






一、前言

随着人工智能在图像生成,文本生成以及多模态生成等领域的技术不断累积,如:生成对抗网络(GAN)、变微分自动编码器(VAE)、normalizing flow models、自回归模型(AR)、energy-based models以及近年来大火的扩散模型(Diffusion Model)。
- ANN,人工神经网络
- RBF NN,径向基函数神经网络
- DBN,深度信念网络
- GAN,生成对抗网络,Dropout
- DNN,深度神经网络
- FCN,全卷积网络
- CNN,卷积神经网络,MCNN多列卷积神经网络,ResNets残差网络,Inception,Xception
- RNN,循环神经网络,BRNN双向循环神经网络、DRNN深层循环神经网络
- LSTM,长短期记忆网络
- AE,自编码器
- GNN,图神经网络,GCN图卷积网络,图注意力机GAT
作者:紫璇冥
链接:https://www.zhihu.com/question/447419811/answer/2372931834
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
扩散模型的成功并非横空出世一般,突然出现在人们的视野中。其实早在2015年就已有人提出相类似的想法,最终在2020年提出了我们所熟知的“denoising diffusion probabilistic models”。DDPM
二、运作过程
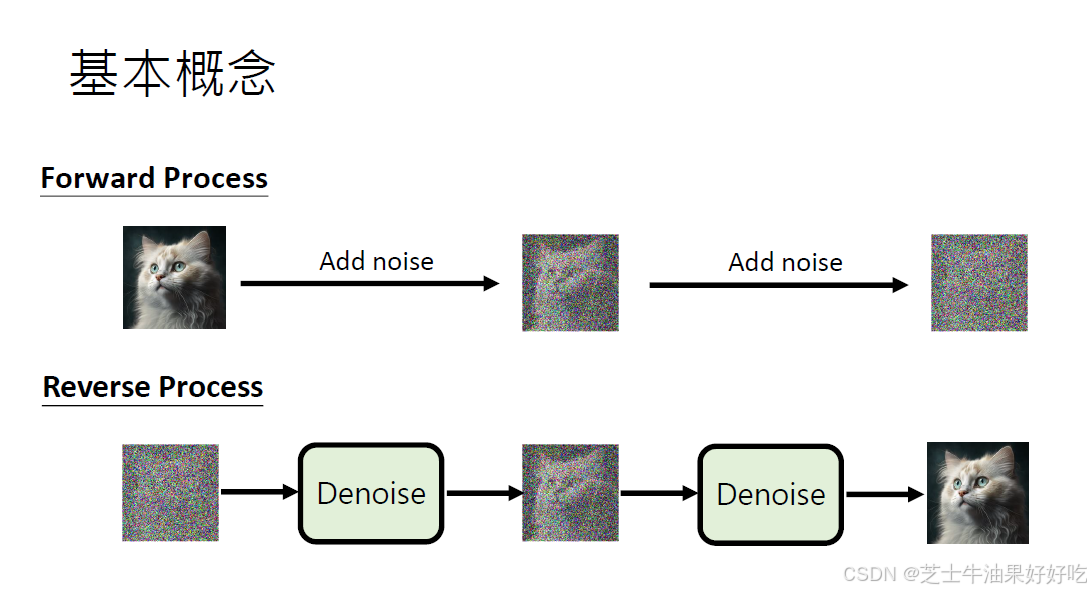
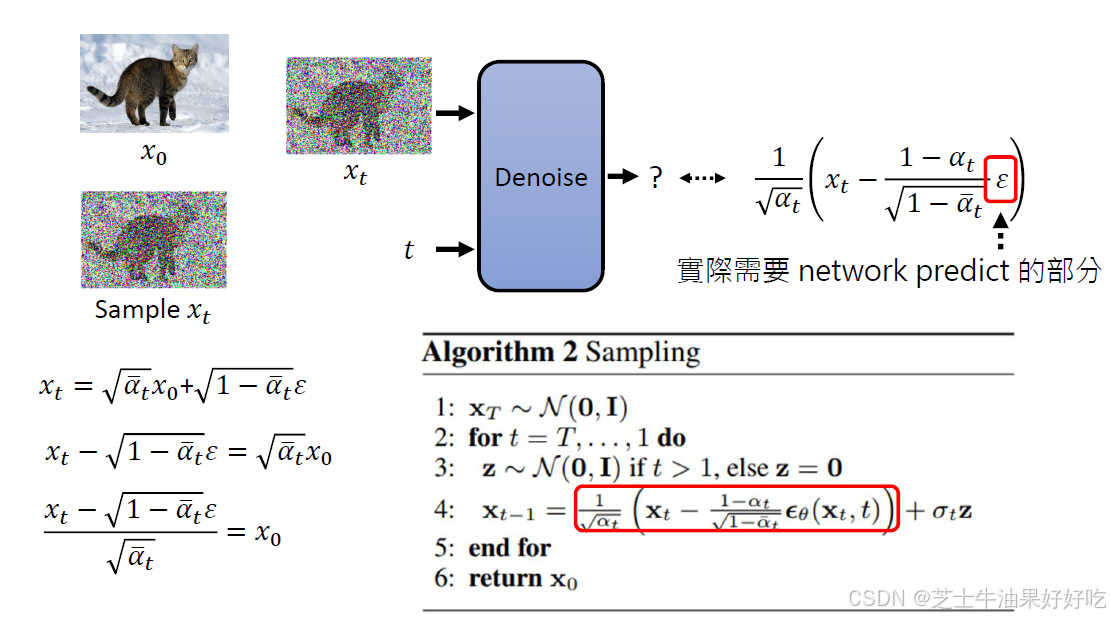
(一)反向过程
可训练的反向去噪扩散过程 :训练一个神经网络,从纯噪音开始逐渐去噪,直到得到一个真实图像。
:训练一个神经网络,从纯噪音开始逐渐去噪,直到得到一个真实图像。
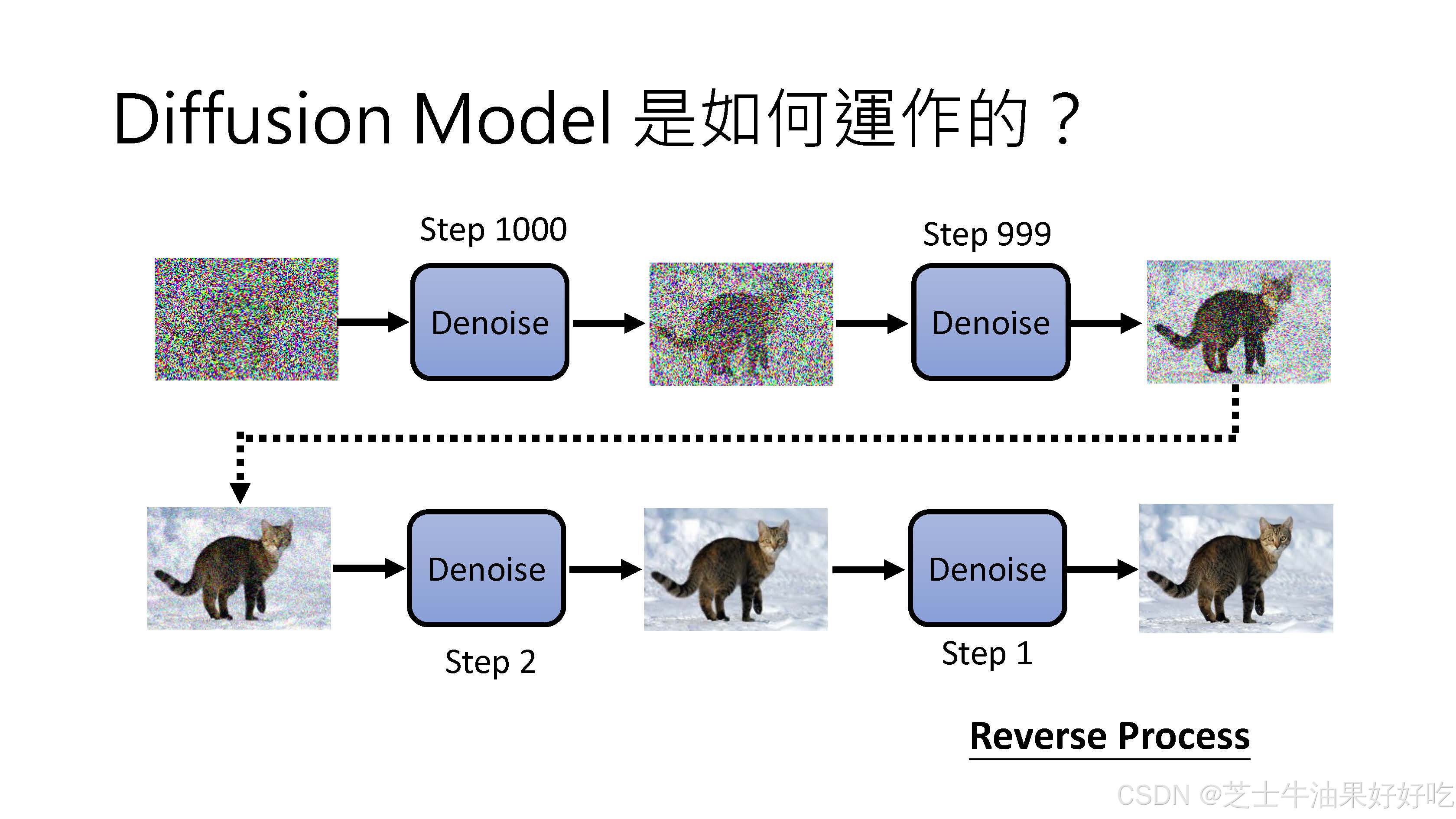

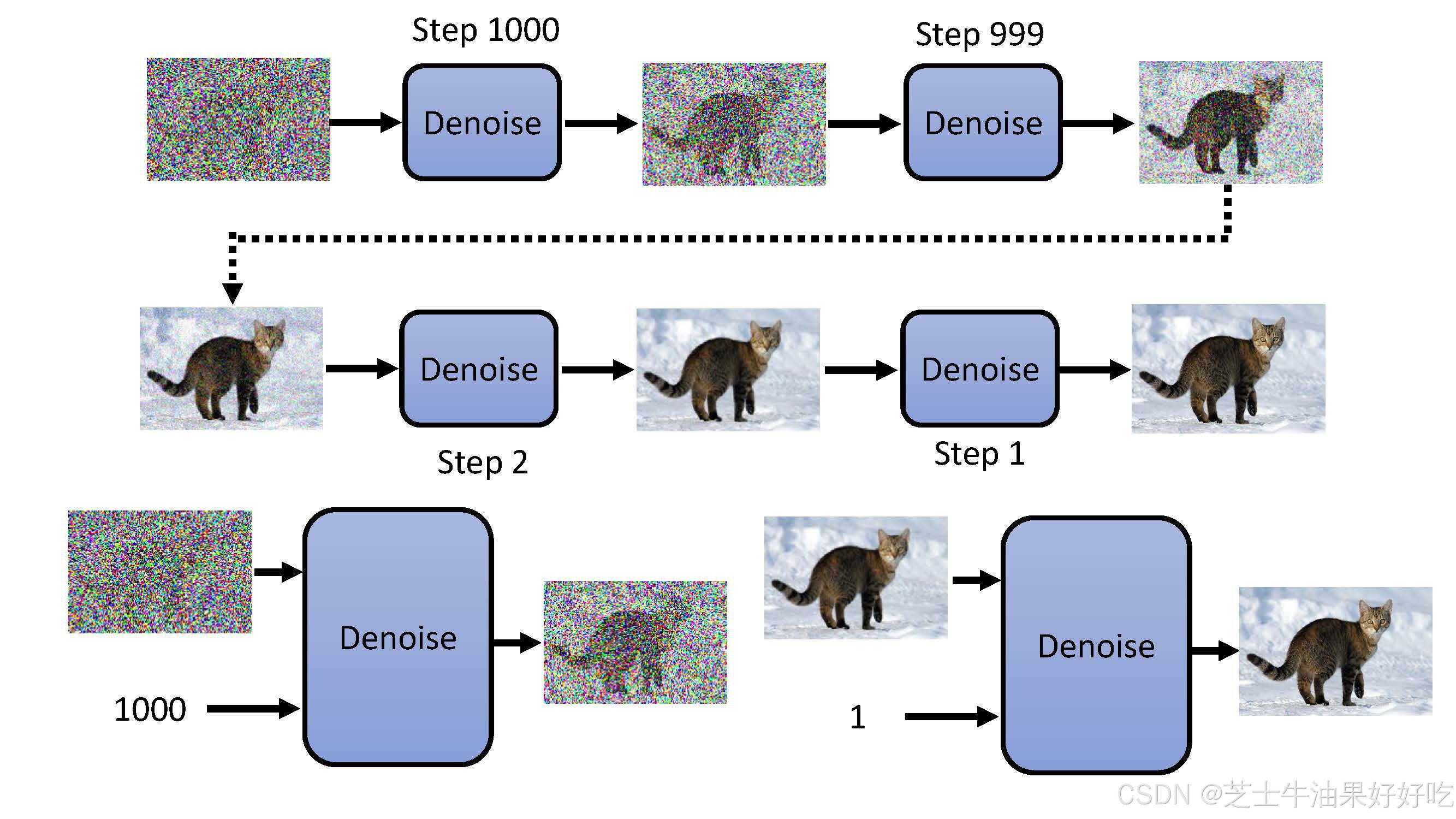
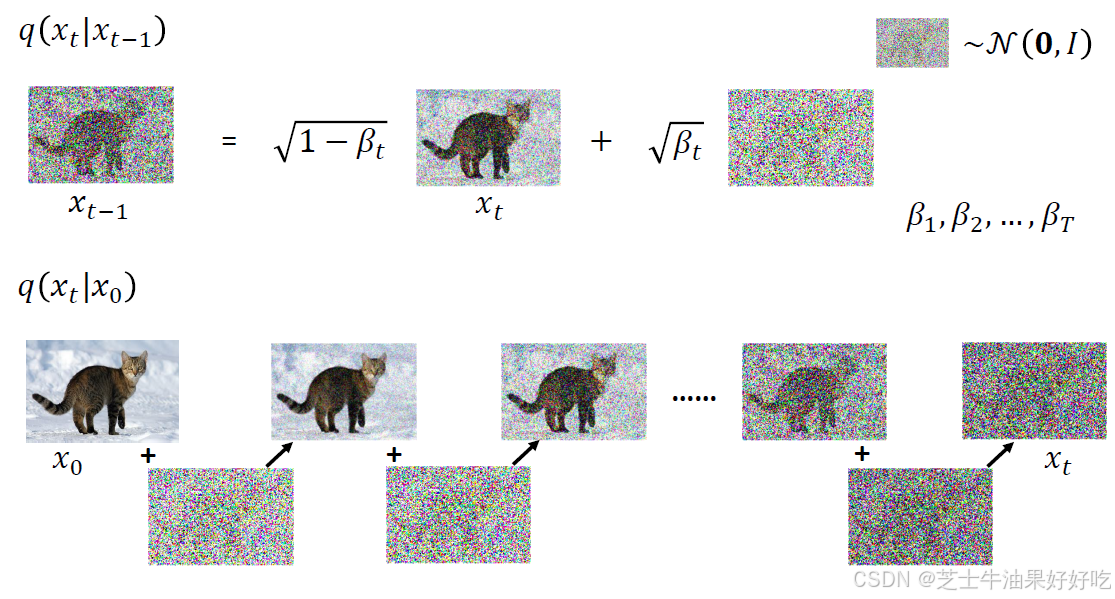
