






Overview Today:
一些有用的策略和技巧:
1.多任务学习(multi-task learning)
2.非线性函数(Nonlinearities)
3.检查求导是否正确(gradient check)
4.Momentum,AdaGrad
语言模型(Language Model)
RNN
Multi-task learning / Weight sharing
和上一章节提到的NN类似,不过在Multi-task learning中,最后一层由一个scalar变成了softmax 分类器(训练时利用反向传播,获取错误流error):
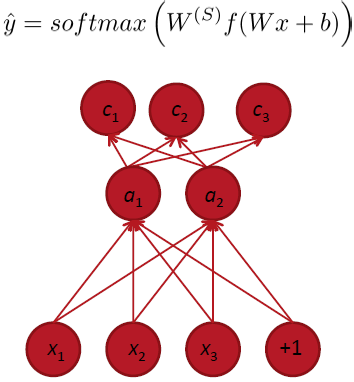
其实和训练softmax(前面讲过)差不多,只不过对于deep learning的模型来讲,输入x也经过了训练,转换成activation。
Main Idea:可以共享两个模型中,hidden layer对应的权重,和word vectors(即输入)。而只训练顶层的softmax分类器(总的cost function就是两个模型的交叉熵之和):
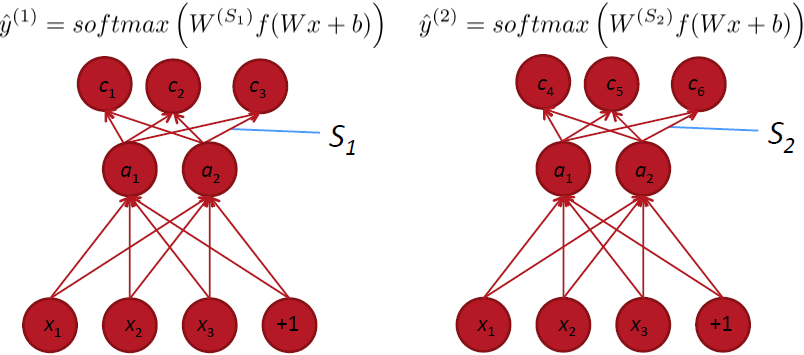
下图说明在NLP中,word vector的pre-training是一个很重要的因素:
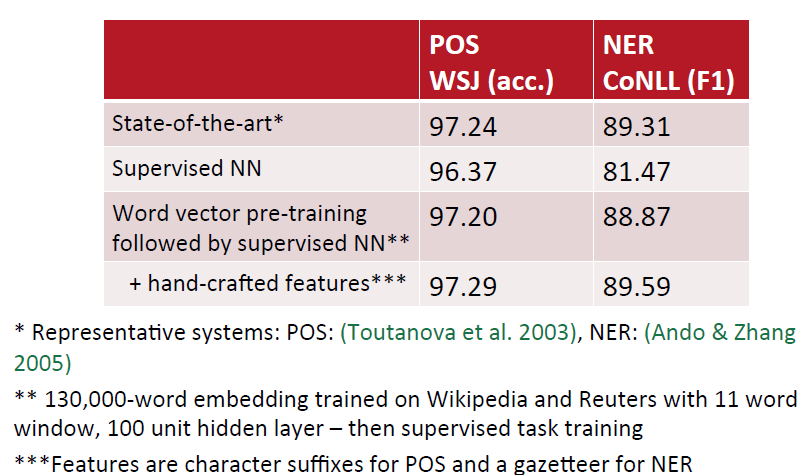
General Strategy for Successful NNets
1.选择合适的模型结构:
1)结构:单个词(single word),加窗(fixed window),bag of bags, recursive VS recurrent,CNN,基于句子还是基于文档(sentence based VS document)
2)非线性函数的选择
2.使用gradient check的方法检查是否存在bug
