









关联嵌入:联合检测和分组的端到端学习
Alejandro Newell, Zhiao Huang, Jia Deng
参考文献
https://simochen.github.io/2017/12/25/associative-embedding/

摘要
本文介绍了一种用于检测和分组任务的监督卷积神经网络方法--联合嵌入associative embedding。以这种方式可以建立多人姿态估计、实例分割和多目标跟踪等多种计算机视觉问题。通常检测的分组是通过多级流程pipeline实现的, 相反, 我们提出了一种方法, 教网络同时输出检测和分组分配。这种技术可以很容易地集成到任何最先进的网络体系结构中, 从而产生像素级的预测。我们展示了如何将此方法应用于多人姿态估计和实例分割, 并在 MPII 和 MS-COCO 数据集上报告多人姿态的最先进性能。
1. Introduction 介绍
许多计算机视觉任务可以看作是联合的检测和分组: 检测较小的视觉单元并将它们分组到更大结构中。例如, 多人姿态估计可以看作是检测身体关节, 并将其分组到个体中; 实例分割可以看作是检测相关像素并将其分组到目标实例中; 多目标跟踪可以被看作是检测对象实例并将其分组到轨道中。在所有这些情况下, 输出都是可变数量的视觉单元同时它们也要分组到可变数量的组别中。
这类任务通常由双阶段流程来处理, 即先检测后分组。但这种方法可能是次优的, 因为检测和分组通常是紧密耦合的: 例如, 在多人姿势估计中, 如果附近没有肘部检测可与之进行的检测, 则手腕检测很可能是假阳性。
本文探讨了使用单级深度网络端到端训练的联合执行检测和分组的可能性。我们提出了一种表示联合检测和分组输出的新方法--联想嵌入。其基本思想是为每一种检测引入一个实数, 作为 "标记" 来标识检测所属的组。换句话说, 标记将每个检测与同一组中的其他检测相关联。
考虑二维中检测和一维嵌入 (实数) 检测的特殊情况。网络输出像素级检测热图和像素级标记热图,然后解码检测和分组信息。
为了训练网络来预测标记, 我们使用一个损失函数, 如果相应的检测属于标注真值中的同一组则会鼓励对标记具有相似的值,否则不相似的值。需要注意的是, 我们没有标注真值标签供网络预测, 因为重要的不是特定的标签值, 而是它们之间的差异。网络可以自由地决定标记值, 只要它们与标注真值分组一致。
我们将我们的方法应用于多人姿态估计, 这是理解图像中人类的一项重要任务。 Concretely具体而言, 给定一个输入图像, 多人姿态估计寻求检测每个人和定位他们的身体关节点。与单人姿势不同的是, 事先对一个人的位置或体型没有任何假设。多人姿势系统必须扫描整个图像检测所有的人和他们的相应的关键点。对于此任务, 我们将关联嵌入与堆叠沙漏网络 [31] 集成在一起, 该网络为每个身体关节生成检测热图和标记热图, 然后将具有相似标记的身体关节分组到个人中。实验表明, 我们的方法优于所有最新的方法, 并在 MS-COCO [27] 和 MPII 多人姿势 [3, 35] 上取得了最先进的结果。
我们进一步论证了我们的方法的效用, 将其应用于实例分割。表示将关联嵌入应用于适合于检测再分组的各种视觉任务是直接的。
我们的贡献有两个方面: (1) 引入关联嵌入, 这是一种单级、端到端联合检测和分组的新方法。此方法简单、通用;它适用于任何产生像素级预测的网络体系结构;(2) 将关联嵌入应用于多人姿态估计, 并在两个标准基准上实现最先进的结果。
2. Related Work 相关工作
Vector Embeddings 向量嵌入:我们的方法与许多使用矢量嵌入的早期工作有关。在图像检索image retrieval中的工作使用矢量嵌入来测量图像之间的相似性 [17, 53]。在image classification, image captioning, and phrase localization图像分类、图像字幕和短语定位方面, 使用矢量嵌入通过将视觉特征和文本特征映射到相同的矢量空间 [16、20、30] 来连接视觉特征和文本特征。在自然语言处理的研究中使用矢量嵌入来表示单词、句子和 [39, 32] 段的含义。我们的工作与之前的工作不同, 因为我们在联合检测和分组的背景下使用矢量嵌入作为标识标记。