(二)前向过程
固定的(或预设的)前向扩散过程q:该过程会逐渐将高斯噪声添加到图像中,直到最终得到纯噪声。尺寸和X0图像一致。前向与后向的步数由下标 t定义,并且有预先定义好的总步数 T(DDPM原文中为1000)。t=0 时为从数据集中采样得到的一张真实图片, t=T 时近似为一张纯粹的噪声。

(三)文生图运作过程
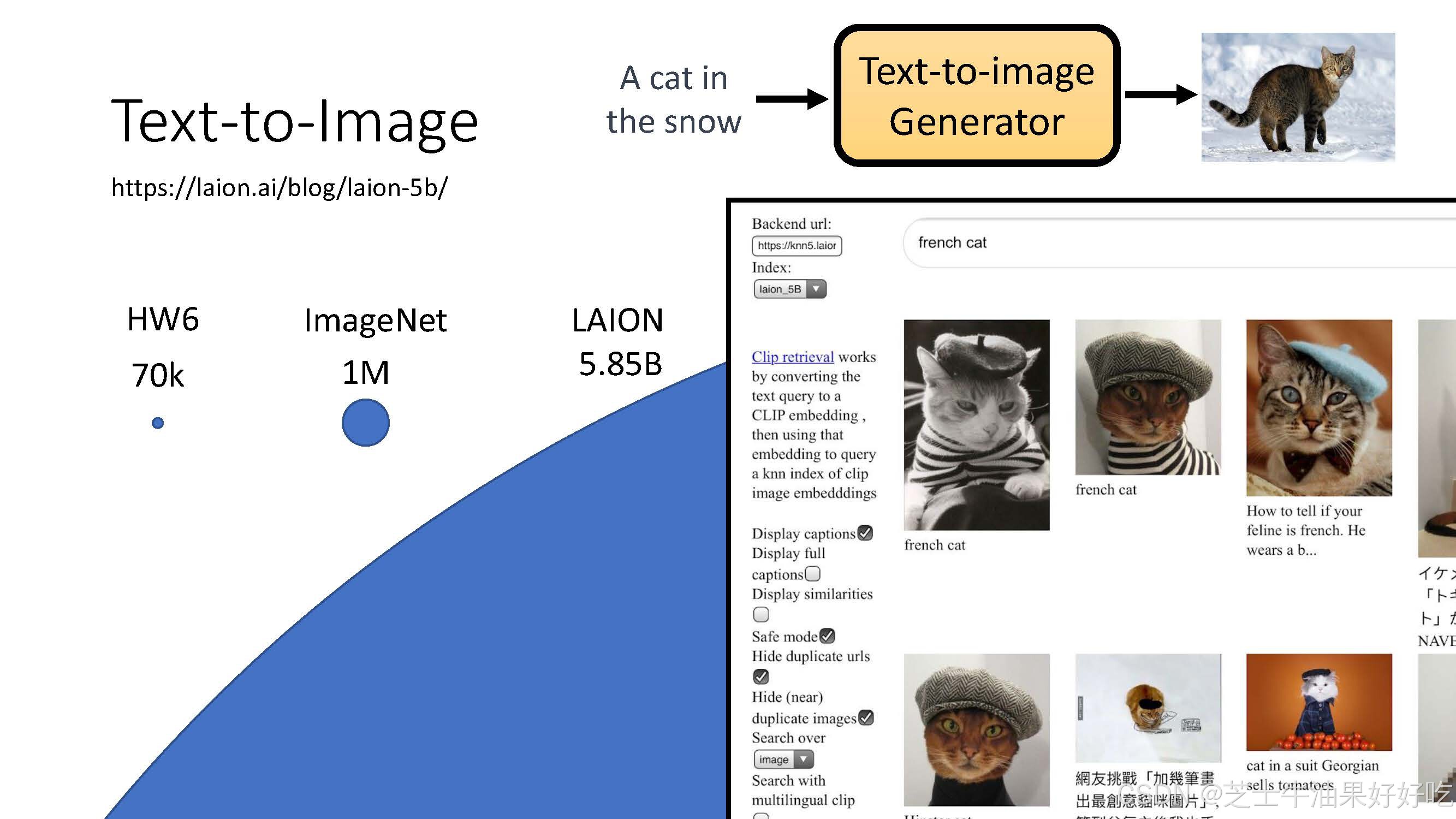
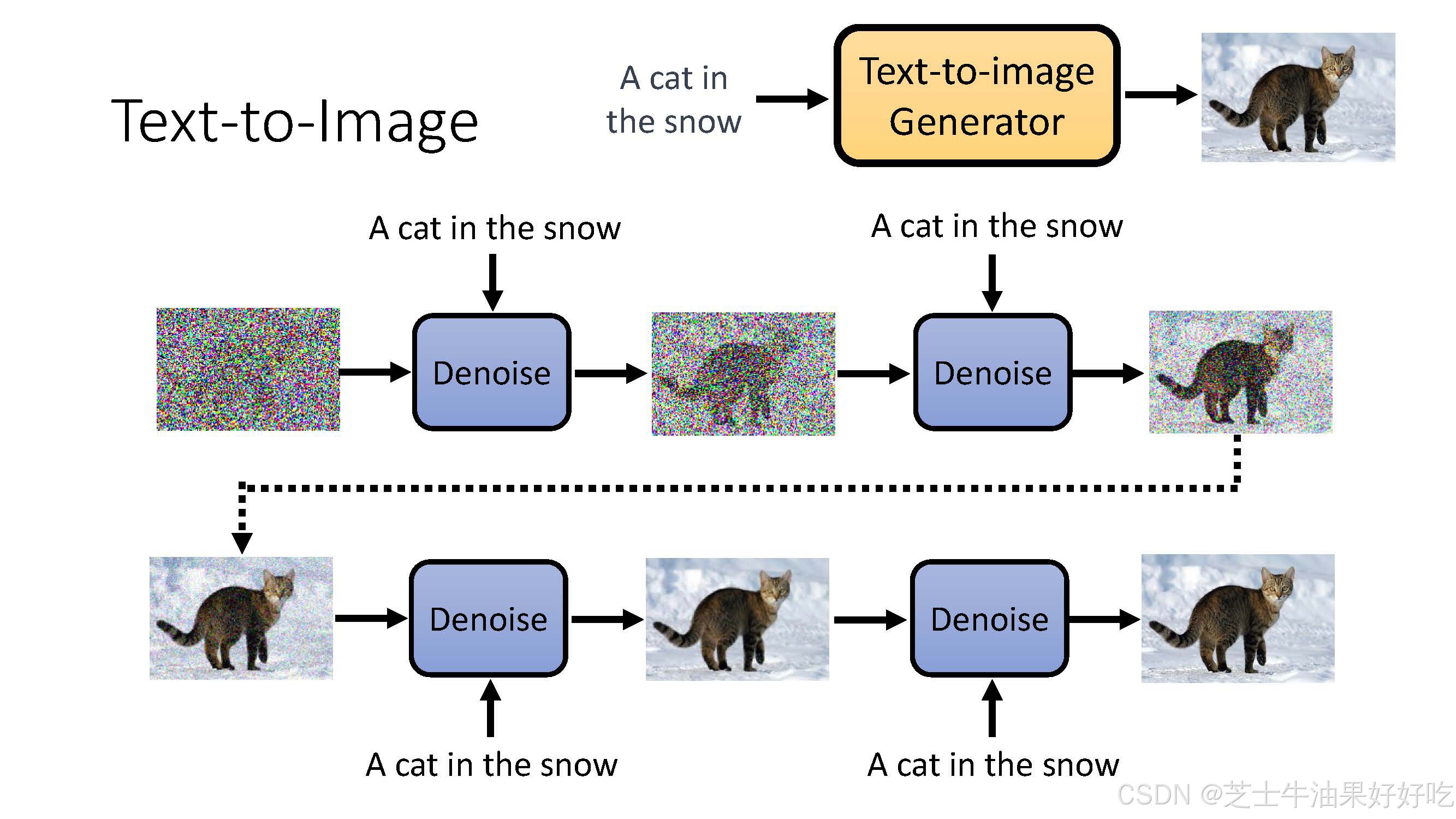
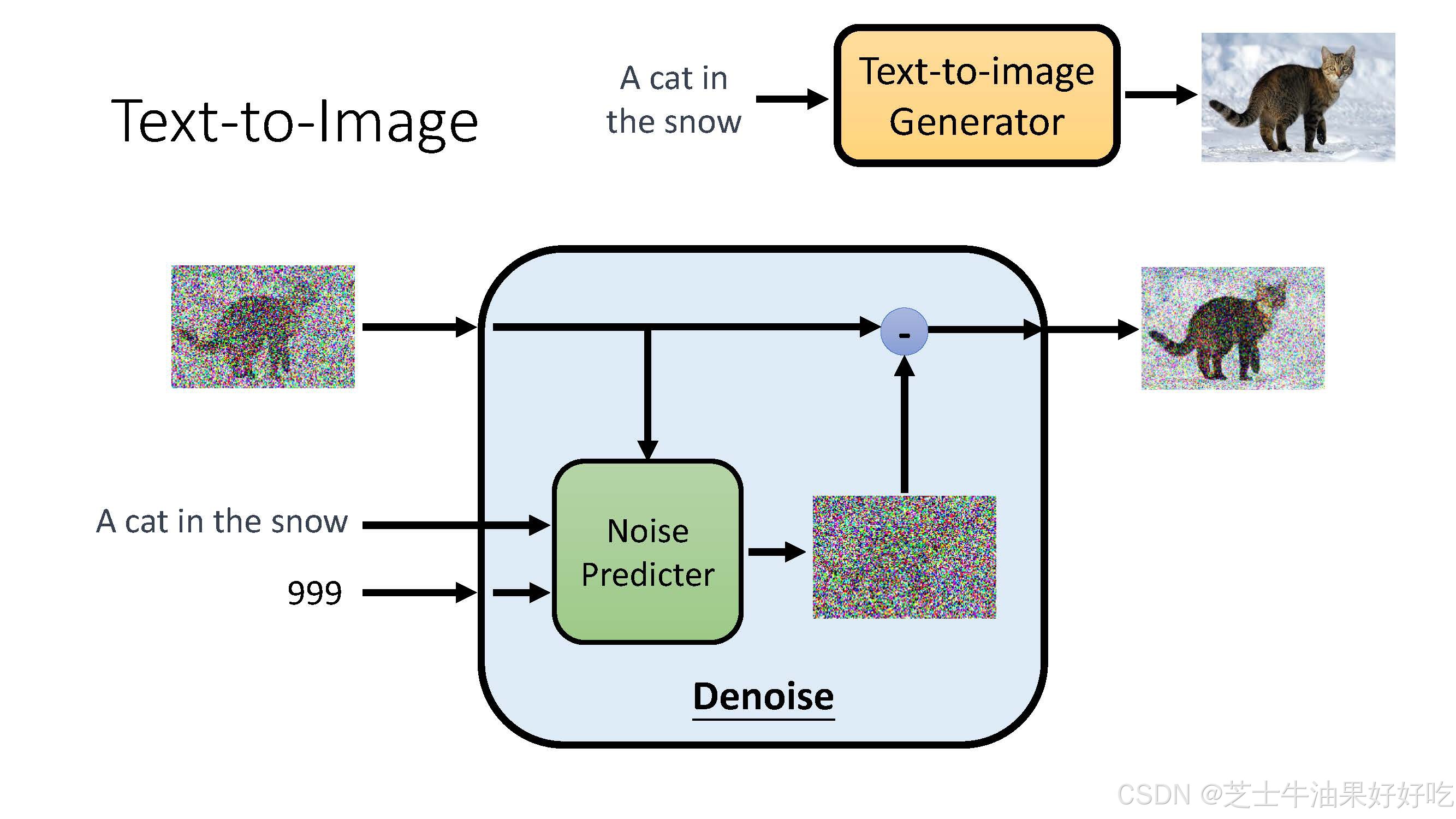
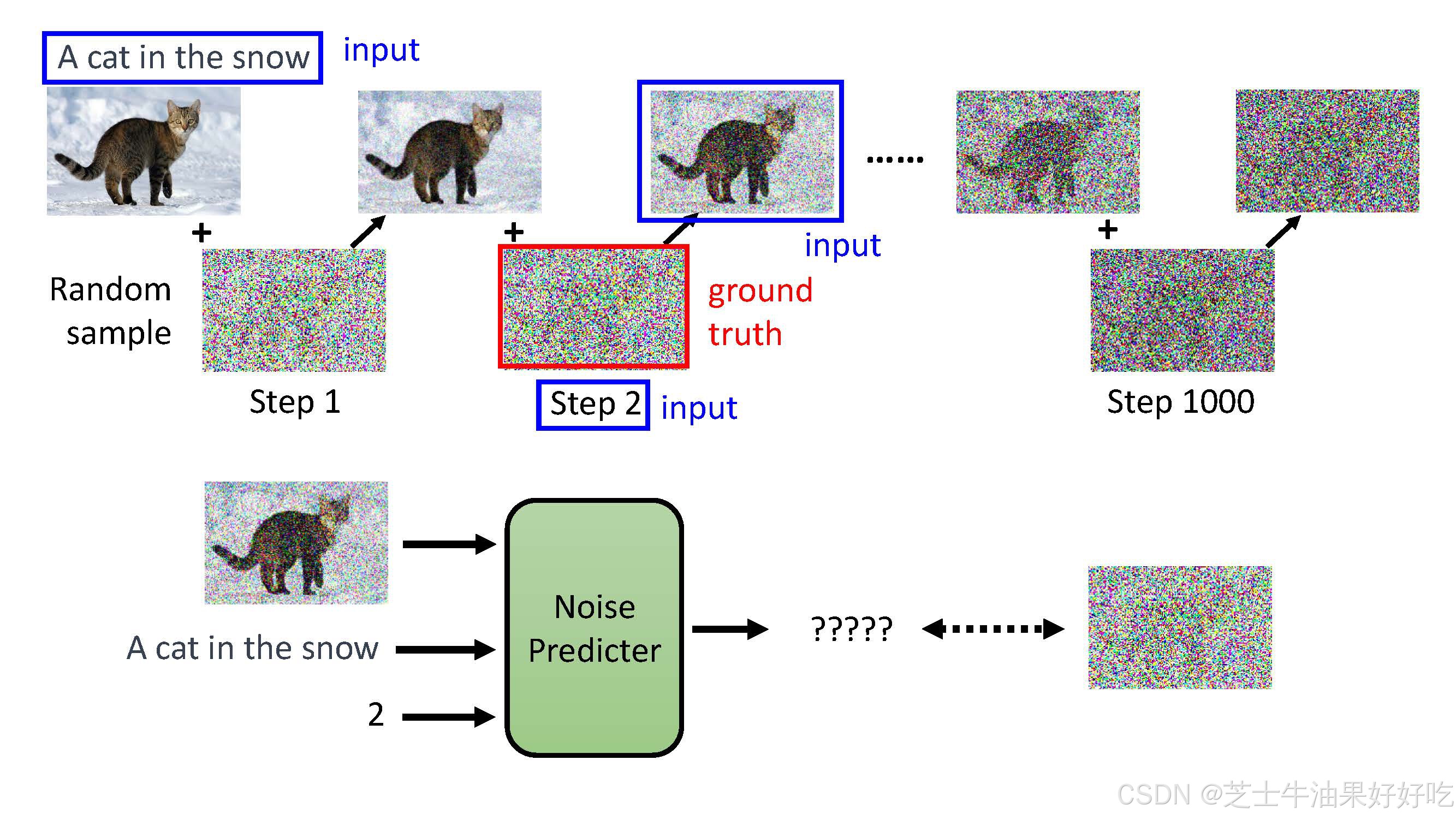
(四)直观理解
为了看懂扩散模型查了很多资料,但是要么就是大量的数学公式,一行行公式推完了还是不知道它想干啥。要么就是高视角,上来就和能量模型,VAE放一块儿对比说共同点和不同点,看完还是云里雾里。然而事实上下面几句话就能把扩散模型说明白了
扩散模型的目的是什么?
