







5. ZSL中存在的问题
1)领域漂移问题(domain shift)
由于两个数据集有不同且可能不相关的类,类的底层数据分布不同,因此低级特征空间和语义空间之间的“理想”投影函数也不同,使用从辅助数据集/域学习的投影函数,而不对目标数据集/域进行任何适应,会导致未知的偏移/偏差。
解决:SAE, GAN,见下文。
在不同的类别中,视觉特征的表现可能会不一样。例如像这篇文章中举的例子,如图,斑马和猪都有一个属性是“有尾巴”,而这两者的尾巴在视觉特征中却相去甚远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。因为可能在训练集中的数据对“有尾巴”的描述与测试集中的不一样,虽然它们都有“有尾巴”这个属性,这样直接迁移可能会有偏差。
问题的提出:Transductive Multi-View Zero-Shot Learning(2015,TPAMI)

典型文章:Semantic Autoencoder for Zero-Shot Learning(SAE)-2017 CVPR
Motivation: 领域漂移(domain shift)
训练的可见类和测试的不可见类是不同的,尽管他们在某些程度上具有相同的语义信息。例如,某些可视的属性在不可见类上是完全不同的,因此,如果从可见类映射到可视特征上,不可见类图像的映射可能会丢失(漂移),有时这个漂移会远离该不可见类的正确属性,使得后续的NN(Nearest Neighbor)不准确。
Linear autoencoder:


Model Formulation
传统的自动编码器是非监督模型,潜在层空间没有明确的语义信息。在该模型中,我们假设潜在层有语义表征,例如,类别标签或者属性。为了使得潜在层语义空间有更好的语义表征,我们采用最简单的方法,即,强制潜在空间S为语义表征空间,例如S的每一列是一个训练集的属性向量。


具有硬限制(WX=S)的最优化问题很难求解,因此,变形为软限制问题:
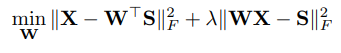
其中,λ为权重系数,平衡两项。上式为一个标准二次公式,是一个具有全局最优解的凸函数。
根据矩阵迹的属性:![]()
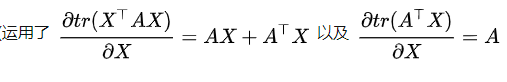
![]()
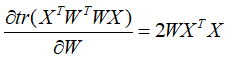
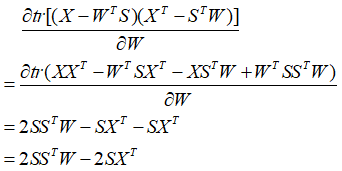
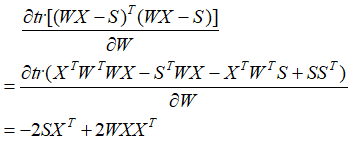

上式为Sylvester equation,可以通过Bartels-Stewart算法求解。

def find_W(self, X, S, ld):
# INPUTS:
# X: d x N - data matrix
# S: Number of Attributes (k) x N - semantic matrix
# ld: regularization parameter
#
# Return :
# W: kxd projection matrix
A = np.dot(S, S.T)
B = ld*np.dot(X, X.T)
C = (1+ld)*np.dot(S, X.T)
W = linalg.solve_sylvester(A, B, C)
return W
def find_lambda(self):
print('Training...\n')
best_acc_F2S = 0.0
best_acc_S2F = 0.0
ld = self.args.ld1
while (ld<=self.args.ld2):
W = self.find_W(self.X_train, self.train_att.T, ld)
acc_F2S, acc_S2F = self.zsl_acc(self.X_val, W, self.labels_val, self.val_sig, 'val')
print('Val Acc --> [F-->S]:{} [S-->F]:{} @ lambda = {}\n'.format(acc_F2S, acc_S2F, ld))
if acc_F2S>best_acc_F2S:
best_acc_F2S = acc_F2S
lambda_F2S = ld
best_W_F2S = np.copy(W)
if acc_S2F>best_acc_S2F:
best_acc_S2F = acc_S2F
lambda_S2F = ld
best_W_S2F = np.copy(W)
ld*=2
print('\nBest Val Acc --> [F-->S]:{} @ lambda = {} [S-->F]:{} @ lambda = {}\n'.format(best_acc_F2S, lambda_F2S, best_acc_S2F, lambda_S2F))
return best_W_F2S, best_W_S2F
SAE这个额外的限制(W*=WT)很大程度地解决了领域漂移的问题,文中说这是因为虽然从seen到unseen的属性的视觉表达会有所改变,但是视觉特征对更真实的要求是两者通用的,这能使嵌入时更少地遭受领域漂移的影响。
Zero-Shot Learning Problem definition

