馈神经网络)是每个编码器和解码器层的组成部分之一。
前馈神经网络的主要目的是对输入特征进行进一步的线性变换和非线性激活,以提高模型的表示能力。
具体来说,FeedForward 部分在Transformer 中是一个全连接的两层网络。
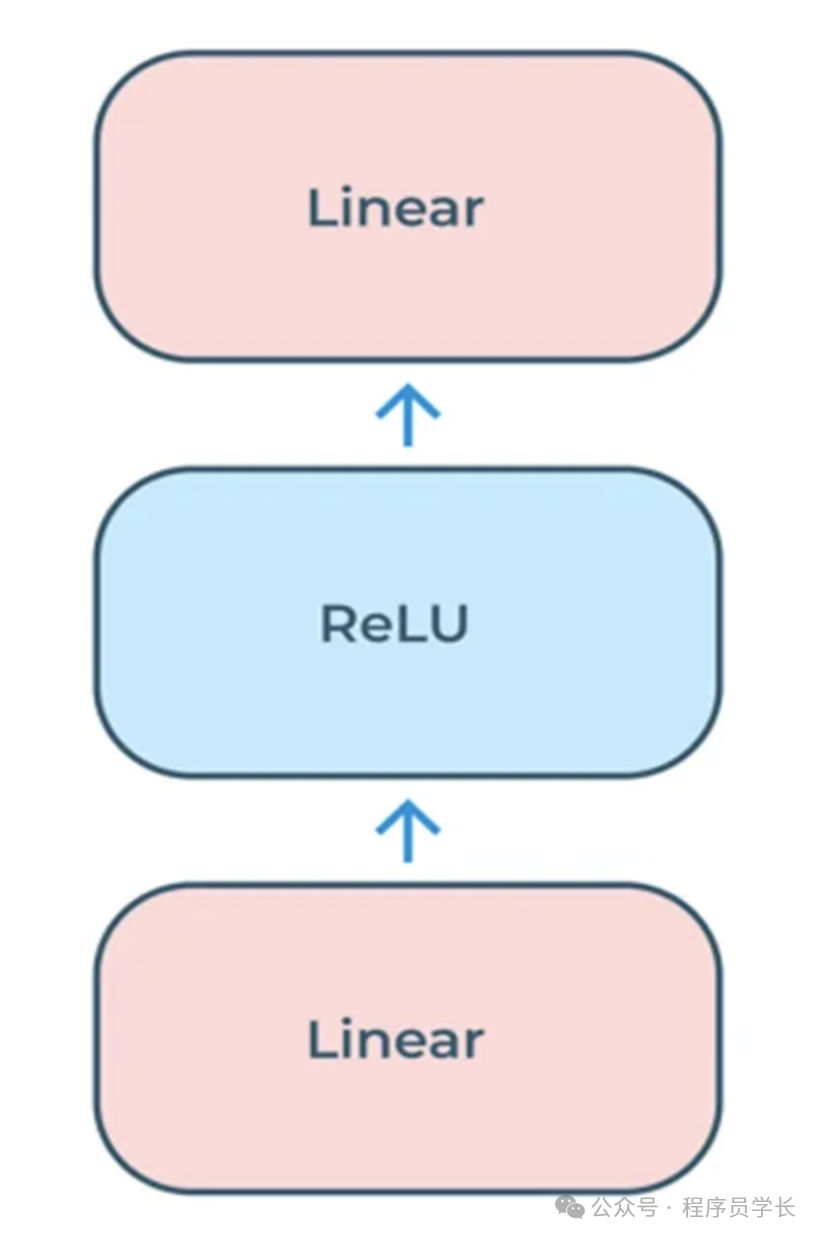
公式表示如下:
其中, 和 分别表示两个线性变换, 表示ReLU激活函数。
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.fc2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.fc2(self.dropout(F.relu(self.fc1(x))))
return x
8.什么是 Masked Multi-Head Attention
Masked Multi-Head Attention 在 Multi-Head Attention (多头注意力)中引入了掩码(Mask)机制,以确保每个位置只能看到它之前的位置。
具体来说,在计算注意力得分时,对未来的位置进行屏蔽,将这些位置的得分设为负无穷大,使得 Softmax 归一化后的权重为零。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 8595
8595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