学习从纯噪声生成图片的方法
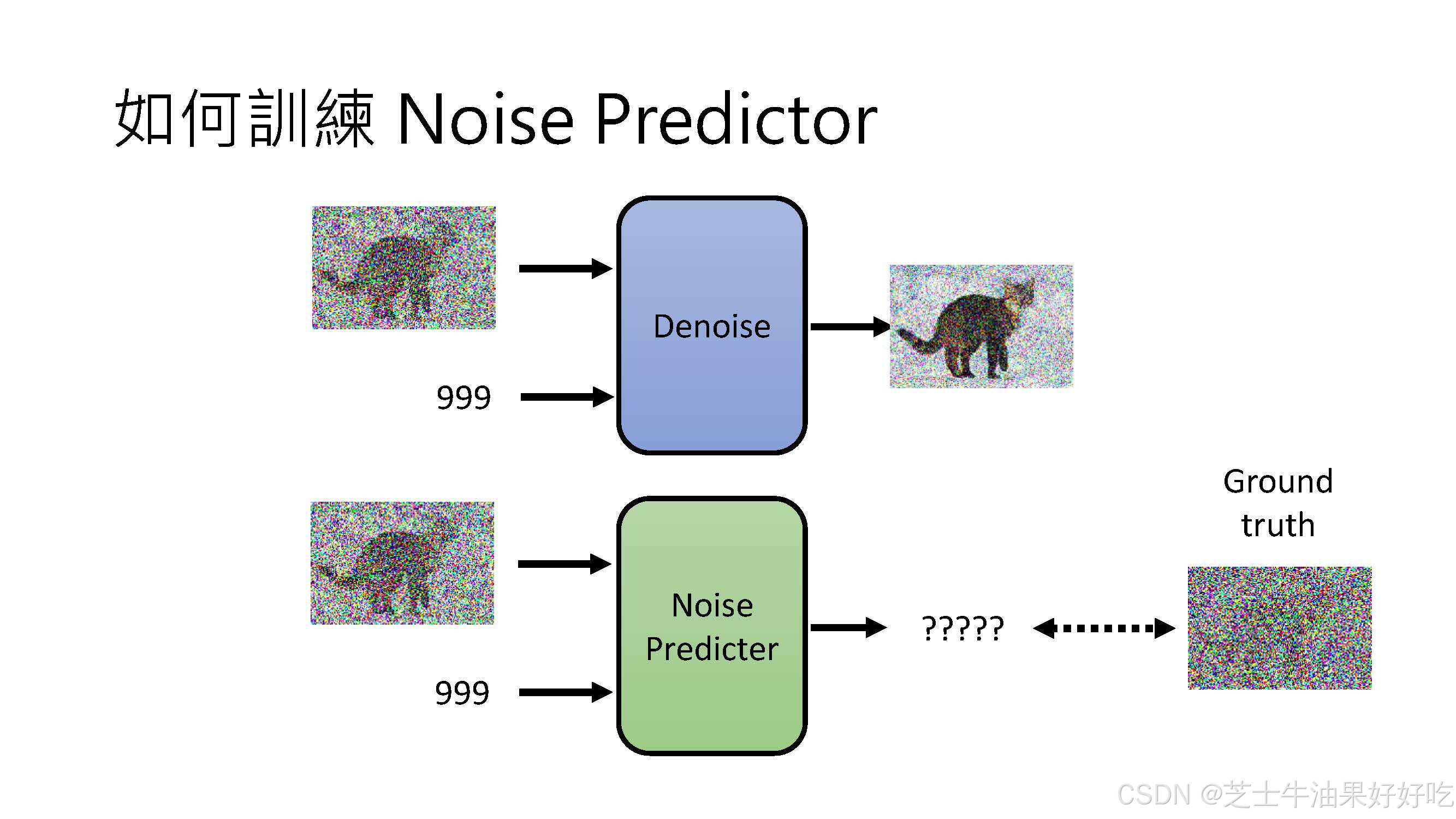
扩散模型是怎么做的?
训练一个U-Net,接受一系列加了噪声的图片,学习预测所加的噪声
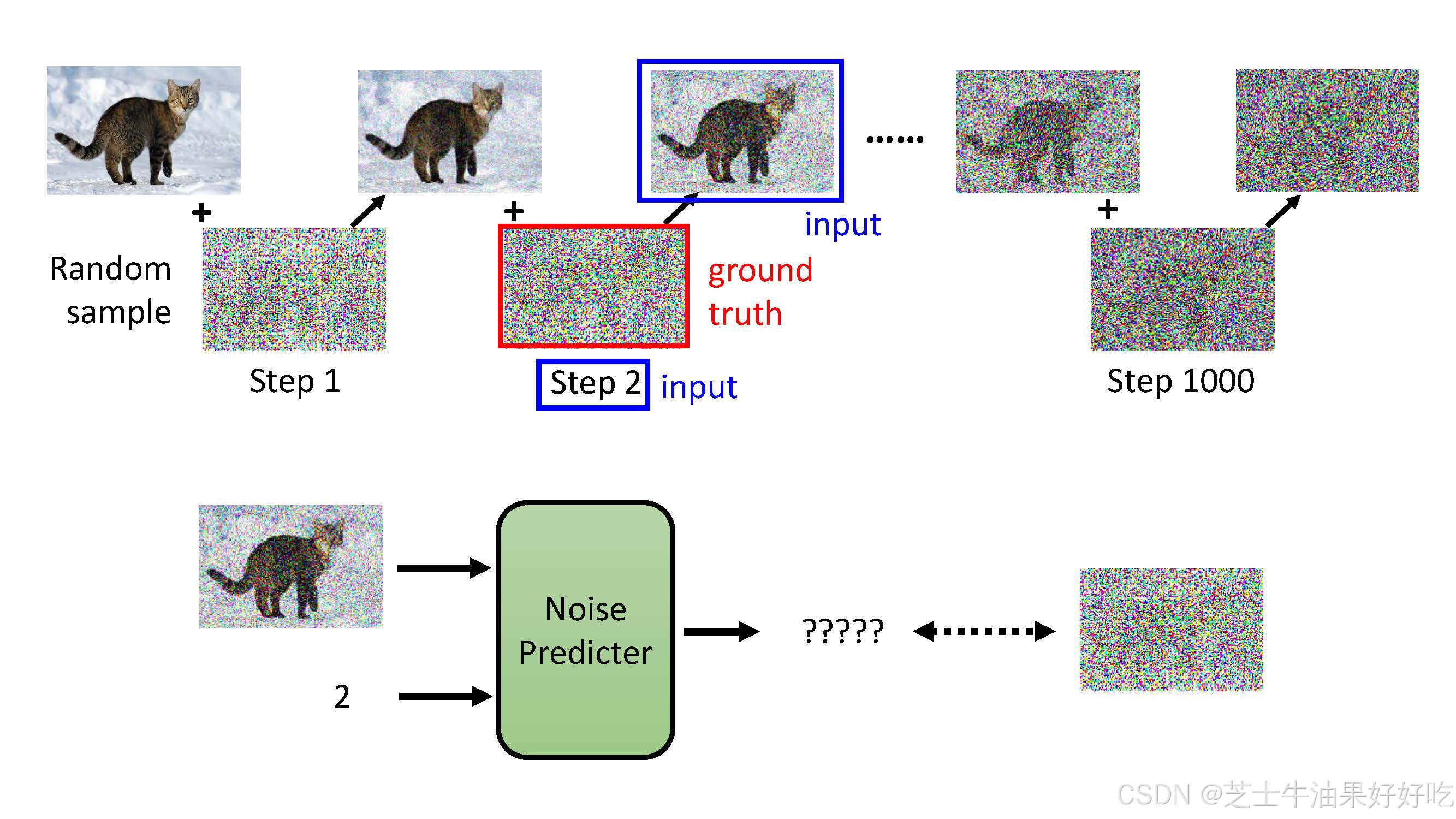
前向过程在干啥?
逐步向真实图片添加噪声最终得到一个纯噪声
对于训练集中的每张图片,都能生成一系列的噪声程度不同的加噪图片
在训练时,这些 【不同程度的噪声图片 + 生成它们所用的噪声】 是实际的训练样本
反向过程在干啥?
训练好模型后,采样、生成图片
三、理论(与VAE进行比较)

(一)前向算法的理解


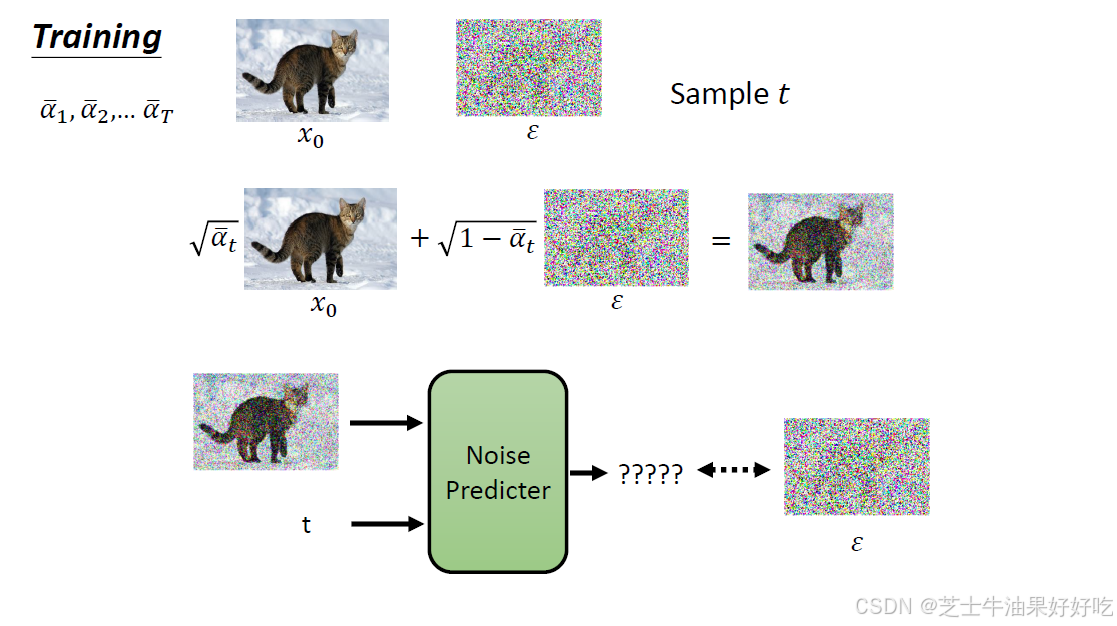
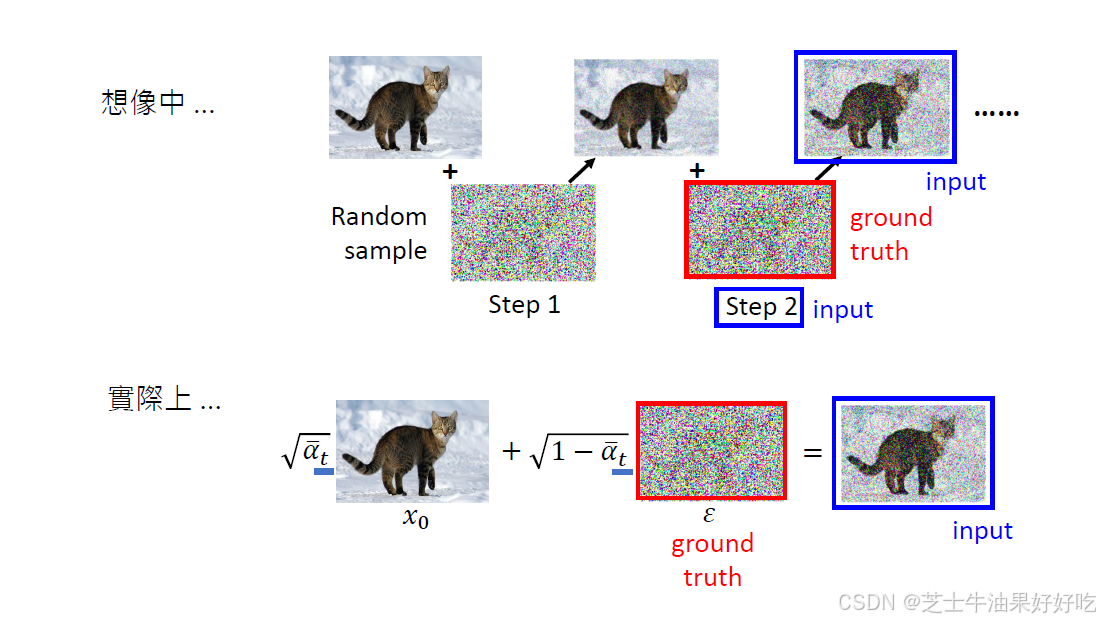
(二)反向算法的理解
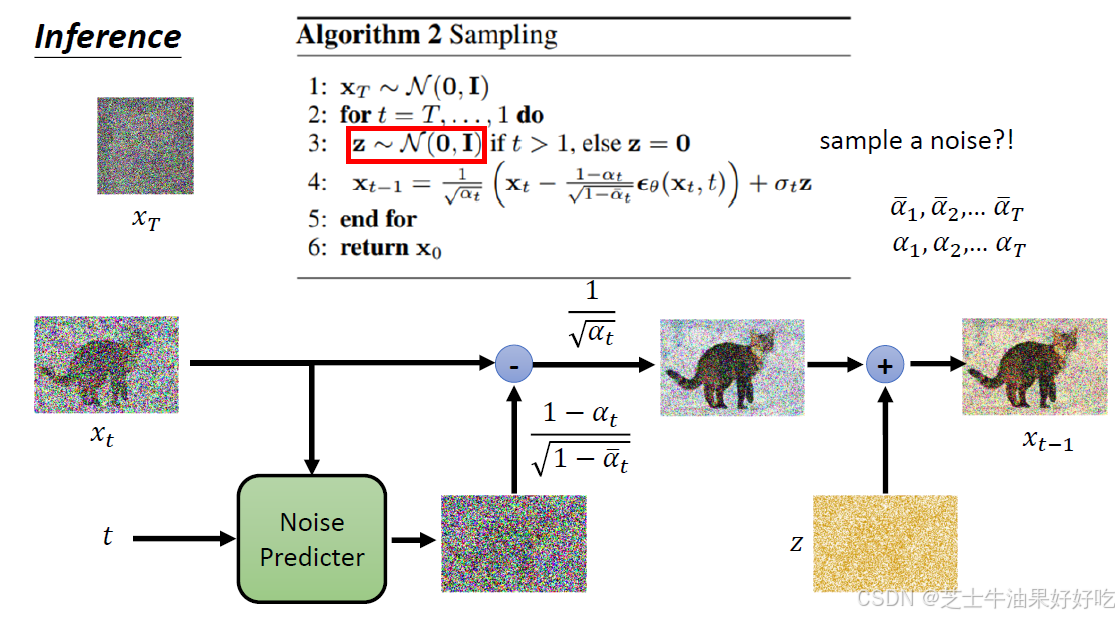
(三)VAE最大似然和变分下界(Evidence Lower Bound,ELBO)
共同目标是找到两个分布,使得已知分布和真实分布一致。
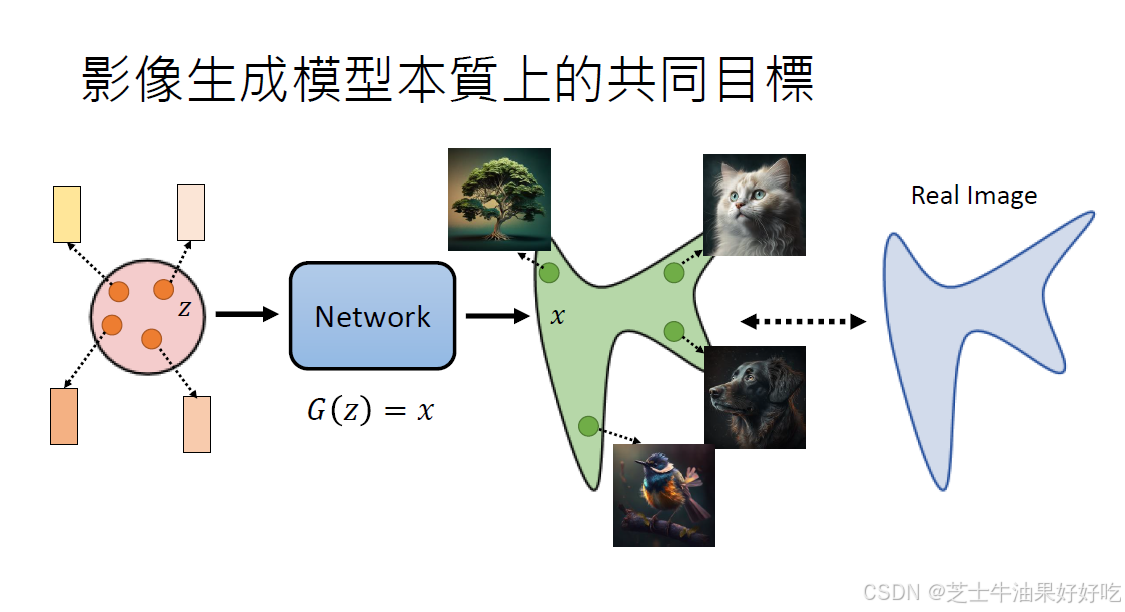
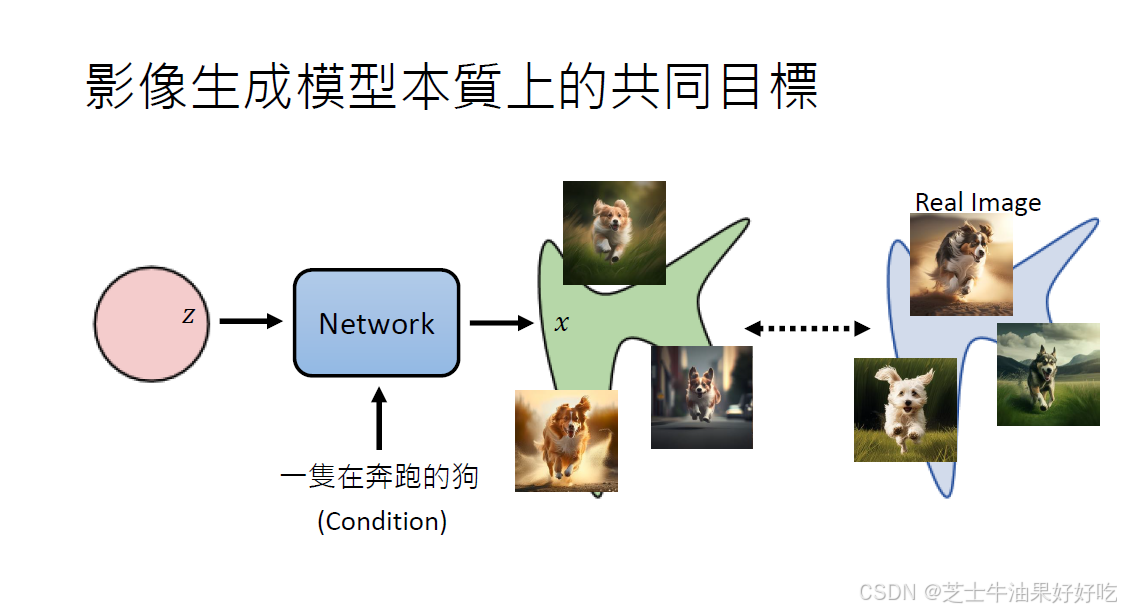
最大似然,
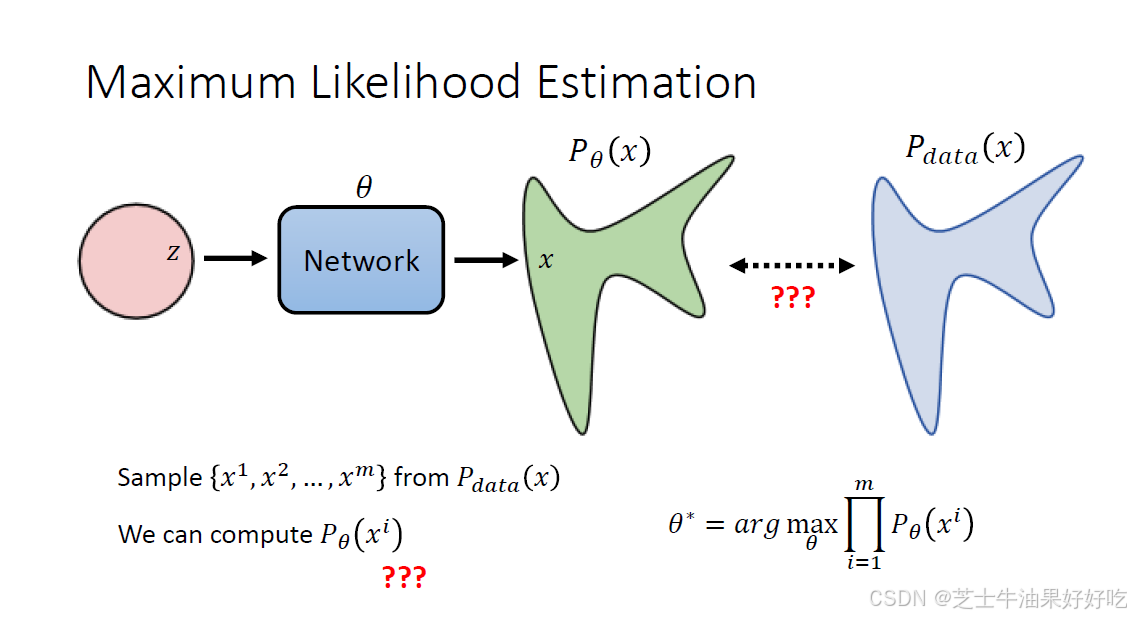
最大化pθ等于最小化KL散度

如果![]() 有一点不一样,则为0,计算上会有困难,改用高斯分布
有一点不一样,则为0,计算上会有困难,改用高斯分布
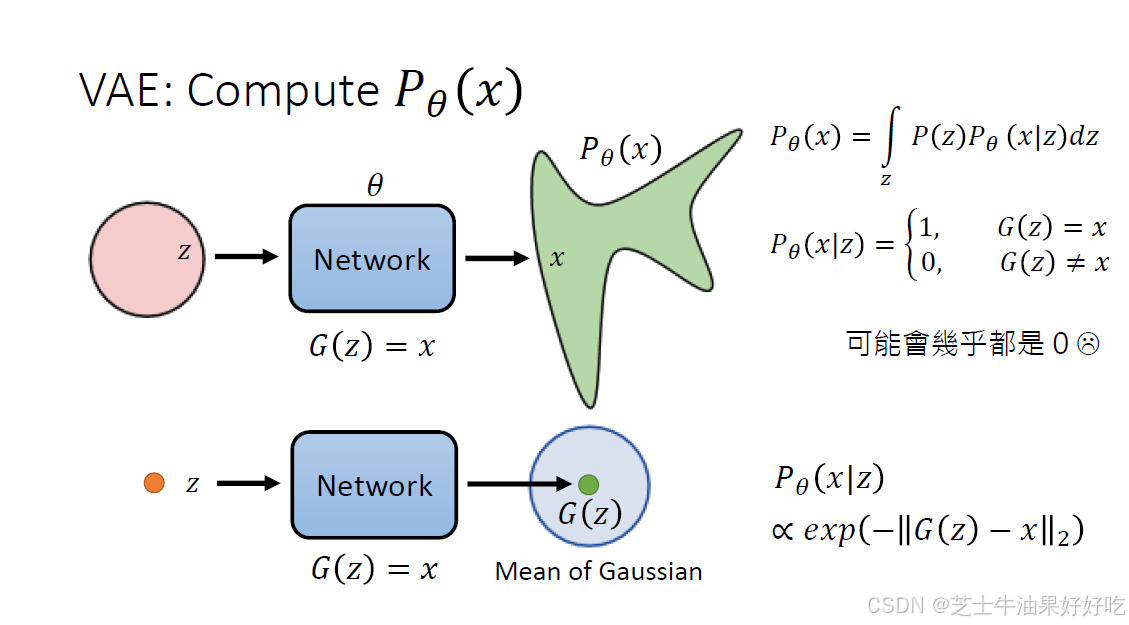