求解SEA ZSL过程:

def zsl_acc(self, X, W, y_true, sig, mode='val'): # Class Averaged Top-1 Accuarcy
if mode=='F2S':
# [F --> S], projecting data from feature space to semantic space
F2S = np.dot(X.T, self.normalizeFeature(W).T)# N x k
dist_F2S = 1-spatial.distance.cdist(F2S, sig.T, 'cosine')# N x C(no. of classes)
pred_F2S = np.array([np.argmax(y) for y in dist_F2S])
cm_F2S = confusion_matrix(y_true, pred_F2S)
cm_F2S = cm_F2S.astype('float')/cm_F2S.sum(axis=1)[:, np.newaxis]
acc_F2S = sum(cm_F2S.diagonal())/sig.shape[1]
return acc_F2S
if mode=='S2F':
# [S --> F], projecting from semantic to visual space
S2F = np.dot(sig.T, self.normalizeFeature(W))
dist_S2F = 1-spatial.distance.cdist(X.T, self.normalizeFeature(S2F), 'cosine')
pred_S2F = np.array([np.argmax(y) for y in dist_S2F])
cm_S2F = confusion_matrix(y_true, pred_S2F)
cm_S2F = cm_S2F.astype('float')/cm_S2F.sum(axis=1)[:, np.newaxis]
acc_S2F = sum(cm_S2F.diagonal())/sig.shape[1]
return acc_S2F
if mode=='val':
# [F --> S], projecting data from feature space to semantic space
F2S = np.dot(X.T, self.normalizeFeature(W).T)# N x k
dist_F2S = 1-spatial.distance.cdist(F2S, sig.T, 'cosine')# N x C(no. of classes)
# [S --> F], projecting from semantic to visual space
S2F = np.dot(sig.T, self.normalizeFeature(W))
dist_S2F = 1-spatial.distance.cdist(X.T, self.normalizeFeature(S2F), 'cosine')
pred_F2S = np.array([np.argmax(y) for y in dist_F2S])
pred_S2F = np.array([np.argmax(y) for y in dist_S2F])
cm_F2S = confusion_matrix(y_true, pred_F2S)
cm_F2S = cm_F2S.astype('float')/cm_F2S.sum(axis=1)[:, np.newaxis]
cm_S2F = confusion_matrix(y_true, pred_S2F)
cm_S2F = cm_S2F.astype('float')/cm_S2F.sum(axis=1)[:, np.newaxis]
acc_F2S = sum(cm_F2S.diagonal())/sig.shape[1]
acc_S2F = sum(cm_S2F.diagonal())/sig.shape[1]
# acc = acc_F2S if acc_F2S>acc_S2F else acc_S2F
return acc_F2S, acc_S2F
def evaluate(self):
if self.args.mode=='train': best_W_F2S, best_W_S2F = self.find_lambda()
else:
best_W_F2S = self.find_W(self.X_train, self.train_att.T, self.args.ld1)
best_W_S2F = self.find_W(self.X_train, self.train_att.T, self.args.ld2)
test_acc_F2S = self.zsl_acc(self.X_test, best_W_F2S, self.labels_test, self.test_sig, 'F2S')
test_acc_S2F = self.zsl_acc(self.X_test, best_W_S2F, self.labels_test, self.test_sig, 'S2F')
print('Test Acc --> [F-->S]:{} [S-->F]:{}'.format(test_acc_F2S, test_acc_S2F))Supervised Clustering
通过训练集训练出映射W,利用W将测试集的样本表示为属性层的表示形式,注意这里的属性层是二值化的,并且将其表示为one-hot的形式,这样就可以用属性层来表示类别了。之后再进行kmeans聚类,得到测试集合的聚类结果。
Relations to Existing Models
EZSL模型表示为: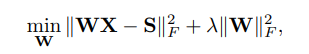
文献*提出了反方向的映射:(*Y. Shigeto, I. Suzuki, K. Hara, M. Shimbo, and Y. Matsumoto. Ridge regression, hubness, and zero-shot learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 135–151. Springer, 2015.)
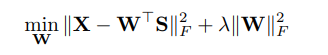
SAE模型是上述两个模型的综合,去掉了正则项。SAE中,正则项是非必要的,因为W*=WT,编码器中,||W||F2,值不会很大,因为它会在语义空间中产生较大的值,并与largenorm解码器的矩阵相乘后,会导致重构效果不好。换句话说,投影矩阵范数上的正则化是由重构约束自动处理的。
数据集:使用了6个数据集,分为是:1)Animals with Attributes(AwA). 2)CUB-200-2011 Birds(CUB). 3)aPascal&Yahoo(aP&Y). 4)SUN Attribute(SUN). 5)ILSVRC2010(ImNet-1). 6)ILSVRC012/ILSVRC2010(ImNet-2)。其中,后两个数据集是大型的数据集。细节如表1所示。

