









之前有总结过hive谓词下推优化:
从一个sql引发的hive谓词下推的全面复盘及源码分析(上)
从一个sql引发的hive谓词下推的全面复盘及源码分析(下)
spark sql谓词下推逻辑优化器PushDownPredicates包含了三个规则:


PushPredicateThroughJoin是sparksql中join(包括inner、left、right、full)情况的谓词下推的逻辑执行计划优化器
PushPredicateThroughJoin在处理Filter节点下为outerJoin情况时,会结合outerjoin消除优化器共同起作用Spark sql逻辑执行计划优化器——EliminateOuterJoin【消除outerjoin】
谓词可以下推的前提:不影响查询结果,要保证下推前和下推后两个sql执行得到的效果相同
代码流程

object PushPredicateThroughJoin extends Rule[LogicalPlan] with PredicateHelper {
//split方法把condition分为三部分:左侧数据表的字段,右侧数据表的字段,不可以下推的字段(包括不确定性+不在左右表outputset里的字段)
private def split(condition: Seq[Expression], left: LogicalPlan, right: LogicalPlan) = {
val (pushDownCandidates, nonDeterministic) = condition.partition(_.deterministic)
val (leftEvaluateCondition, rest) =
pushDownCandidates.partition(_.references.subsetOf(left.outputSet))
val (rightEvaluateCondition, commonCondition) =
rest.partition(expr => expr.references.subsetOf(right.outputSet))
(leftEvaluateCondition, rightEvaluateCondition, commonCondition ++ nonDeterministic)
}
def apply(plan: LogicalPlan): LogicalPlan = plan transform applyLocally
val applyLocally: PartialFunction[LogicalPlan, LogicalPlan] = {
// Filter+join的情况
case f @ Filter(filterCondition, Join(left, right, joinType, joinCondition, hint)) =>
val (leftFilterConditions, rightFilterConditions, commonFilterCondition) =
split(splitConjunctivePredicates(filterCondition), left, right)
joinType match {
case _: InnerLike =>
//Inner Join 把过滤条件下推到参加Join的两端
val newLeft = leftFilterConditions.
reduceLeftOption(And).map(Filter(_, left)).getOrElse(left)
val newRight = rightFilterConditions.
reduceLeftOption(And).map(Filter(_, right)).getOrElse(right)
val (newJoinConditions, others) =
commonFilterCondition.partition(canEvaluateWithinJoin)
val newJoinCond = (newJoinConditions ++ joinCondition).reduceLeftOption(And)
val join = Join(newLeft, newRight, joinType, newJoinCond, hint)
if (others.nonEmpty) {
Filter(others.reduceLeft(And), join)
} else {
join
}
case RightOuter =>
// RightOuter,把where子句的右侧数据表的过滤条件下推到右侧数据表
val newLeft = left
val newRight = rightFilterConditions.
reduceLeftOption(And).map(Filter(_, right)).getOrElse(right)
val newJoinCond = joinCondition
val newJoin = Join(newLeft, newRight, RightOuter, newJoinCond, hint)
(leftFilterConditions ++ commonFilterCondition).
reduceLeftOption(And).map(Filter(_, newJoin)).getOrElse(newJoin)
case LeftOuter | LeftExistence(_) =>
// LeftOuter,把where子句中左侧数据表的过滤条件下推到左侧数据表。
val newLeft = leftFilterConditions.
reduceLeftOption(And).map(Filter(_, left)).getOrElse(left)
val newRight = right
val newJoinCond = joinCondition
val newJoin = Join(newLeft, newRight, joinType, newJoinCond, hint)
(rightFilterConditions ++ commonFilterCondition).
reduceLeftOption(And).map(Filter(_, newJoin)).getOrElse(newJoin)
case FullOuter => f // FullOuter,不会下推where子句的过滤条件到数据表
case NaturalJoin(_) => sys.error("Untransformed NaturalJoin node")
case UsingJoin(_, _) => sys.error("Untransformed Using join node")
}
// Join+on的情况
case j @ Join(left, right, joinType, joinCondition, hint) =>
val (leftJoinConditions, rightJoinConditions, commonJoinCondition) =
split(joinCondition.map(splitConjunctivePredicates).getOrElse(Nil), left, right)
joinType match {
case _: InnerLike | LeftSemi =>
// Inner Join把on子句的过滤条件下推到参加Join的两端的数据中
val newLeft = leftJoinConditions.
reduceLeftOption(And).map(Filter(_, left)).getOrElse(left)
val newRight = rightJoinConditions.
reduceLeftOption(And).map(Filter(_, right)).getOrElse(right)
val newJoinCond = commonJoinCondition.reduceLeftOption(And)
Join(newLeft, newRight, joinType, newJoinCond, hint)
case RightOuter =>
// RightOuter,把on子句中左侧数据表的过滤条件下推到左侧数据表中
val newLeft = leftJoinConditions.
reduceLeftOption(And).map(Filter(_, left)).getOrElse(left)
val newRight = right
val newJoinCond = (rightJoinConditions ++ commonJoinCondition).reduceLeftOption(And)
Join(newLeft, newRight, RightOuter, newJoinCond, hint)
case LeftOuter | LeftAnti | ExistenceJoin(_) =>
// LeftOuter,把on子句中右侧数据表的过滤条件下推到右侧数据表中。
val newLeft = left
val newRight = rightJoinConditions.
reduceLeftOption(And).map(Filter(_, right)).getOrElse(right)
val newJoinCond = (leftJoinConditions ++ commonJoinCondition).reduceLeftOption(And)
Join(newLeft, newRight, joinType, newJoinCond, hint)
case FullOuter => j //FullOuter,则不会下推on子句的过滤条件到数据表
case NaturalJoin(_) => sys.error("Untransformed NaturalJoin node")
case UsingJoin(_, _) => sys.error("Untransformed Using join node")
}
}
}1、处理Filter节点下为Join(包括inner、left、right、full)节点的情况
1.1 inner join
Filter+inner join:把过滤条件下推到参加Join的两端