3.参数的初始化
4.优化的策略
5.检查模型对数据集是否过拟合(overfit):
1)如果没有,改变模型结构,让模型更“大”
2)如果有,进行regularization。
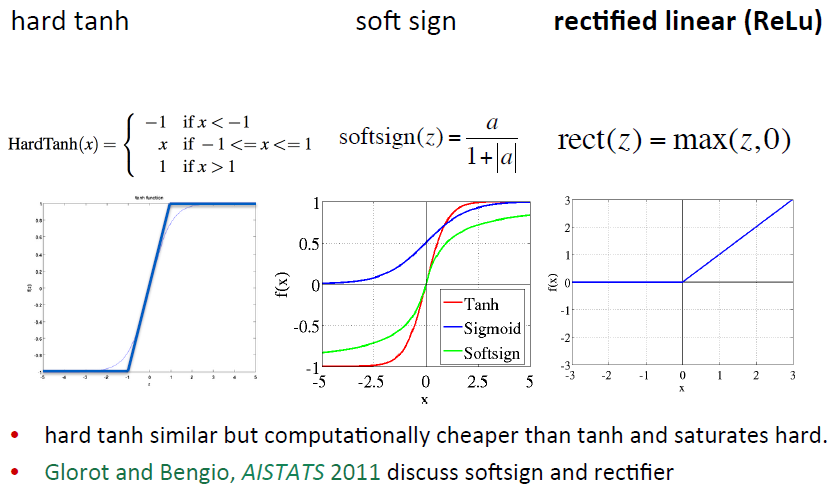
Non-‐lineariHes: What’s used
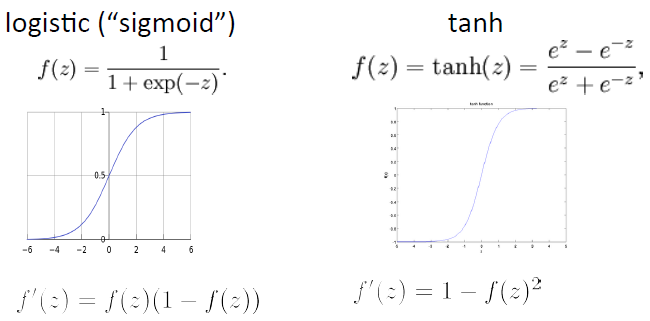
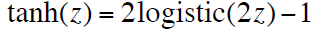
对于深度学习模型,tanh函数通常比sigmoid函数表现的要更好:
1)使用tanh函数时,模型参数的初始化值更趋向于0
2)更快达到收敛
3)求导方便:f’(z)=1-tanh2(z)
还有其他的非线性函数可供选择:
对于非线性函数的选择,还有一种maxout network:
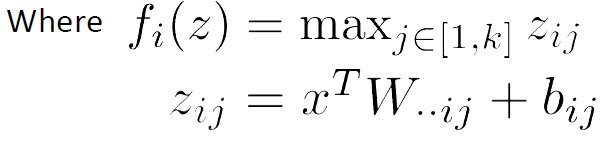
Gradient Checks
步骤:
1)完成求导
2)完成下面这个函数,通常 ϵ 为10e-4:
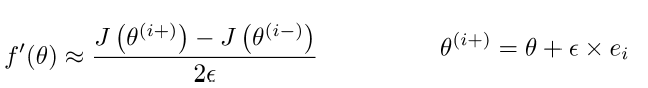
3)比较求导函数和上图函数的结果,看结果是否相近。
如果求导出错,又不知道该如何解决。那么试着先简化你的模型。可以按照以下步骤一步步的构建你的模型:
1)只有固定的输入和softmax(单个unit)分类器
2)对word vector和softmax进行反向传播求导
3)增加一个hidden层,只包括一个hidden unit
4)一个hidden layer中包括多个hidden unit
5)增加偏置bias
6)再增加一个hidden layer
7)增加两个softmax层的unit
Parameter Initialization
将hidden layer的bias初始化为0.
