







引言
什么是串行:
串行处理在原神世界中可以体现在玩家领取每日任务的方式上。当玩家前往冒险家协会的凯瑟琳处领取每日任务时,如果玩家只能一个个地领取任务奖励,那么这种方式就是串行处理。
具体来说,玩家需要依次排队等待领取任务奖励,每个玩家领取任务奖励后才能进行下一步操作。这种方式使得玩家领取任务的时间和效率受到限制,因为每个玩家都必须按照顺序一个一个地领取任务奖励。
什么是并行:
在原神游戏中,多名玩家可以在自己的世界中领取每日任务奖励,并在冒险家协会的凯瑟琳处领取。这种方式可以被看作是并行。
说白了就是
串行 :当有一位玩家 来 凯瑟琳领取每日任务奖励 那么凯瑟琳相当于银行的窗口,只开一个 领取奖励时,当多位玩家领取奖励时按照玩家依次入队顺序并且领取奖励
并行 :当多位玩家 玩原神 凯瑟琳相当于银行的多窗口,可以同时进行 每日任务领取奖励
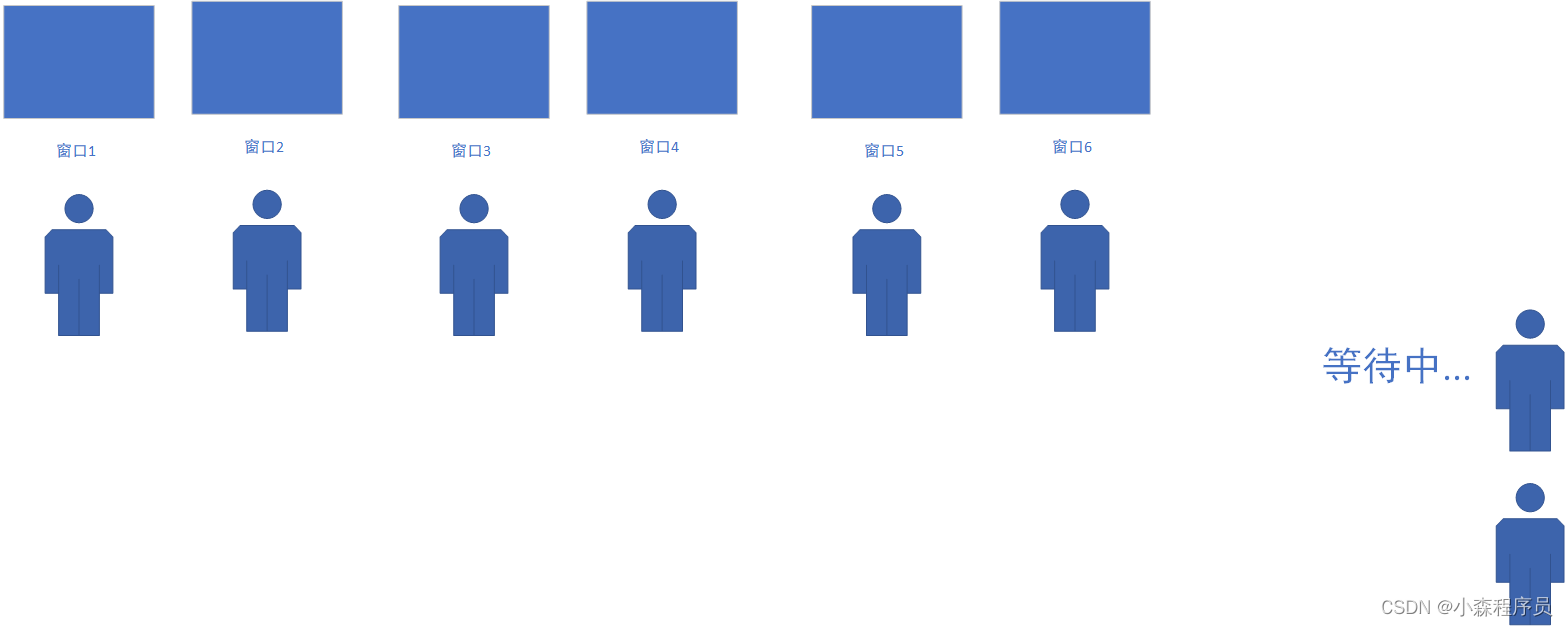
并发 基本认知
并发: 一个实体对多个事件同时处理,相当于同时处理多个任务
所为的串行
银行办理业务:只有一个窗口 那么只能排队 ,