属性层:对于前面四个小型数据集,zero-shot learning中用到的中间属性层有数据集提供;对于大型数据集,通过训练Wikipedia语料库进行生成。样本特征:ImNet-1使用AlexNet得到4096维特征,其他数据集样本使用GoogleNet得到样本的1024维特征。

本文算法目标函数中两个部分共同存在的重要性,当两部分同时存在,即对映射函数增加了“可以恢复到原样本”的约束。由表可知,这个约束对结果的提升非常大。

作者将测试集中也包括了部分训练集的类别,这本质上是一种检测算法泛化能力的方法。结果如表4所示,可以看到在数据集AwA上要比目前最好的算法差一点点,在CUB上效果为最好。

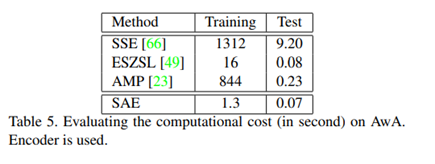
算法的计算时间,由于本文算法的结构十分简单,相比之下其他算法要复杂得多,因此本文算法速度快很多。如表5所示。
监督聚类(supervised clustering)的检测。结果如表6、7、8和图3所示。

典型文章:A Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts (SAE)-2018 CVPR
对于“生成”模型,很自然就想到了GAN,这是基于一个很自然的想法:我们人看到一段文字的时候,如果之前没见过所描述的对象,我们首先会在脑海中先形成一种模糊的想象,这种想象与真实的肯定会有一定的偏差,但是修正想象比直接从文本描述就能得到真实的对象更加容易。而GAN在这里就充当“想象”这一过程。
通过对不可见实例的语义特征与实例的视觉特征在嵌入空间中的相似度进行排序,预测不可见实例的类标签。
这种策略实现了从语义空间到视觉空间的一对一映射。然而,类别和对象的文本描述内在地映射到图像空间中的各种点。例如,“a blue bird with white head”可以用来描述所有的鸟都是蓝色的身体和白色的头。这促使我们研究对抗性训练如何学习添加随机性的一对多映射。
本文中,将ZSL当作一个imagination问题。

采用GAN网络模型实现语义信息的想象。提出的条件生成模型将类的语义表示作为输入,生成对应类的伪视觉特征。
对于wiki中文本的噪声问题,之前的研究需要复杂的正则化或者自动编码器,我们则更简单,在输入到generator之前通过一个全连接层进行连接,性能提升3%。
训练数据的稀疏性(CUB数据集中每个类别大约60个样本)使得GAN本身很难很好的模拟高维特征的条件概率分布(约3500维)。例如图2c中,生成的特征很分散,破坏了真实特征中的聚类结构,因此很难保留足够的跨类判别信息来进行不可见样本的图像分类。为了弥补这一缺陷,我们提出了一个可视化的中枢正则化器,为generator在适当的范围内综合特性提供明确的指导,从而保持足够的类间区分。