权重W的初始化(对于非线性函数tanh):将W的参数大小限制在(-r,r)之间。其中r的大小由下面的公式决定(fan-in为上一个hidden layer的大小,fan-out为下一hidden layer的大小):
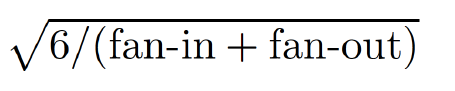
而如果使用sigmoid函数,则需要在此基础上乘以4
Stochastic Gradient Descent (SGD)
SGD每一层更新权值时,只取一个或一部分的training set:
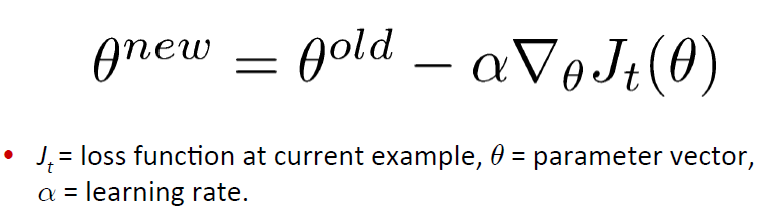
对于大的数据集,SGD通常表现的比所有的batch method要好。而对于更小一点的数据集,像 L-BFGS和CG的一些batch methods表现的要比SGD好。
Learning Rates
最简单的用法:对于所有的参数,一直都保持固定不变。
让学习率(learning rates)递减会有更好的效果:
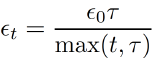
可以使用一些不用设置学习率的算法包:如L-FBGS,AdaGrad。
AdaGrad(Adaptive learning rates):学习率(learning rates)会根据不同参数发生改变。就word vector而言,使用AdaGrad的时候,对于少出现的词的word vector,其学习率会比频繁出现词的word vector更大。也就是说少出现的词的word vector会得到更大的更新率:
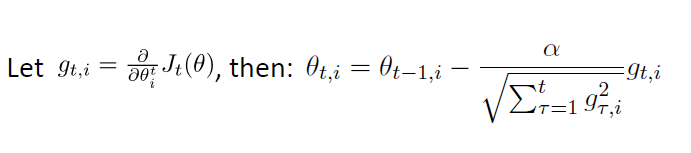
因为公式里面每一次迭代的梯度会除以历史梯度之和。也就是说历史上更新太多次之后,接下来就要打折扣了。历史上很少更新,那么每一次更新都会被重视。但是这相当于修改了梯度,是否还能收敛到原来的极值是一个问题,所以结果可能会有偏差。
Long-‐Term Dependencies and Clipping Trick
对于RNN这种结构很深的网络模型,每一次的梯度计算都会联系到之前的计算(连锁效应),所以梯度最后会变得非常大或者非常小,从而导致梯度下降崩溃。Mikolov提出了一个clip gradients to a maximum value的思想(直接对梯度进行修改,但是这相当于修改了目标函数,是否还能收敛到原来的极值还是一个问题,所以结果可能会有偏差。而类似dropout那些则没有对梯度进行修改),这对RNN模型有很大的影响。
Prevent overfiting: Model Size and Regularization
简化模型,比如减少hidden layer层数或曾每层的的unit数
使用L1或者L2范式对权值W进行regularization
Early Stopping:选择使cv set错误率小的模型参数
对hidden layer层的activation进行稀疏性限制:
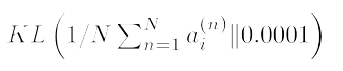
Prevent Feature Co-‐adaptation
Dropout:
1)训练时:使用SGD时,对于每一个训练样本,随机的将输入层的50%unit设置为0
2)测试时(test time):将权重W的值减半
3)naive bayes里每个参数都是独立的,naive假设。但是logistic回归,其实也应该包括神经网络一大类,参数之间是交错融合的。dropout是想在两者之间用随机硬切断的方式,取一个平衡点。
4)比如输入x1,x2,x3。参数w1,w2,w3。当随机x2为0时,就成了w1x1+w3x3。在这一次输入中,w1,w3就和w2没有交叉了
5)可以作为regularization工具来使用
Deep Learning Tricks of the Trade
无监督的pre-training
SGD和learning rate
各类主要参数的设定:
1)学习率&early stopping
2)小批度minibatch
3)参数的初始化
4)hidden units的数量
5)L1和L2范数的weight decay
6)稀疏性限制和regularization
如何有效率的设置模型的各个主要参数?随机设置!