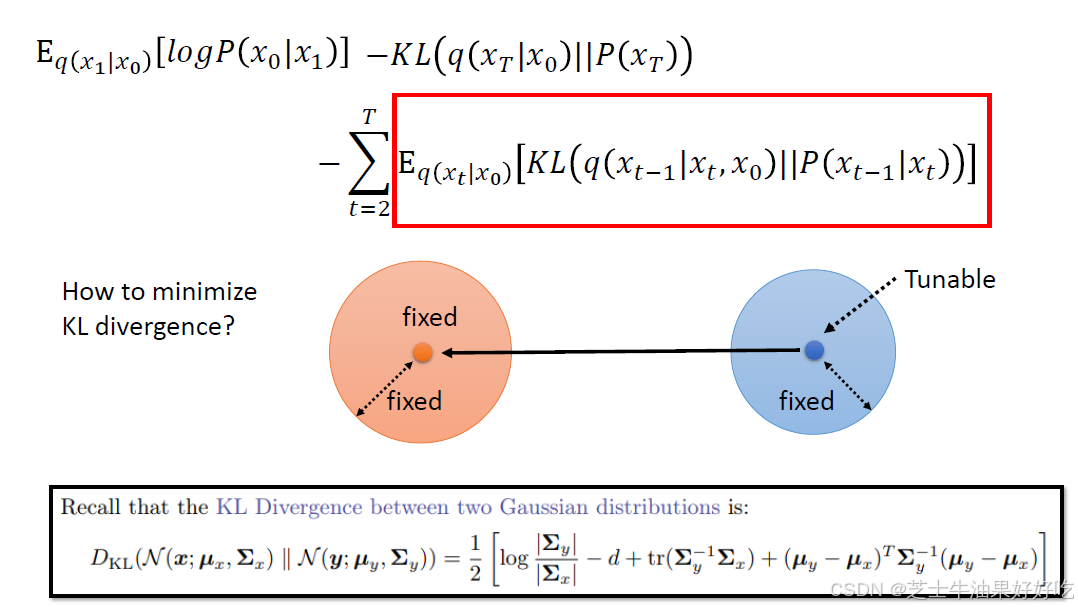
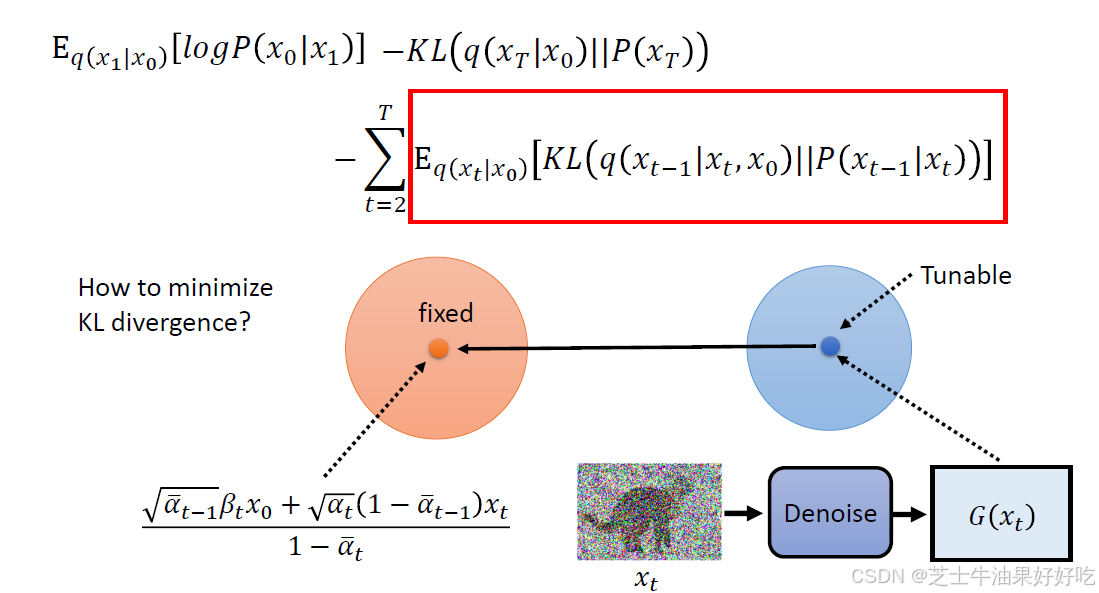
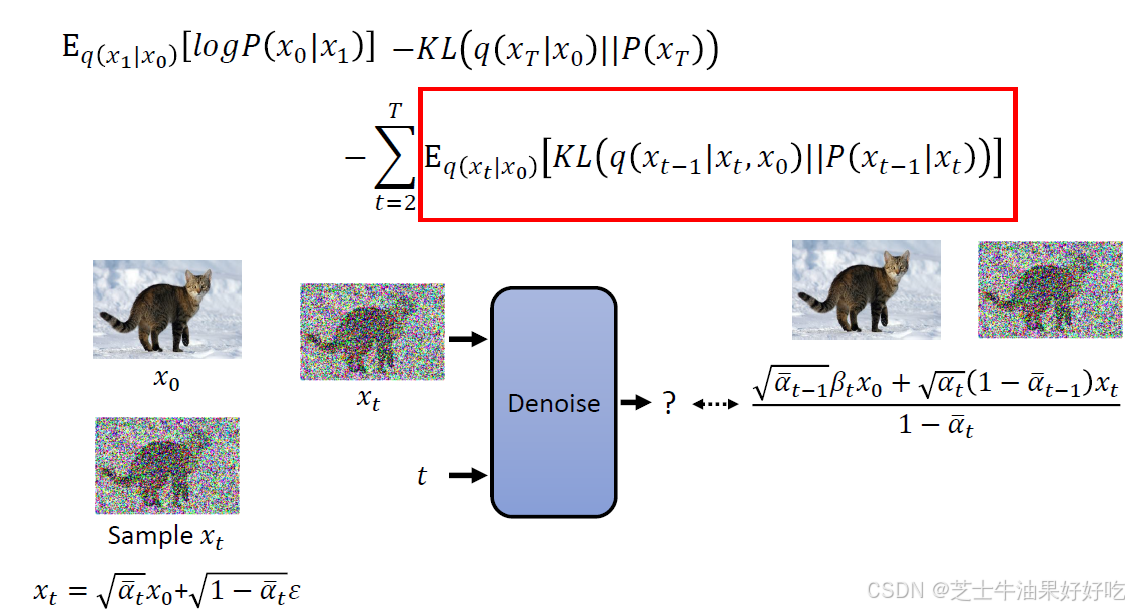
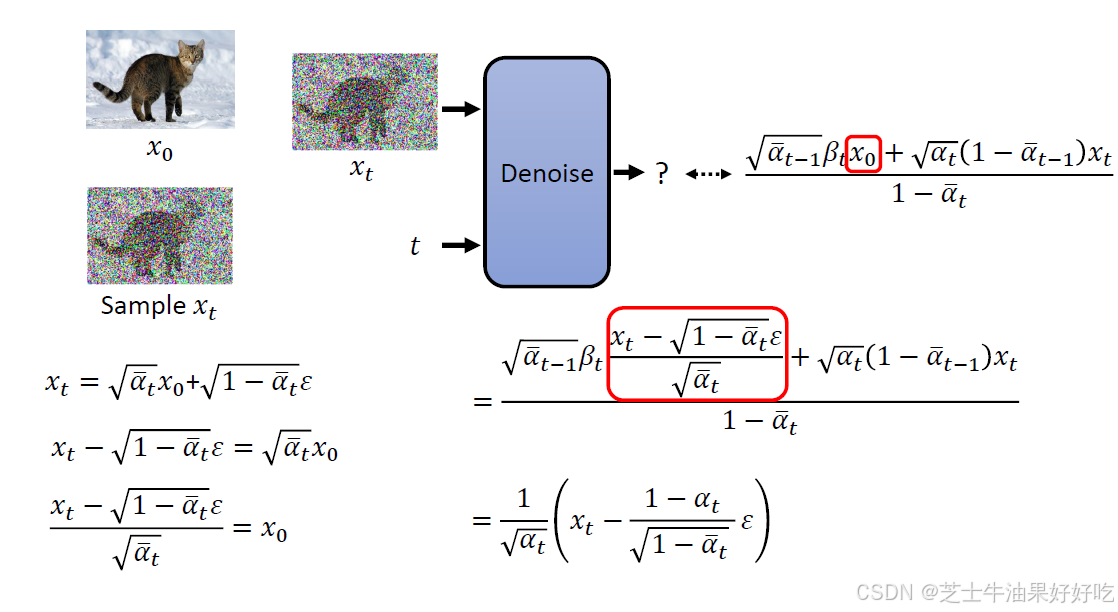
(四)DDPM最大似然和变分下界(Evidence Lower Bound,ELBO)
下面来对应理解一下diffusion中的𝑃𝜃𝑥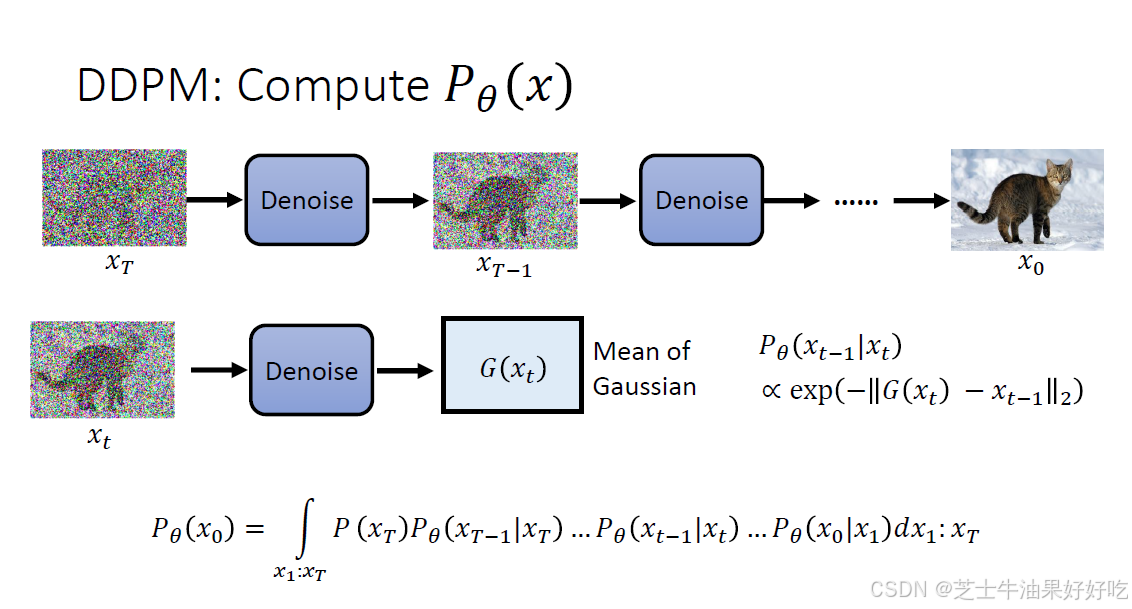

先计算三个q




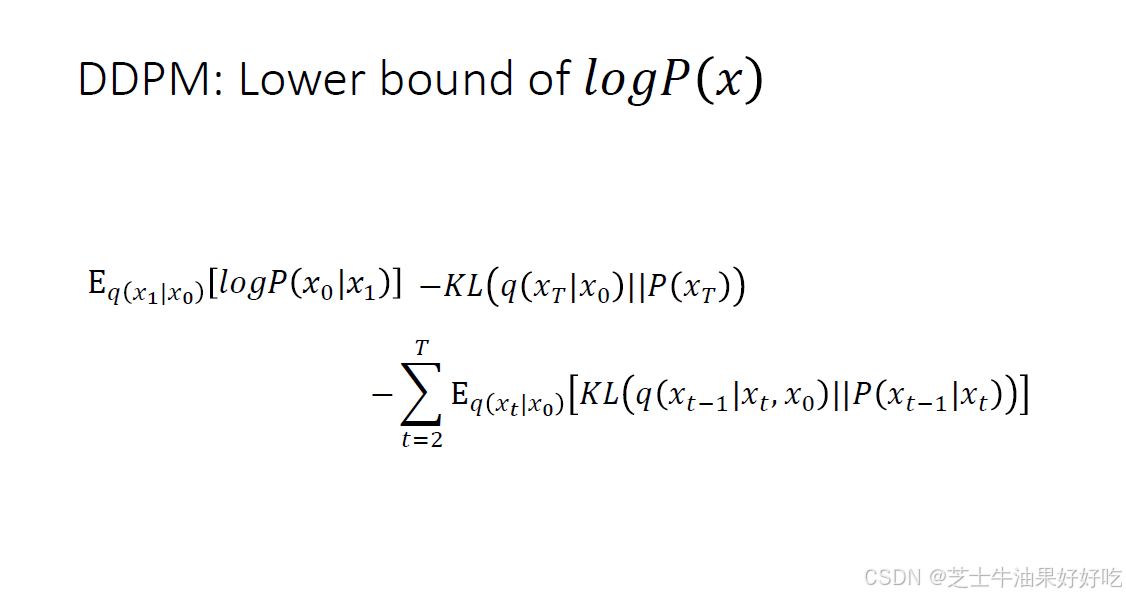



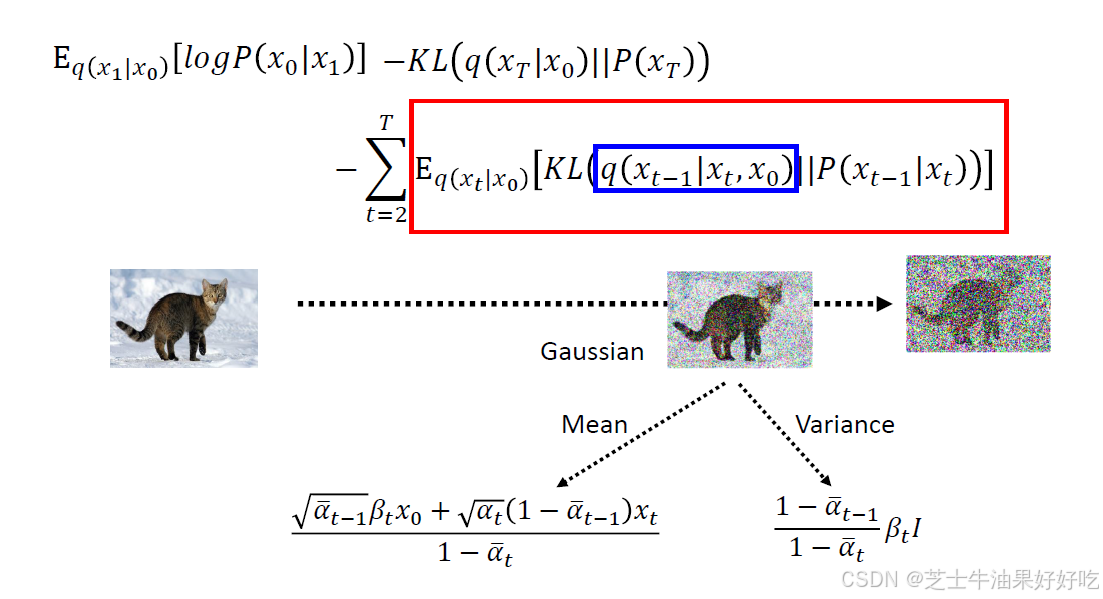

四、代码实现
(一)反卷积
(二)SinusoidalPositionEmbeddings

(三)基础类
①. Block 类
这是一个基础的神经网络块,包含以下组件:
- 投影层(
proj):一个二维卷积层(nn.Conv2d),用于将输入特征映射到输出特征。 - 归一化层(
norm):一个分组归一化层(nn.GroupNorm),用于对特征进行归一化处理。 - 激活函数(
act):一个SiLU激活函数(nn.SiLU),用于引入非线性。
forward 方法定义了数据通过这个块的流程:
- 输入
x首先通过投影层。 - 然后通过归一化层。
- 如果提供了
scale_shift参数(包含scale和shift),则对归一化后的特征进行缩放和平移。 - 最后通过激活函数。
②. ResnetBlock 类