Methodology

本文方法的核心是生成模型的设计,为不可见的类产生合格的视觉特征,从而进一步促进ZSL。

Generator G:
首先,输入样本带噪声的文本描述,文本嵌入函数命名为φ,φ(Tc)代表文本嵌入特征经过一个全连接层进行维度约减。 经维度约减后的特征连接一个随机噪声向量(Gauss分布噪声,N(0,1)),然后连接两个全连接层,并用Leaky-Relu和Tanh激活。用下式表示:
![]()
class _netG(nn.Module):
def __init__(self, text_dim=11083, X_dim=3584):
super(_netG, self).__init__()
self.rdc_text = nn.Linear(text_dim, rdc_text_dim)
self.main = nn.Sequential(nn.Linear(z_dim + rdc_text_dim, h_dim),
nn.LeakyReLU(),
nn.Linear(h_dim, X_dim),
nn.Tanh())
def forward(self, z, c):
rdc_text = self.rdc_text(c)
input = torch.cat([z, rdc_text], 1)
output = self.main(input)
return outputGenerator的损失表示为:
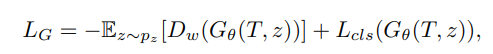
第一项为Wasserstein loss损失,第二项为分类损失。(算法代码中,还加入了正则项,欧式距离等,见下文)
Discriminator D:
D的输入为生成器的语义特征G和图像视觉特征E,然后连接一个全连接层,并用Relu激活。接着分为两个分支:1. 全连接层+0/1分类,判断特征是否为真实特征;2. 全连接层+分类,类别判断。
class _netD(nn.Module):
def __init__(self, y_dim=150, X_dim=3584):
super(_netD, self).__init__()
# Discriminator net layer one
self.D_shared = nn.Sequential(nn.Linear(X_dim, h_dim),
nn.ReLU())
# Discriminator net branch one: For Gan_loss
self.D_gan = nn.Linear(h_dim, 1)
# Discriminator net branch two: For aux cls loss
self.D_aux = nn.Linear(h_dim, y_dim)
def forward(self, input):
h = self.D_shared(input)
return self.D_gan(h), self.D_aux(h)损失函数为:
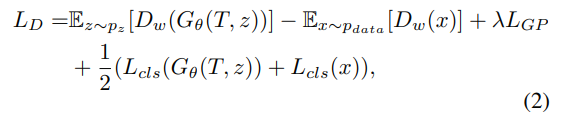
前两项近似于真实特征和假特征之间的Wasserstein距离。第三项为梯度补偿,增加了Lipschitz限制:
![]()

def calc_gradient_penalty(netD, real_data, fake_data):
alpha = torch.rand(opt.batchsize, 1)
alpha = alpha.expand(real_data.size())
alpha = alpha.cuda()
interpolates = alpha * real_data + ((1 - alpha) * fake_data) # 真实特征和假特征的线性插值
interpolates = interpolates.cuda()
interpolates = autograd.Variable(interpolates, requires_grad=True)
disc_interpolates, _ = netD(interpolates)
gradients = autograd.grad(outputs=disc_interpolates, inputs=interpolates,
grad_outputs=torch.ones(disc_interpolates.size()).cuda(),
create_graph=True, retain_graph=True, only_inputs=True)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * opt.GP_LAMBDA # 见公式 L(GP)
return gradient_penalty
Feature Extractor E:
首先,通过Faster R-CNN(VGG-16)检测鸟的7个语义组成部分,语义部分p应具有最高的置信度得分,若得分小于阈值,说明该语义部分缺失(例如,遮挡)。p经过ROI Pooling并用全连接层编码为512维的特征,作为输出。
Visual Pivot Regularization(视觉中枢正则化)
虽然上述网络提供了一种生成具有真实视觉特征相似分布的样本的方法,但仍然难以实现较好的仿真。潜在的原因是训练样本的稀疏性(CUB中每个类约60张图像),这使得学习高维视觉特征的分布(约3500D)变得困难。我们观察到可见类的视觉特征具有较高的类内相似度和相对较低的类间相似度,如图2中,可见类的分簇之间重叠很小,我们希望每个类生成的特征即使不在相应的集群内,也分布在周围。即VP( Visual Pivot )
Visual Pivot 定义为X空间视觉特征分簇的中心,或是视觉特征的均值,这里我们采用视觉特征的一阶矩来表示VP(作者说均值或Mean-shift方法对于最终性能没有影响,因此可以任意选择).每个类别生成特征的均值作为真实特征分布的均值:
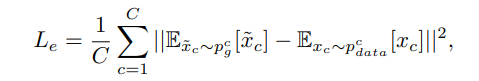