参考:Y.Bengio(2012),“Practical Recommendations for Gradient-‐Based Training of Deep Architectures”
Language Models
语言模型中计算一系列单词相关的概率:P(w1,…,wT):
根据前m-1个词计算前m个词的概率
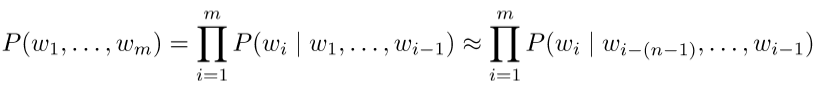
传统的针对语言模型的神经网络:
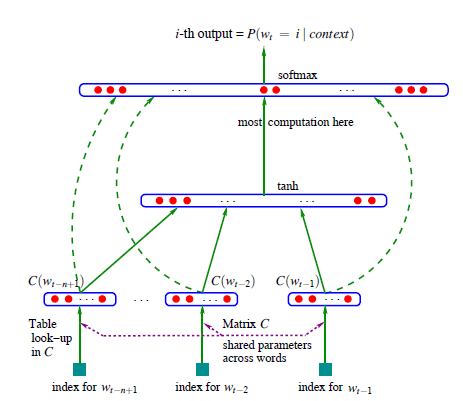
训练时只能是固定不变的context window size
Recurrent Neural Networks!
训练时,在每个时间点 (time step)上将word vector与对应的weight一起放进模型训练:
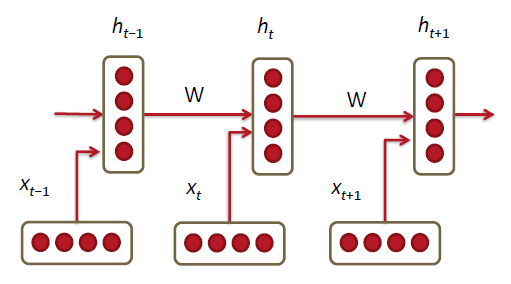
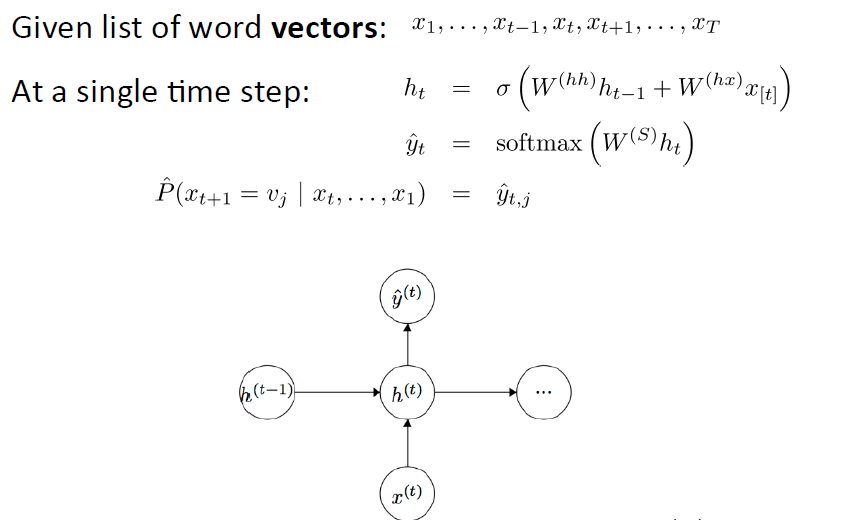
h0是第0个hidden layer的初始化向量
x【t】是在time step为t时,word vector矩阵L中对应的一个项向量(即其中的一个word vector):
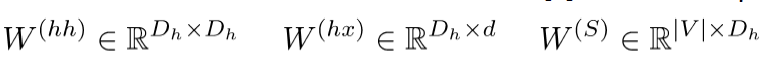
对于顶层的y:
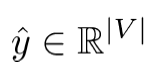
是整个词库的概率分布(预测的是单词),交叉熵不变:
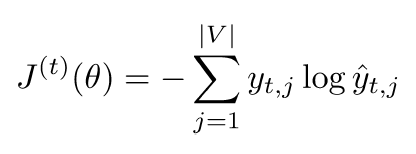















 2261
2261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