Perceptual Organization感知组织:在感知组织中的工作旨在将图像的像素分组到区域、部分和对象中。感知组织encompasses包括一系列不同复杂的任务, 从 figure-ground segmentation图形-地面分段 [37] 到hierarchical image parsing分层图像解析 [21]。早期工作典型地使用双阶段流程 [38], 首先检测基本的视觉单位 (补丁、超级像素、部件等), 然后将它们分组。常见的分组方法包括spectral clustering谱聚类 [51, 46]、条件随机场(例如 [31]), 和生成概率模型(例如 [21])。这些分组方法都假设了预先检测到的基本视觉单位和它们之间预先计算的亲和力度量affinity measures, 但在将亲和力度量转化为分组的过程中, 它们之间的亲和力不同。相反, 我们的方法在一个阶段中使用通用网络进行性能检测和分组, 该网络不包括特殊的分组设计。
It is worth noting值得注意的是, 我们的应用与使用谱聚类的方法之间有着密切的联系。谱聚类 (如归一化切割 [46]) 技术将视觉单元之间的输入预先计算的相关性 (如深度网络预测) 作为输入, 并解决了一个 generalized eigenproblem广义特征问题, 以产生高亲和力视觉单位具有高相似度的嵌入表达。 Angular Embedding角型编码 [37, 47] 通过嵌入深度顺序和分组来扩展谱聚类。我们的方法不同于谱集群, 因为我们没有亲和力的中间表示, 也不解决任何特征问题。相反, 我们的网络直接输出最终的嵌入。
我们的方法也与Harley et al. 在学习密集卷积嵌入[24]的工作有关,该工作训练深度网络为语义分割任务产生像素级嵌入表达。我们的工作与他们的不同, 因为我们的网络不仅产生像素级的嵌入, 而且还产生像素级的检测分数。我们的新颖性在于将检测和分组整合到一个单一的网络中; 就我们所知,多人姿态估计中这种整合并没有被尝试过。
Multiperson Pose Estimation 多人姿态估计:最近的方法极大的改进了人体姿态估计, 特别是对单人姿势估计的方法 [50、48、52、40、8、5、41、4、14、19、34、26、7、49、44]。对于多人姿态, 早期和现在的工作可以分为自上而下或自下而上。自上而下的方法 [42, 25, 15]首先检测人体实例individual people, 然后估计每个人的姿态。自下而上的方法 [45, 28, 29, 6] 相反, 检测身体关节点实例individual body joints, 然后将它们分组成人体实例。我们的方法更类似于resembles自下而上的方法, 但不同的是没有检测和分组阶段的分离。整个预测是在单级通用网络上完成的。这就消除了其他方法所要求的复杂后处理步骤的需要 [6, 28]。
Instance Segmentation实例分割:大多现有的实例分割方法使用多级流程来进行先检测后分割 [23、18、22、11]。Dai[12] 通过一个由空间坐标来反向传播的特殊网络层,使得这样的流程可微分。
最近两项作品通过全卷积网络找到了更紧密地整合检测和分割任务的方法。DeepMask [43] 密集地扫描子窗口, 并为每个子窗口输出检测分数和分割掩码 (整型为矢量)。Instance-Sensitive FCN[10]将每个目标视为由一组规则网格中的对象部件组成, 并为每个对象部件输出检测分数的像素级热图。IS-FCN的中心表示对象实例, 其中部件检测得分与方向一致, 并从对象部件的热图中组装对象掩码。与 DeepMask和IS-FCN相比, 我们的方法要简单得多: 对于每个对象类别, 我们在每个像素位置只输出两个值, 即表示前景与背景的核心值, 以及表示对象实例标识的标记, 而生成更高的维数输出。
3. Approach
3.1. Overview
为了引入联合检测和分组的关联嵌入, 我们首先回顾了视觉检测的基本公式。许多视觉任务涉及一组视觉单元的检测。这些任务通常是被作为对大量候选人的打分。例如, 单人姿势估计可以视为对所有可能像素位置的候选人体关节打分。对象检测可以视为在不同像素位置、比例和长宽比的候选边界框打分。
联想嵌入的思想是对每个候选除了检测分数外, 还有一个嵌入。嵌入用作对编码分组的标记: 具有类似标记的降级应组合在一起。多人人姿势估计中, 身体关节标签类似的分组形成一个人。值得注意的是, 标记的绝对值并不重要, 只有标记之间的距离。也就是说, 只要属于同一组的检测的值相同, 网络就可以自由地为标记分配任意值。
请注意, 嵌入的尺寸不是决定性的。如果网络能够成功地预测高维嵌入, 将检测分离成组, 它也应该能够学习将这些高维嵌入投影到较低的维数, 只要有足够的网络容量。在实践中, 我们发现一维嵌入式对于多人姿态估计是足够的, 而更高的维度并不能带来显著的改善。因此在本文中, 我们假设一维嵌入。
为了训练网络来预测标签, 我们强制实施类似的标签, 鼓励从同一组检测类似的标签, 为不同组的检测提供不同的标签。具体而言, 这种标记损失是在与标签真值一致的候选检测上强制进行的。我们比较检测对儿并根据其标记的相对值以及检测是否应该来自同一组别定义惩罚.