这是一个基于残差网络(ResNet)思想的块,包含以下组件:
- MLP(多层感知机):如果提供了
time_emb_dim,则包含一个线性层,用于处理时间嵌入。 - 两个
Block实例:block1和block2,用于特征的转换。 - 残差连接(
res_conv):如果输入和输出维度不同,则是一个一维卷积层,否则是恒等映射。
forward 方法定义了数据通过这个块的流程:
- 输入
x首先通过block1。 - 如果提供了时间嵌入
time_emb,则通过 MLP 处理后加到block1的输出上。 - 然后通过
block2。 - 最后,将
block2的输出通过残差连接加到输入x上。
③. ConvNextBlock 类
这是一个类似于 ConvNeXt 架构的块,包含以下组件:
- MLP:如果提供了
time_emb_dim,则包含一个线性层,用于处理时间嵌入。 - 深度可分离卷积(
ds_conv):用于空间维度的下采样。 - 网络序列(
net):包含归一化层、卷积层和激活函数,用于特征的转换。 - 残差连接(
res_conv):如果输入和输出维度不同,则是一个一维卷积层,否则是恒等映射。
forward 方法定义了数据通过这个块的流程:
- 输入
x首先通过深度可分离卷积ds_conv。 - 如果提供了时间嵌入
time_emb,则通过 MLP 处理后加到ds_conv的输出上。 - 然后通过
net序列。 - 最后,将
net的输出通过残差连接加到输入x上。
④. Attention 类
这个类实现了一个多头自注意力机制,通常用于处理图像或特征图。
-
初始化 (