![]() Nc为样本数。
Nc为样本数。
同理,合成视觉特征也可用均值来代替:![]()
Training Procedure
在每次迭代中,判别器更新 nd(代码中为5) 次,生成器更新1次。

for it in range(start_step, 3000+1):
""" Discriminator """
for _ in range(5):
blobs = data_layer.forward() #产生一个batch数据
feat_data = blobs['data'] # image data
labels = blobs['labels'].astype(int) # class labels
text_feat = np.array([dataset.train_text_feature[i,:] for i in labels])
text_feat = Variable(torch.from_numpy(text_feat.astype('float32'))).cuda()
X = Variable(torch.from_numpy(feat_data)).cuda()
y_true = Variable(torch.from_numpy(labels.astype('int'))).cuda()
z = Variable(torch.randn(opt.batchsize, param.z_dim)).cuda()
# GAN's D loss
D_real, C_real = netD(X) # 两个分支:real/fake分支,分类分支
D_loss_real = torch.mean(D_real)
C_loss_real = F.cross_entropy(C_real, y_true)
DC_loss = -D_loss_real + C_loss_real
DC_loss.backward()
# GAN's D loss
G_sample = netG(z, text_feat).detach()
D_fake, C_fake = netD(G_sample)
D_loss_fake = torch.mean(D_fake)
C_loss_fake = F.cross_entropy(C_fake, y_true)
DC_loss = D_loss_fake + C_loss_fake
DC_loss.backward()
# train with gradient penalty (WGAN_GP)
grad_penalty = calc_gradient_penalty(netD, X.data, G_sample.data)
grad_penalty.backward()
Wasserstein_D = D_loss_real - D_loss_fake
optimizerD.step()
reset_grad(nets)
""" Generator """
for _ in range(1):
blobs = data_layer.forward()
feat_data = blobs['data'] # image data
labels = blobs['labels'].astype(int) # class labels
text_feat = np.array([dataset.train_text_feature[i, :] for i in labels])
text_feat = Variable(torch.from_numpy(text_feat.astype('float32'))).cuda()
X = Variable(torch.from_numpy(feat_data)).cuda()
y_true = Variable(torch.from_numpy(labels.astype('int'))).cuda()
z = Variable(torch.randn(opt.batchsize, param.z_dim)).cuda()
G_sample = netG(z, text_feat)
D_fake, C_fake = netD(G_sample)
_, C_real = netD(X)
# GAN's G loss
G_loss = torch.mean(D_fake)
# Auxiliary classification loss
C_loss = (F.cross_entropy(C_real, y_true) + F.cross_entropy(C_fake, y_true))/2
GC_loss = -G_loss + C_loss
# Centroid loss
Euclidean_loss = Variable(torch.Tensor([0.0])).cuda()
if opt.CENT_LAMBDA != 0:
for i in range(dataset.train_cls_num):
sample_idx = (y_true == i).data.nonzero().squeeze()
if sample_idx.numel() == 0:
Euclidean_loss += 0.0
else:
G_sample_cls = G_sample[sample_idx, :]
Euclidean_loss += (G_sample_cls.mean(dim=0) - tr_cls_centroid[i]).pow(2).sum().sqrt()
Euclidean_loss *= 1.0/dataset.train_cls_num * opt.CENT_LAMBDA
# ||W||_2 regularization
reg_loss = Variable(torch.Tensor([0.0])).cuda()
if opt.REG_W_LAMBDA != 0:
for name, p in netG.named_parameters():
if 'weight' in name:
reg_loss += p.pow(2).sum()
reg_loss.mul_(opt.REG_W_LAMBDA)
# ||W_z||21 regularization, make W_z sparse
reg_Wz_loss = Variable(torch.Tensor([0.0])).cuda()
if opt.REG_Wz_LAMBDA != 0:
Wz = netG.rdc_text.weight
reg_Wz_loss = Wz.pow(2).sum(dim=0).sqrt().sum().mul(opt.REG_Wz_LAMBDA)
all_loss = GC_loss + Euclidean_loss + reg_loss + reg_Wz_loss
all_loss.backward()
optimizerG.step()
reset_grad(nets)
if it % opt.disp_interval == 0 and it:
acc_real = (np.argmax(C_real.data.cpu().numpy(), axis=1) == y_true.data.cpu().numpy()).sum() / float(y_true.data.size()[0])
acc_fake = (np.argmax(C_fake.data.cpu().numpy(), axis=1) == y_true.data.cpu().numpy()).sum() / float(y_true.data.size()[0])
log_text = 'Iter-{}; Was_D: {:.4}; Euc_ls: {:.4}; reg_ls: {:.4}; Wz_ls: {:.4}; G_loss: {:.4}; D_loss_real: {:.4};' \
' D_loss_fake: {:.4}; rl: {:.4}%; fk: {:.4}%'\
.format(it, Wasserstein_D.data[0], Euclidean_loss.data[0], reg_loss.data[0],reg_Wz_loss.data[0],
G_loss.data[0], D_loss_real.data[0], D_loss_fake.data[0], acc_real * 100, acc_fake * 100)
print(log_text)
with open(log_dir, 'a') as f:
f.write(log_text+'\n')
if it % opt.evl_interval == 0 and it >= 100:
netG.eval()
eval_fakefeat_test(it, netG, dataset, param, result)
eval_fakefeat_GZSL(it, netG, dataset, param, result_gzsl)
if result.save_model:
files2remove = glob.glob(out_subdir + '/Best_model*')
for _i in files2remove:
os.remove(_i)
torch.save({
'it': it + 1,
'state_dict_G': netG.state_dict(),
'state_dict_D': netD.state_dict(),
'random_seed': opt.manualSeed,
'log': log_text,
}, out_subdir + '/Best_model_Acc_{:.2f}.tar'.format(result.acc_list[-1]))
netG.train()
if it % opt.save_interval == 0 and it:
torch.save({
'it': it + 1,
'state_dict_G': netG.state_dict(),
'state_dict_D': netD.state_dict(),
'random_seed': opt.manualSeed,
'log': log_text,
}, out_subdir + '/Iter_{:d}.tar'.format(it))
cprint('Save model to ' + out_subdir + '/Iter_{:d}.tar'.format(it), 'red')
Zero-Shot Recognition
不可见样本的视觉特征为:![]()
我们可以生成任意数量的视觉特征,因为z可以无限采样。本文中,采用最邻近距离方法来进行类别判别。
def eval_fakefeat_test(it, netG, dataset, param, result):
gen_feat = np.zeros([0, param.X_dim])
for i in range(dataset.test_cls_num):
text_feat = np.tile(dataset.test_text_feature[i].astype('float32'), (opt.nSample, 1))# opt.nSample:60 number of fake feature for each class
text_feat = Variable(torch.from_numpy(text_feat)).cuda()
z = Variable(torch.randn(opt.nSample, param.z_dim)).cuda()
G_sample = netG(z, text_feat)
gen_feat = np.vstack((gen_feat, G_sample.data.cpu().numpy()))
# cosince predict K-nearest Neighbor
sim = cosine_similarity(dataset.pfc_feat_data_test, gen_feat)
idx_mat = np.argsort(-1 * sim, axis=1)
label_mat = (idx_mat[:, 0:opt.Knn] / opt.nSample).astype(int)
preds = np.zeros(label_mat.shape[0])
for i in range(label_mat.shape[0]):
(values, counts) = np.unique(label_mat[i], return_counts=True)
preds[i] = values[np.argmax(counts)]
# produce acc
label_T = np.asarray(dataset.labels_test)
acc = (preds == label_T).mean() * 100
result.acc_list += [acc]
result.iter_list += [it]
result.save_model = False
if acc > result.best_acc:
result.best_acc = acc
result.best_iter = it
result.save_model = True
print("{}nn Classifier: ".format(opt.Knn))
print("Accuracy is {:.4}%".format(acc))
""" Generalized ZSL"""
def eval_fakefeat_GZSL(it, netG, dataset, param, result):
gen_feat = np.zeros([0, param.X_dim])
for i in range(dataset.train_cls_num):
text_feat = np.tile(dataset.train_text_feature[i].astype('float32'), (opt.nSample, 1))
text_feat = Variable(torch.from_numpy(text_feat)).cuda()
z = Variable(torch.randn(opt.nSample, param.z_dim)).cuda()
G_sample = netG(z, text_feat)
gen_feat = np.vstack((gen_feat, G_sample.data.cpu().numpy()))
for i in range(dataset.test_cls_num):
text_feat = np.tile(dataset.test_text_feature[i].astype('float32'), (opt.nSample, 1))
text_feat = Variable(torch.from_numpy(text_feat)).cuda()
z = Variable(torch.randn(opt.nSample, param.z_dim)).cuda()
G_sample = netG(z, text_feat)
gen_feat = np.vstack((gen_feat, G_sample.data.cpu().numpy()))
visual_pivots = [gen_feat[i*opt.nSample:(i+1)*opt.nSample].mean(0) \
for i in range(dataset.train_cls_num + dataset.test_cls_num)]
visual_pivots = np.vstack(visual_pivots)
"""collect points for gzsl curve"""
acc_S_T_list, acc_U_T_list = list(), list()
seen_sim = cosine_similarity(dataset.pfc_feat_data_train, visual_pivots)
unseen_sim = cosine_similarity(dataset.pfc_feat_data_test, visual_pivots)
for GZSL_lambda in np.arange(-2, 2, 0.01):
tmp_seen_sim = copy.deepcopy(seen_sim)
tmp_seen_sim[:, dataset.train_cls_num:] += GZSL_lambda
pred_lbl = np.argmax(tmp_seen_sim, axis=1)
acc_S_T_list.append((pred_lbl == np.asarray(dataset.labels_train)).mean())
tmp_unseen_sim = copy.deepcopy(unseen_sim)
tmp_unseen_sim[:, dataset.train_cls_num:] += GZSL_lambda
pred_lbl = np.argmax(tmp_unseen_sim, axis=1)
acc_U_T_list.append((pred_lbl == (np.asarray(dataset.labels_test)+dataset.train_cls_num)).mean())
auc_score = integrate.trapz(y=acc_S_T_list, x=acc_U_T_list)
result.acc_list += [auc_score]
result.iter_list += [it]
result.save_model = False
if auc_score > result.best_acc:
result.best_acc = auc_score
result.best_iter = it
result.save_model = True
print("AUC Score is {:.4}".format(auc_score))结果:



2)语义间隔问题(Semantic Gap)
指样本在特征空间中所构成的流形(分布结构)与样本在语义空间中类别构成的流形是不一致的,这使得直接学习两者的映射会有困难。
典型文章:Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths (DMaP)-2017 CVPR
基于流形学习,对语义进行再表示,并且迭代地调整,以对齐两者的流形。
基于嵌入函数的方法有以下几个特点:
- 在K空间中(语义嵌入空间),通常比一般的类别表示具有更复杂的几何结构,例如L空间中(类别标签空间),one-hot编码分布在具有相同边长的超单纯形顶点上。而复杂的集合结构(语义流行空间)可以编码为可见类和不可见类之间的关系;
- 不同的嵌入函数有其独特流行结构,这是导致识别性能上具有明显差异的原因;
- 嵌入函数需要提前确定,并在学习的过程中保持不变。
一些问题:
- 哪种语义流行K是有效的?EZSL这篇文章证明了正交或者随机的向量不可行,但仍然需要对这个问题进行更多的讨论;
- 为什么不同的K性能不同?似乎K的流行结构是一个关键因素,但是仍然缺乏深入的分析;
- 如何构建更好的K来提升不可见类的识别性能?已有的文献都需要一些边缘信息来构建嵌入函数(K),并没有考虑X潜在的流行信息来构建K,这使得K与X是不相关的。
本文中,我们需要将X和K的流行信息通过在可见类上学习一个映射fs,使得二者的流行信息对齐。直接学习映射很困难,因此提出了联合优化K和fs 。

问题描述:



Pre-Inspection of Semantic Space K (语义空间K的预检查):
对于给定的嵌入,通常直接用来学习可见类和不可见类之间的映射,但是对于可见类和不可见类的不同部分,语义流形可能有一些ZSR方法的自然缺陷,可能导致ZSR任务失败。因此提出以下Proposition:
Proposition: 对于两个不可见类的语义空间K,如果他们在S子空间(可见类的嵌入构成)的正交投影是相同的,那么K对于这两个不可见类不具有区分能力。
证明:


当可见类的样本量远小于不可见类时,该缺陷能够被观察到。因此,这个命题对于这样的场景是可取的,可以被认为是实现ZSR之前的一个预检查步骤。
(当可见类的样本量远小于不可见类时,不可见类的K在S空间的投影很有可能重合)
Inter-class Relationship Consistency(IRC)
给定相同的X,不同的K在检测效果上会有明显差异,例如,在AwA数据集上进行与预测时,人工标注的属性比文字属性更好。然而,更多的实验表明,使用同一K不同的X也会造成检测效果的差异,因此,我们推导X和K之间的关联是检测性能好坏的关键。
假设在图像特征空间X有一潜在的标签流行,该流行比语义空间的流行更概括。这个标签级的流行由类别的属性摘要或者语义流行中采样得到。
k个可见类的属性和l个不可见类的属性表示为:
![]()

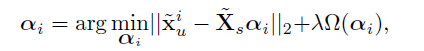

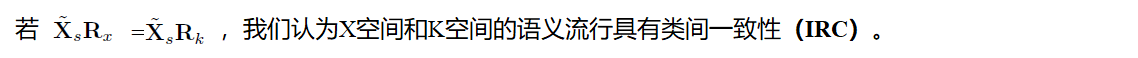


证明:若IRC成立,则:![]()
根据线性映射的异质同性:![]()
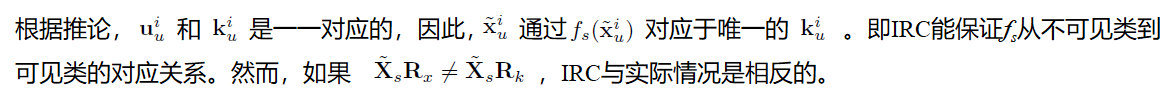
为量化类间关系一致性的度量,提出以下函数:
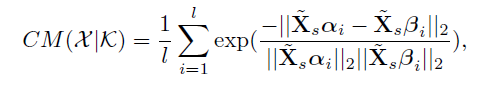
实际应用中,可以采用每个类的均值向量作为类属性或采样器,即:![]()
IRC给了我们一个启示,给定图像特征空间X,语义一致性好的K可以提升 fs 的映射能力,这促使我们构建一个与X语义一致性更好的K。因此,我们提出了一个简单的方法来优化K和 fs 。
三步训练法:
Step 1: Learn the visual-semantic mapping:![]()
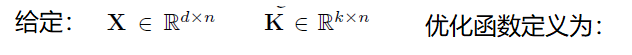
![]()
l(.) is the general loss function, e.g. hinge loss, logistic loss etc. 本文中,这些损失函数对于结果差别不大。采用了平方差损失。
类别级的流行采用 fs(X) 的均值表示而非 X 的均值,原因有2:首先,考虑一个类中的实例分布在一个复杂流形上的情况,例如新月流形,显然它的平均向量不能作为这个类的原型或范例。其次,当我们将这一步应用到实例没有标记的测试阶段时,我们不能准确地分辨哪些实例属于某个特定的类别,因此无法得到它们的平均向量。
我们在流形学习中利用了这样的思想:如果实例的语义表示和类的嵌入在同一个局部流形结构上,它们很可能来自同一个类。

Step 3: Align manifolds iteratively.


测试:

结果:



未完,待续。。。
参考文章:
[1] Fu Y, Hospedales T M, Xiang T, et al. Transductive multi-view zero-shot learning[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(11): 2332-2345.
[2] Kodirov E, Xiang T, Gong S. Semantic autoencoder for zero-shot learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3174-3183.
[3] Zhu Y, Elhoseiny M, Liu B, et al. A generative adversarial approach for zero-shot learning from noisy texts[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1004-1013.
[4] Li Y, Wang D, Hu H, et al. Zero-shot recognition using dual visual-semantic mapping paths[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3279-3287.















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