3.2. Stacked Hourglass Architecture 堆叠沙漏架构
在本工作中, 我们将关联嵌入与堆叠沙漏体系结构 [40] 结合在一起, 后者是一个密集像素级预测模型, 由一系列像沙漏一样的模块组成 (图 2)。每个 "沙漏" 都有一组标准卷积和池化层,这些层将特征下采样到低分辨率以捕获图像的全文。而后, 对这些特征上采样, 并逐步与来自更高的分辨率转的输出组合, 直到达到最终的输出分辨率。堆叠多个沙漏可以重复的自下而上和自上而下的推断, 从而产生更准确的最终预测。有关网络体系结构的更多详细信息, 我们请读者参考 [40]。

堆叠沙漏模型最初是为单人姿态估计而开发的。该模型为目标人体的每个身体关节提供了一个热图。然后, 将热图激活最高的像素位置作为该关节的预测。该网络旨在整合consolidate全局和局部特征, 用于收集有关身体完整结构的信息, 同时保留精细细节, 以便精确定位。全局和局部特征之间的这种平衡在其他像素级预测任务中同样重要, 因此我们将相同的网络应用于多人姿态估计和实例分割。
我们对网络结构做了一些轻微的修改。我们在分辨率下降时 (256-> 386-> 512-> 768) 时增加了输出特征的数量。此外, 各个层由3x3卷积而不是残差模块组成, 缓解训练的shortcut effect效果仍然存在于每个沙漏的剩余环节上, 以及每个分辨率的跳跃连接。
3.3. Multiperson Pose Estimation 多人姿态估计
为了将关联嵌入应用于多人姿态估计, 我们训练网络像单人姿态估计一样检测关节 [40]。我们使用堆叠沙漏模型来预测每个身体关节 ("左手腕"、"右肩" 等) 在每个像素定位上的检测分数, 而不考虑个体实例。与单人不同的是, 一个理想的多人姿态估计热图应该有多个高峰 (例如, 以确定属于不同的人的多重手腕), 而不是只是一个单一的高峰对某个人。
除了生成全部关键点检测外, 网络还自动将检测分组为个体实例姿态。为此, 网络将在每个关节的像素位置生成一个标记。换句话说, 每个关节热图都有相应的 "标签" 热图。因此, 如果有m个人体关节需要预测, 那么网络将输出总共2m通道, m用于检测和m用于分组。为了将检测解析成个体实例, 我们使用非最大抑制来获取每个关节的峰值检测, 并在相同的像素位置检索其相应的标记 (如图3所示)。然后, 我们通过比较检测的标记值和匹配足够接近的标记值, 对整个人体关节点检测进行分组。而后一组检测形成了一个人的姿势估计。