__init__):dim:输入特征的维度。heads:注意力头的数量。dim_head:每个注意力头的维度。scale:用于缩放点积的因子,即每个头的维度的平方根的倒数。to_qkv:一个一维卷积层,用于将输入特征映射到查询(Q)、键(K)和值(V)。to_out:一个一维卷积层,用于将注意力输出映射回原始维度。
-
前向传播 (
forward):- 输入特征图
x通过to_qkv被分割成 Q、K 和 V。 - 通过
rearrange和map函数,将 Q、K 和 V 重排并分割成多个头。 - 计算 Q 和 K 的点积,应用缩放和 softmax 得到注意力权重。
- 使用
einsum计算加权的值(V),并通过rearrange重排回原始维度。 - 最后,通过
to_out将输出映射回原始维度。
- 输入特征图
⑤. LinearAttention 类
这个类实现了一个线性注意力机制,也称为 Transformer-XL 中的相对注意力。
-
初始化 (
__init__):- 与
Attention类似,但to_out包含一个分组归一化层。
- 与
-
前向传播 (
forward):- 类似于
Attention,但计算 Q 和 K 的 softmax 权重后,直接使用einsum计算上下文(context)。 - 然后,使用上下文和 Q 计算最终的输出。
- 类似于
⑥. PreNorm 类
这个类实现了一个前规范化的模块,通常用于神经网络中的规范化和激活函数之前。
-
初始化 (
__init__):dim:输入特征的维度。fn:一个神经网络函数,通常是激活函数或注意力机制。norm:一个分组归一化层。
-
前向传播 (
forward):- 首先,对输入特征图
x应用归一化。 - 然后,将归一化后的特征图传递给
fn.