1.2 right join
Filter+right join,把where子句的右侧数据表的过滤条件下推到右侧数据表。在这个案例中因为满足【right outer join 且左表有过滤操作】这个条件,EliminateOuterJoin (outer join消除优化器) Spark sql逻辑执行计划优化器——EliminateOuterJoin【消除outerjoin】把right join 转成了 inner join ,因此,两侧都做了下推

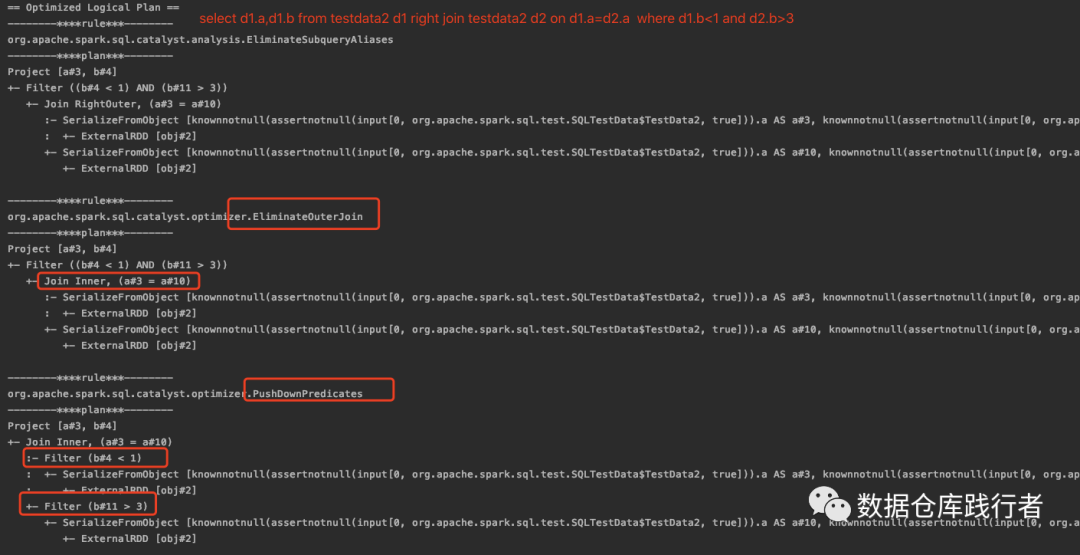
1.3 left join
Filter+left join,把where子句的左侧数据表的过滤条件下推到左侧数据表

1.4 full join
Filter+full join,谓词下推优化器不会下推where子句的过滤条件到数据表, 在这个案例中因为满足【full join 且左表有过滤操作】这个条件,EliminateOuterJoin (outer join消除优化器) 把full join 转成了 left join ,因此Filter+full join —转化—>Filter+left join 。而PushPredicateThroughJoin对Filte+left join的形式做了下推。


2、处理Join节点中谓词在on里的情况
2.1 inner join
Inner Join+on,把on子句的过滤条件下推到参加Join的两端的数据中

2.2 right join
Right join+on,把on子句中左侧数据表的过滤条件下推到左侧数据表中

2.3 left join
left join+on,把on子句中右侧数据表的过滤条件下推到右侧数据表中

2.4 full join
full join+on,不能下推,不做任何操作

总结
EliminateOuterJoin+PushPredicateThroughJoin共同的效果

Hey!
我是小萝卜算子
每天学习一点点
知识增加一点点
思考深入一点点
在成为最厉害最厉害最厉害的道路上
很高兴认识你
推荐阅读:
从一个sql引发的hive谓词下推的全面复盘及源码分析(上)
从一个sql引发的hive谓词下推的全面复盘及源码分析(下)
Spark sql逻辑执行计划优化器——EliminateOuterJoin【消除outerjoin】
spark sql非join情况的谓词下推优化器PushPredicateThroughNonJoin
Spark sql Expression的deterministic属性
















 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