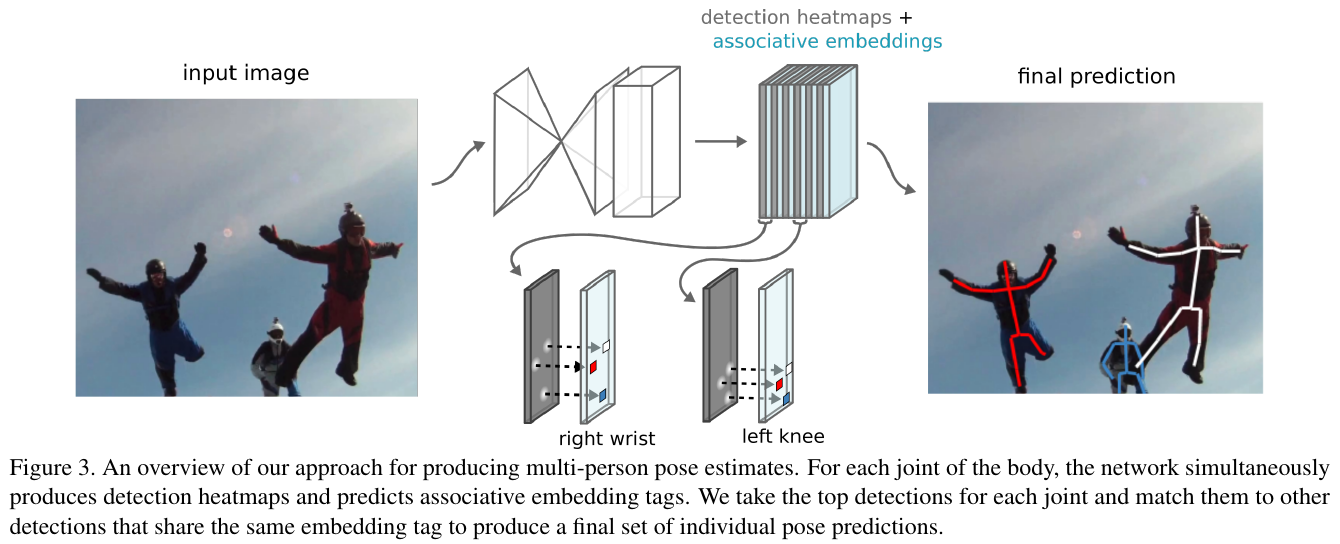
为了训练网络, 我们在输出热图上施加了检测损失和强化损失。检测损失计算每个预测检测热图及其 "地面真理" 热图之间的平均平方误差, 该真值热图由每个关键点位置上的二维高斯激活组成。这种损失与Newell 等人使用的相同。
分组损失评估预测的标签与地面真相分组的契合程度。具体而言, 我们为所有人在他们所有身体关节的地面真相位置检索预测的标签; 然后, 我们比较个体内和个体间的标签。个体内的标签应该是一样的, 而个体间的标签应该是不一样的。
与其在所有可能的关键点对之间强制施加损失, 我们为每个每个个体生成一个参考嵌入。这是通过取每个个体关节的输出嵌入的平均值来实现的。在每个个体中, 我们计算出每个关节的预测嵌入与参考嵌入之间的平方距离。然后, 在每对人之间, 我们将他们的参考嵌入相互比较并施加随着两个标签之间的距离增加呈指数下降到零的惩罚。
形式上, 设是标记第k个身体关节的预测热图, 其中h (x)是像素位置 x 的标记值。给定 N 个人, 设地面真值身体关节位置为
其中
是第 n 人的 k 身体关节的地面真相像素位置。
假设所有的 K 关节都有注释, 第 n 个人的参考嵌入将是

为了产生最后一个最终预测集合,我们对每个关节点进行迭代。迭代的顺序是先考虑头和躯干而后逐渐像肢体移动。我们从第一个关节点开始,NMS后得到每个超过阈值的关节点。这些关键点组组成了我们待检测人的最初候选池。
我们之后考虑检测后续的关节点。我们将后续关节点与我们现有关节点候选池相比,得到其最优匹配。只有当两个标记相差小于一个特别的阈值时才会被匹配。除此之外,我们因此基于标记距离和检测分数的最大匹配。如果没有任何检测额被匹配,则被视为一个新的人体实例。这种情况可能是因为某个特定人体只有手或脚可见。
我们在每类关节点上循环匹配,直到每个检测都被匹配到一个人。没有任何步骤被执行来确保解剖学的正确性和关键点之间的空间关系。To give an impression of为了展示神经网络学习的标记和自然匹配,我们画出了图4.