- 首先,对输入特征图
(四)操作代码



import math
from inspect import isfunction
from functools import partial
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from einops import rearrange, reduce
from einops.layers.torch import Rearrange
import torch
from torch import nn, einsum
import torch.nn.functional as F
def exists(x):
return x is not None
def default(val, d):
if exists(val):
return val
return d() if isfunction(d) else d
def num_to_groups(num, divisor):
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
def Upsample(dim, dim_out=None):
return nn.Sequential(
nn.Upsample(scale_factor=2, mode="nearest"),
nn.Conv2d(dim, default(dim_out, dim), 3, padding=1),
)
def Downsample(dim, dim_out=None):
# No More Strided Convolutions or Pooling
return nn.Sequential(
Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2),
nn.Conv2d(dim * 4, default(dim_out, dim), 1),
)
class SinusoidalPositionEmbeddings(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
half_dim = self.dim // 2
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = time[:, None] * embeddings[None, :]
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
class WeightStandardizedConv2d(nn.Conv2d):
"""
https://arxiv.org/abs/1903.10520
weight standardization purportedly works synergistically with group normalization
"""
def forward(self, x):
eps = 1e-5 if x.dtype == torch.float32 else 1e-3
weight = self.weight
mean = reduce(weight, "o ... -> o 1 1 1", "mean")
var = reduce(weight, "o ... -> o 1 1 1", partial(torch.var, unbiased=False))
normalized_weight = (weight - mean) * (var + eps).rsqrt()
return F.conv2d(
x,
normalized_weight,
self.bias,
self.stride,
self.padding,
self.dilation,
self.groups,
)
class Block(nn.Module):
def __init__(self, dim, dim_out, groups=8):
super().__init__()
self.proj = WeightStandardizedConv2d(dim, dim_out, 3, padding=1)
self.norm = nn.GroupNorm(groups, dim_out)
self.act = nn.SiLU()
def forward(self, x, scale_shift=None):
x = self.proj(x)
x = self.norm(x)
if exists(scale_shift):
scale, shift = scale_shift
x = x * (scale + 1) + shift
x = self.act(x)
return x
class ResnetBlock(nn.Module):
"""https://arxiv.org/abs/1512.03385"""
def __init__(self, dim, dim_out, *, time_emb_dim=None, groups=8):
super().__init__()
self.mlp = (
nn.Sequential(nn.SiLU(), nn.Linear(time_emb_dim, dim_out * 2))
if exists(time_emb_dim)
else None
)
self.block1 = Block(dim, dim_out, groups=groups)
self.block2 = Block(dim_out, dim_out, groups=groups)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb=None):
scale_shift = None
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
time_emb = rearrange(time_emb, "b c -> b c 1 1")
scale_shift = time_emb.chunk(2, dim=1)
h = self.block1(x, scale_shift=scale_shift)
h = self.block2(h)
return h + self.res_conv(x)
class Attention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head**-0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim=1)
q, k, v = map(
lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
)
q = q * self.scale
sim = einsum("b h d i, b h d j -> b h i j", q, k)
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
attn = sim.softmax(dim=-1)
out = einsum("b h i j, b h d j -> b h i d", attn, v)
out = rearrange(out, "b h (x y) d -> b (h d) x y", x=h, y=w)
return self.to_out(out)
class LinearAttention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head**-0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = nn.Sequential(nn.Conv2d(hidden_dim, dim, 1),
nn.GroupNorm(1, dim))
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim=1)
q, k, v = map(
lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
)
q = q.softmax(dim=-2)
k = k.softmax(dim=-1)
q = q * self.scale
context = torch.einsum("b h d n, b h e n -> b h d e", k, v)
out = torch.einsum("b h d e, b h d n -> b h e n", context, q)
out = rearrange(out, "b h c (x y) -> b (h c) x y", h=self.heads, x=h, y=w)
return self.to_out(out)
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.GroupNorm(1, dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
class Unet(nn.Module):
def __init__(
self,
dim,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
self_condition=False,
resnet_block_groups=4,
):
super().__init__()
# determine dimensions
self.channels = channels
self.self_condition = self_condition
input_channels = channels * (2 if self_condition else 1)
init_dim = default(init_dim, dim)
self.init_conv = nn.Conv2d(input_channels, init_dim, 1, padding=0) # changed to 1 and 0 from 7,3
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
block_klass = partial(ResnetBlock, groups=resnet_block_groups)
# time embeddings
time_dim = dim * 4
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbeddings(dim),
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim),
)
# layers
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append(
nn.ModuleList(
[
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Downsample(dim_in, dim_out)
if not is_last
else nn.Conv2d(dim_in, dim_out, 3, padding=1),
]
)
)
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):
is_last = ind == (len(in_out) - 1)
self.ups.append(
nn.ModuleList(
[
block_klass(dim_out + dim_in, dim_out, time_emb_dim=time_dim),
block_klass(dim_out + dim_in, dim_out, time_emb_dim=time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Upsample(dim_out, dim_in)
if not is_last
else nn.Conv2d(dim_out, dim_in, 3, padding=1),
]
)
)
self.out_dim = default(out_dim, channels)
self.final_res_block = block_klass(dim * 2, dim, time_emb_dim=time_dim)
self.final_conv = nn.Conv2d(dim, self.out_dim, 1)
def forward(self, x, time, x_self_cond=None):
if self.self_condition:
x_self_cond = default(x_self_cond, lambda: torch.zeros_like(x))
x = torch.cat((x_self_cond, x), dim=1)
x = self.init_conv(x)
r = x.clone()
t = self.time_mlp(time)
h = []
for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
h.append(x)
x = block2(x, t)
x = attn(x)
h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
for block1, block2, attn, upsample in self.ups:
x = torch.cat((x, h.pop()), dim=1)
x = block1(x, t)
x = torch.cat((x, h.pop()), dim=1)
x = block2(x, t)
x = attn(x)
x = upsample(x)
x = torch.cat((x, r), dim=1)
x = self.final_res_block(x, t)
return self.final_conv(x)
def cosine_beta_schedule(timesteps, s=0.008):
"""
cosine schedule as proposed in https://arxiv.org/abs/2102.09672
"""
steps = timesteps + 1
x = torch.linspace(0, timesteps, steps)
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])
return torch.clip(betas, 0.0001, 0.9999)
def linear_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start, beta_end, timesteps)
def quadratic_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start**0.5, beta_end**0.5, timesteps) ** 2
def sigmoid_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
betas = torch.linspace(-6, 6, timesteps)
return torch.sigmoid(betas) * (beta_end - beta_start) + beta_start
timesteps = 300
# define beta schedule
betas = linear_beta_schedule(timesteps=timesteps)
# define alphas
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
# calculations for diffusion q(x_t | x_{t-1}) and others
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
def extract(a, t, x_shape):
batch_size = t.shape[0]
out = a.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw) # PIL image of shape HWC
from torchvision.transforms import Compose, ToTensor, Lambda, ToPILImage, CenterCrop, Resize
image_size = 128
transform = Compose([
Resize(image_size),
CenterCrop(image_size),
ToTensor(), # turn into torch Tensor of shape CHW, divide by 255
Lambda(lambda t: (t * 2) - 1),
])
x_start = transform(image).unsqueeze(0)
import numpy as np
reverse_transform = Compose([
Lambda(lambda t: (t + 1) / 2),
Lambda(lambda t: t.permute(1, 2, 0)), # CHW to HWC
Lambda(lambda t: t * 255.),
Lambda(lambda t: t.numpy().astype(np.uint8)),
ToPILImage(),
])
# forward diffusion (using the nice property)
def q_sample(x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x_start.shape
)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
def get_noisy_image(x_start, t):
# add noise
x_noisy = q_sample(x_start, t=t)
# turn back into PIL image
noisy_image = reverse_transform(x_noisy.squeeze())
return noisy_image
# take time step
t = torch.tensor([40])
get_noisy_image(x_start, t)
import matplotlib.pyplot as plt
# use seed for reproducability
torch.manual_seed(0)
# source: https://pytorch.org/vision/stable/auto_examples/plot_transforms.html#sphx-glr-auto-examples-plot-transforms-py
def plot(imgs, with_orig=False, row_title=None, **imshow_kwargs):
if not isinstance(imgs[0], list):
# Make a 2d grid even if there's just 1 row
imgs = [imgs]
num_rows = len(imgs)
num_cols = len(imgs[0]) + with_orig
fig, axs = plt.subplots(figsize=(200,200), nrows=num_rows, ncols=num_cols, squeeze=False)
for row_idx, row in enumerate(imgs):
row = [image] + row if with_orig else row
for col_idx, img in enumerate(row):
ax = axs[row_idx, col_idx]
ax.imshow(np.asarray(img), **imshow_kwargs)
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
if with_orig:
axs[0, 0].set(title='Original image')
axs[0, 0].title.set_size(8)
if row_title is not None:
for row_idx in range(num_rows):
axs[row_idx, 0].set(ylabel=row_title[row_idx])
plt.tight_layout()
plot([get_noisy_image(x_start, torch.tensor([t])) for t in [0, 50, 100, 150, 199]])
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):
if noise is None:
noise = torch.randn_like(x_start)
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
predicted_noise = denoise_model(x_noisy, t)
if loss_type == 'l1':
loss = F.l1_loss(noise, predicted_noise)
elif loss_type == 'l2':
loss = F.mse_loss(noise, predicted_noise)
elif loss_type == "huber":
loss = F.smooth_l1_loss(noise, predicted_noise)
else:
raise NotImplementedError()
return loss
from datasets import load_dataset
# load dataset from the hub
dataset = load_dataset("fashion_mnist")
image_size = 28
channels = 1
batch_size = 128
from torchvision import transforms
from torch.utils.data import DataLoader
# define image transformations (e.g. using torchvision)
transform = Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Lambda(lambda t: (t * 2) - 1)
])
# define function
def transforms(examples):
examples["pixel_values"] = [transform(image.convert("L")) for image in examples["image"]]
del examples["image"]
return examples
transformed_dataset = dataset.with_transform(transforms).remove_columns("label")
# create dataloader
dataloader = DataLoader(transformed_dataset["train"], batch_size=batch_size, shuffle=True)
batch = next(iter(dataloader))
print(batch.keys())
@torch.no_grad()
def p_sample(model, x, t, t_index):
betas_t = extract(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x.shape
)
sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)
# Equation 11 in the paper
# Use our model (noise predictor) to predict the mean
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
if t_index == 0:
return model_mean
else:
posterior_variance_t = extract(posterior_variance, t, x.shape)
noise = torch.randn_like(x)
# Algorithm 2 line 4:
return model_mean + torch.sqrt(posterior_variance_t) * noise
# Algorithm 2 (including returning all images)
@torch.no_grad()
def p_sample_loop(model, shape):
device = next(model.parameters()).device
b = shape[0]
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)
imgs.append(img.cpu().numpy())
return imgs
@torch.no_grad()
def sample(model, image_size, batch_size=16, channels=3):
return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
from pathlib import Path
def num_to_groups(num, divisor):
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
results_folder = Path("./results")
results_folder.mkdir(exist_ok = True)
save_and_sample_every = 1000
from torch.optim import Adam
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Unet(
dim=image_size,
channels=channels,
dim_mults=(1, 2, 4,)
)
model.to(device)
optimizer = Adam(model.parameters(), lr=1e-3)
from torchvision.utils import save_image
epochs = 6
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
batch_size = batch["pixel_values"].shape[0]
batch = batch["pixel_values"].to(device)
# Algorithm 1 line 3: sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = p_losses(model, batch, t, loss_type="huber")
if step % 100 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
# save generated images
if step != 0 and step % save_and_sample_every == 0:
milestone = step // save_and_sample_every
batches = num_to_groups(4, batch_size)
all_images_list = list(map(lambda n: sample(model, batch_size=n, channels=channels), batches))
all_images = torch.cat(all_images_list, dim=0)
all_images = (all_images + 1) * 0.5
save_image(all_images, str(results_folder / f'sample-{milestone}.png'), nrow = 6)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









