







环境:dify 14.2 docker 版本;
工具:craw4ai
模型:glm-4-flash
一、背景
Dify 中内置了知名的页面爬取工具 jina,该工具可用于爬取网页内容,并进行清洗以及转化为 markdown 格式,用于后续的大模型处理。不过,在国内的网络环境中,其使用体验不尽如人意,常常会因超时问题而导致页面内容爬取失败。
二、解决思路
采用本地化部署开源爬虫工具 craw4ai,并借助 flask 提供 api 接口服务。在 dify 中以自定义工具或者代码工具的方式读取网页链接,取代 jina,以此完成工作流中的网页爬取任务,进而增强工作流的稳定性。
三、准备工作
-
安装 flask,craw4ai 和 aiohttp 包;
pip install flask aiohttp crawl4ai -
自定义 craw4ai 接口服务,端口指定为 20009,记得开启防火墙端口:
创建文件 craw4.py:
from flask import Flask, request, jsonify import asyncio from crawl4ai import AsyncWebCrawler import aiohttp import urllib.parse app = Flask(__name__) # 设置响应头部,确保返回的JSON是UTF-8编码 app.config['JSON_AS_ASCII'] = False app.config['JSONIFY_MIMETYPE'] = 'application/json; charset=utf-8' @app.route('/fetch_content', methods=['GET']) def fetch_content(): url = request.args.get('url') if not url: return jsonify({'error': 'URL参数是必需的'}), 400 # 验证URL是否有效(简单的检查,实际应用中可能需要更复杂的验证) try: result = urllib.parse.urlparse(url) if not all([result.scheme, result.netloc]): return jsonify({'error': '无效的URL'}), 400 except ValueError: return jsonify({'error': '无效的URL'}), 400 try: loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) result = loop.run_until_complete(fetch_url_content(url)) return jsonify({'content': result}), 200 except aiohttp.ClientError as e: return jsonify({'error': '网络错误:' + str(e)}), 500 except Exception as e: return jsonify({'error': '发生错误:' + str(e)}), 500 async def fetch_url_content(url): try: async with AsyncWebCrawler(verbose=True) as crawler: result = await crawler.arun( url=url, bypass_cache=True, magic=True, word_count_threshold=10, # Minimum words per block exclude_external_links=True, # Remove external links exclude_external_images=True, # Remove external images excluded_tags=['form', 'nav'], # Remove specific HTML tags) remove_overlay_elements=True ) # 确保返回的文本是UTF-8编码 # return result.markdown.encode('utf-8').decode('utf-8') return result.markdown except Exception as e: raise Exception(f"从{url}获取内容失败:{str(e)}") if __name__ == '__main__': app.run(debug=True, host='0.0.0.0', port=20009) -
启动服务:
python craw4.py -
测试接口:可以直接用浏览器访问地址:http://你的 ip 地址:20009/fetch_content?url=爬取地址;
例如:http://192.168.3.86:20009/fetch_content?url=https://www.36kr.com/p/3018968349779203

四、Dify 工作流应用
-
我们以使用代码工具为例,介绍如何在 dify 中使用 craw4ai 接口服务;
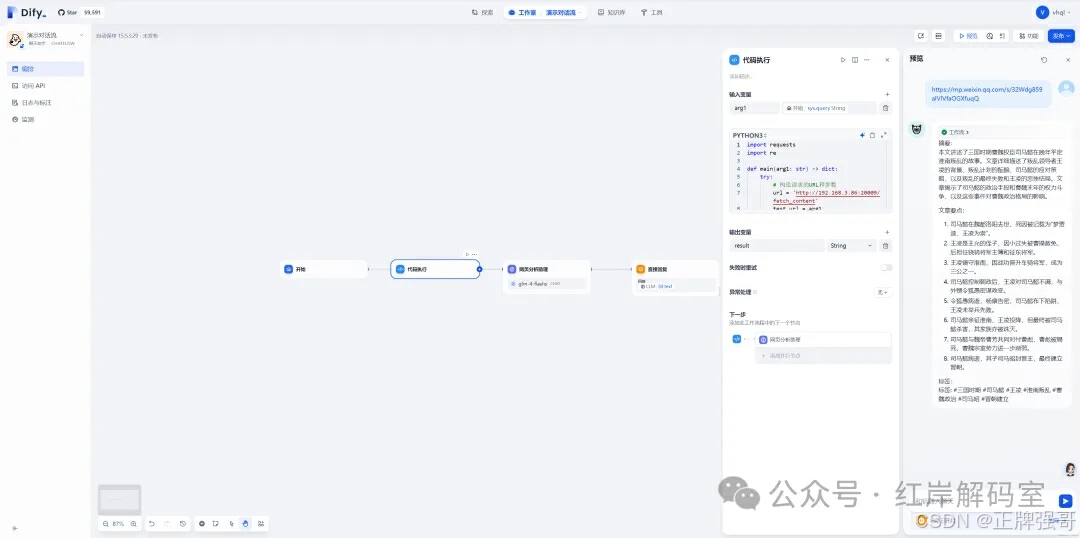
import requests import re def main(arg1: str) -> dict: try: # 构造请求的URL和参数 url = 'http://192.168.3.86:20009/fetch_content' test_url = arg1 # 发送GET请求 response = requests.get(url, params={'url': test_url}) # 检查响应状态码 if response.status_code == 200: # 请求成功,处理结果 result = response.json() # 将结果转换为字符串 result_str = str(result) # 移除字符串中的所有链接格式 result_str = re.sub(r'http\S+', '', result_str) # 检查结果长度并截断至80000字以内 if len(result_str) > 80000: result_str = result_str[:80000] + '... (截断)' return { "result": result_str } else: # 请求失败,返回错误信息 error_msg = response.json().get('error', 'Unknown error') return { "result": str(error_msg) } except requests.RequestException as e: # 网络请求异常,返回异常信息 error_msg = f"请求失败:{str(e)}" return { "result": error_msg } -
通过代码调用 craw4ai 接口服务,并在下一步中将获取到的内容传递给大模型,让大模型进行分析和输出。
五、应用效果
关注微信公众号【红岸解码室】,发送“网页助理”,获取网页助理 DSL 文件!

















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