尽管训练网络来预测所有尺寸大小的人体是可行的,但这存在一些缺陷。额外的容量将被用来学习必要的尺度不变性,同时小尺寸的人体将会遇到经过池化后低分辨率的困难。为了解决这个问题,我们在测试时在不同尺度下对图片进行了评测。这里使用了一些可能的方法来利用不同尺度的输出来产生最终姿态估计。在我们的打算中,我们将产生的热图平均起来输出。然后,为了融合不同尺度下的标记,我们我们将标记集合中同一点坐标连接成一个向量 (assuming m scales). 解码过程不变即标量标记值的方法,我们现在只是比较向量距离。
3.4. 实例分段
实例分割的目标是检测和分类对象实例, 同时为每个对象提供分割掩码。作为概念的证明, 我们向您展示了如何应用我们的方法来解决这个问题, 并演示了初步的结果。与多人姿态估计一样, 实例分段是一个联合检测和分组的问题。检测到属于对象类的像素, 然后将与单个对象关联的像素组合在一起。简单地下面我们的方法的描述只假设了一个对象类别。
给定输入图像, 我们使用堆叠沙漏网络生成两个热图, 一个用于检测, 一个用于标记。检测热图给出了每个像素的检测分数, 指示像素是否属于对象类别的任何实例, 即检测热图从背景中分割出前景。同时, 标记热图标记每个像素, 以便属于同一对象实例的像素具有类似的标记。
为了训练网络, 我们通过将预测的热图与地面热图 (所有实例掩码的并集) 进行比较来监督检测热图。损失是两个热图间的MSE。我们通过施加损失来监督标记热图, 该损失鼓励标记在对象实例中相似, 并在不同实例之间进行不同。损失的表述与多人姿势的表述相似。无需对实例分段掩码中的每个像素进行比较。相反, 我们随机抽取来自每个对象实例的一小部分像素, 并对一组采样像素进行成对比较。
形式上, 让 是一个预测的 WxH 标记热图。让x表示像素位置, h (x) 标记在该位置处的标记值, 让
是在 n 个对象实例中随机采样的一组位置。分组损失 Lg 被定义为

为了对网络的输出进行解码, 我们首先对检测通道热图进行阈值, 以生成二进制掩码。然后, 我们查看此掩码. 计算标记的直方图, 并执行非最大抑制, 以确定一组值, 以用作每个对象实例的标识符。然后, 检测掩码每个像素将其分组到给最接近其标记值的某对象。图5用于说明此过程。

请注意, 将对象类别推广到多个对象很简单: 我们只需输出检测热图和每个对象类别的标记热图。我们不是训练一个网络来识别对象实例在各种可能的尺度上的外观, 而是在多个尺度上进行评估, 并将预测与姿势估计的预测方式结合起来。
4. Experiments
4.1. Multiperson Pose Estimation
Dataset 我们评估两个数据集: MS-COCO [35] 和MPII人体姿势 [3]。MPII 人类姿势包括大约25k图像, 包含约40 k加注释的人 (其中四分之三可用于训练)。评估是在 MPII Multi-Person, 一组如[45]列出从测试集采取了的1758样本。这个MPII 多人组通常是特定图像中总人员的子集, 因此提供了一些信息, 以确保预测是针对正确的目标。这包括一个通用的边界框和尺度参数, 用于指示被占领的区域。没有提供关于人数或个人数字比例的信息。我们使用 Pishchulin 等人的评价指标计算关节检测的平均精度。
