







主成分分析法原理及其python实现
前言:
这片文章主要参考了Andrew Ng的Machine Learning课程讲义,我进行了翻译,并配上了一个python演示demo加深理解。
本文主要介绍一种降维算法,主成分分析法,Principal Components Analysis,简称PCA,这种方法的目标是找到一个数据近似集中的子空间,至于如何找到这个子空间,下文会给出详细的介绍,PCA比其他降维算法更加直接,只需要进行一次特征向量的计算即可。(在Matlab,python,R中这个可以轻易的用eig()函数来实现)。
假设我们给出这样一个数据集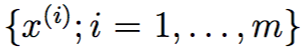
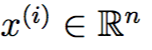
再举一个更加具体的例子,我们现在拥有一个由对遥控直升机飞行员的问卷调查得出的数据集,第i个数据点的第一个分量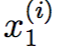
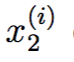
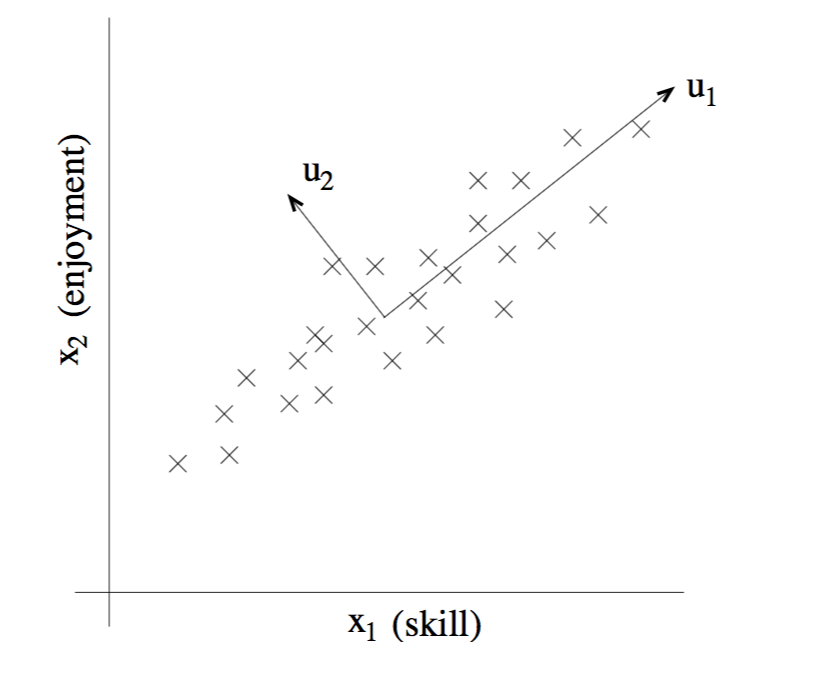
没错,计算u1这个方向的方法就是PCA算法,但是在数据集上运行PCA算法之前,通常我们要首先对数据进行预处理来标准化数据的均值和方差。下面是预处理过程:
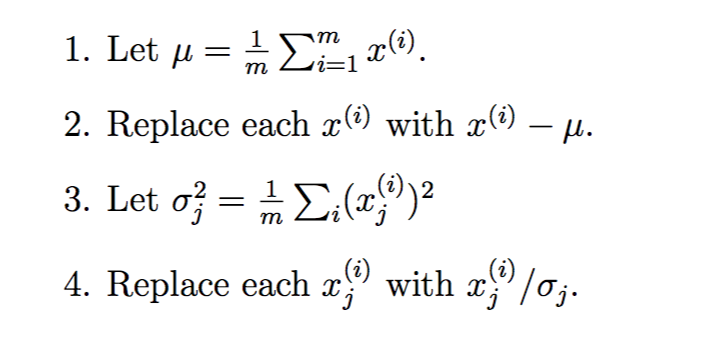
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