MS-COCO [35] 包括大约60K 训练图象与超过100 k人与注释的关键点。我们报告了两个测试集 (一个开发测试集 (test-dev) 和一个标准测试集 (test-std)) 的性能。我们使用官方评估指标, 以类似于对象检测的方式报告平均精度 (AP) 和平均召回 (AR), 只是使用了基于关键点距离的分数而不是边界框重叠。有关详细信息, 请向读者推荐 MS-COCO 网站 [1]。
Implementation 用于此任务的网络一致为四个堆叠沙漏模块, 输入大小为512×512, 输出分辨率为128x128。我们使用tensorflow 以32大小的批处理进行网络训练, 初始学习率为2e-4(在100k 迭代后衰减为1e-5)。关联嵌入损耗的权重为1e-3 的因子, 相对于检测热图的 MSE 损耗。损失函数使用掩码忽略了稀疏注释的人群。在测试时, 输入图像以多个尺度运行;输出检测热图在比例之间平均, 而跨比例的温图标记被连接到更高的尺寸中。由于 MPII 和 MS-COCO 的度量对关键点的精确定位非常敏感, 因此在之前的工作 [6] 之后, 我们在同一数据集上训练了一个单人姿势模型 [40], 以进一步细化预测。
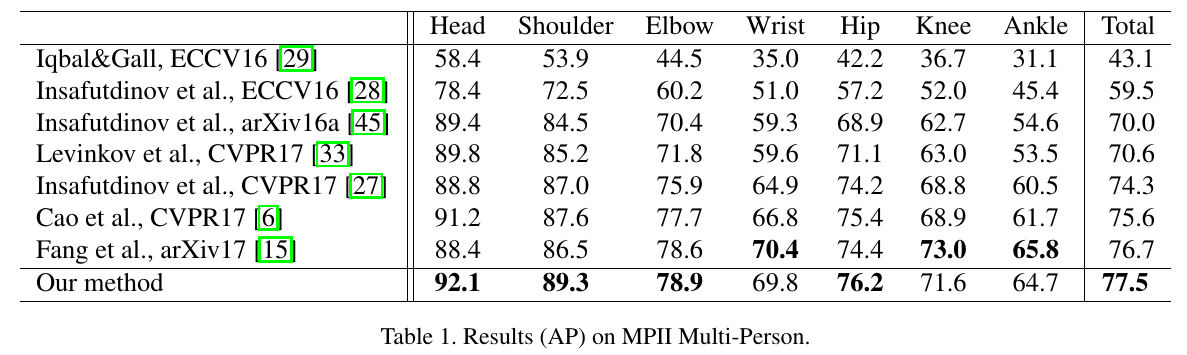
MPII Results 在表1中可以看到平均精度结果, 总的表明其在AP中上有较大改进. 联合嵌入被证明是将网络进行分组关键点检测到个人的有效方法。它对图像中存在的人数没有任何假设, 也为网络提供了一种分配混乱关节的表达机制。例如, 如果两个人的相同连接在完全相同的像素位置重叠, 则预测的关联嵌入将是一个介于两个个体之间的某个标记。
我们可以利用嵌入热图的可视化 (图 7)更好地了解嵌入输出的关联输出。我们特别关注的是预测的差异, 当人们严重重叠严重的闭塞和接近的间隔检测到的关节, 使它更难以解析个别人的姿势。

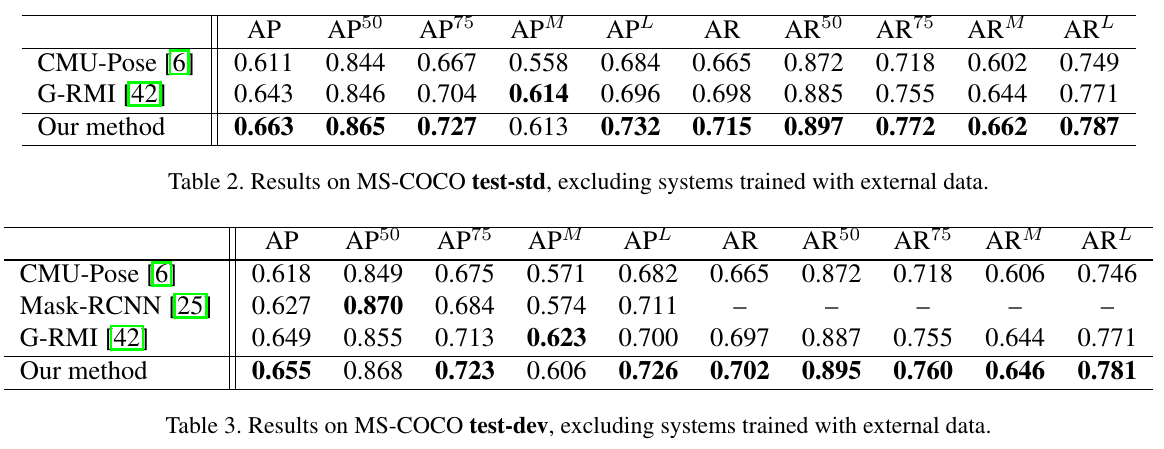
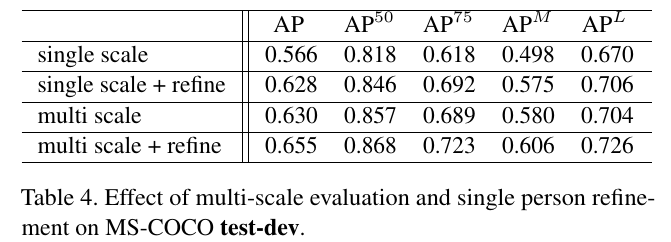
MS-COCO Results 表2和表3报告了我们对 MS-COCO 的影响。我们报告test-std 和test-dev的结果, 因为并非所有最近的方法都在test-std上报告。我们看到, 在这两套中, 我们都实现了SOTA的水平。如图6所示, 是网络预测扫描的示意图。网络的典型故障情况源于杂乱场景中的重叠和闭塞的关节。表4报告了我们的完整管道的烧蚀版本的性能, 显示了在多个尺度上应用我们的模型和使用单人姿态估计器进一步细化的贡献。我们看到, 在多个尺度上简单地应用我们的网络已经达到了与以前最先进的方法相比有竞争力的性能, 这表明了我们的端到端联合检测和分组的有效性。

我们还对 MS-COCO进行了额外的实验, 以衡量检测相对于分组的难度, 即哪一部分是我们系统的主要瓶颈。我们在一组500张训练图像上利用留一法对我们的系统进行评估。在本评价中, 我们用地面真相的检测取代预测的检测, 但仍然使用预测的标签。使用地面真相检测可将AP从59.2 检测提高到94.0。这表明, 关键点检测是我们系统的主要瓶颈, 而网络已经学会了产生高质量的分组。这一事实也可由对预测的标记值进行定性检查来支持, 如图4所示, 从中我们可看到标记得到很好分离, 并且对解码分组也非常简单。
4.2. Instance Segmentation
Dataset 对于评估, 我们使用 PASCAL VOC 2012 [13] 的 val 分割数据, 包括 1, 449 张图像。附加预训练是用 MS COCO [35] 的图像完成的。在不同 IOU 阈值下, 利用平均精度计算。[22, 10, 36]
Implementation 该网络采用Torch框架[9]并以256x256的输入分辨率和64x64 的输出分辨率来训练。关联嵌入损失权重为1e-4。在训练过程中, 为了考虑到尺度, 只有出现在特定大小范围内的对象受到监督, 并且使用损失掩码来忽略太大或太小的对象。在 PASCAL VOC 忽略区域在对象边框也被定义,我们将这些区域包括在损失掩码中。在 MS COCO 上从零开始进行为期三天的训练, 然后在 PASCAL VOC 上进行了12小时的微调训练。在测试时从图像的3个比例 (x0.5、x0.5 和 x0.5) 下计算输出。我们在每个比例生成实例建议并执行非最大抑制, 而不是生成平均热图,以消除跨比例的重叠建议。一种更为复杂的多尺度评价方法是值得进一步探索的。
Results 我们在表4.2 中显示了 PASCAL 2012 的 val 集合上的 mAP 结果, 以及图8中的一些定性示例。我们提供这些结果作为概念的证明, 关联嵌入能以这种方式使用。我们使用多人姿势的监控实现了合理的实例分割预测。调整训练和后处理可能会提高性能, 但主要的卖点main takeaway是, 关联嵌入以一种通用的技术对不同的计算机视觉任务都工作得很好, 这些任务都属于 fall under the umbrella of 检测和分组问题范畴。

5. Conclusion
在本工作中, 我们将联想嵌入引入卷积神经网络, 使其能够同时进行检测和分组。我们将该方法应用于两个视觉问题: 多人姿势估计和实例分割。我们展示了对这两项任务进行训练的可行性, 并在姿态上我们实现了最佳性能。我们的方法很一般, 也可以应用到其他视觉问题上, 比如视频中的多对象跟踪。关联嵌入损失可以在给定任何产生像素预测的网络上实施, 因此它可以很容易地与其他最先进的体系结构集成。














 7170
7170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