所为的并发
银行办理业务:只有多个窗口 那么同时进行 虽然也需要排队,但窗口的银行人员都上齐
并发基本概念
无论 是计算设备 (台式机 手机 笔记本电脑 服务器) 都会拥有一颗计算的核心部件 :CPU
没错,就是我CPU 所有的运算通过CPU执行
进程 :在操作系统里 拥有资源的基本单位
按照工厂 来说 进程相当于工厂的车间 ,一个工厂 多个车间 对应着真正运行的 程序 不同的车间产生不同的工作 QQ和微信 首先他们是即时通讯软件 没错吧 ! 但他实现 的产品相同,但内部实现不一样 , 假设工厂车间 的拥有 指挥所有人员的管理者 这个管理者 岗位缺失 这个管理者也就是相当于计算机单核CPU 只能执行

虽然单个CPU的效率,看似乎只能执行一个进程,但他会切换 切换的时间 每秒执行 亿或者上百万条指令 单个CPU 是以时间片段 执行 可能以10微秒 的切换到另一个进程 把不同的时间片分给不同的进程
线程
线程就好比一个车间包含多条生产线
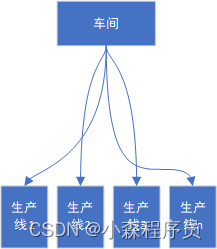
居然同一个车间 设备和人 都是共享 哪里缺什么就有人 拿给你
一个进程可以拥有多个线程 每个线程都可以 独立运行 多个线程可共享进程资源
并行搜索算法应用专区
问题描述:
给定一个包含无序数组,我们需要测试在一个特定值(maindata)测试在数组中的 搜索效率。程序需要记录搜索所需的总时间,并统计该特定值在数组中出现的次数。
串行搜索
#include <iostream>
using namespace std;
const int Size = 1024 * 1024 * 200; // 两亿数据量
const int maindata = 20;//搜索主要的数据
int main(void) {
int* data = new int[Size];
for (int i = 0; i < Size; ++i){
data[i] = i;
}
int count = 0;
time_t start;
time_t end;
time(&start);
for ( int i = 0; i < 10; i++){
for (int i = 0; i < Size; i++) {
if (data[i] == maindata) {
count++;
}
}
}
time(&end);
cout << "串行搜索一共花费多少时间(" << end - start << ")秒" << endl;
cout << "串行搜索统计数据出现的次数:" << count << endl;
getchar();
return 0;
}
并行搜索
创建线程
//创建线程ID1 相当于线程的身份证
DWORD threadId1;
HANDLE Hthread1 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId1);
HANDLE Hthread = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId);:
这行代码调用Windows API函数CreateThread来创建一个新线程,并将返回的线程句柄存储在变量Hthread中。
NULL:指定安全属性的指针,这里设置为NULL,表示使用默认的安全属性。
0:指定线程的初始堆栈大小,这里设置为0,表示使用默认的堆栈大小。
ParallelSearch:这是线程函数的名称或地址,具体实现的功能 。
NULL:传递给线程函数的参数,这里设置为NULL,表示不传递任何参数给线程函数。
0:指定线程的创建标志,这里设置为0,表示使用默认的创建标志。
&threadId1:指向DWORD变量的指针,用来接收新线程的ID。
线程函数 具体如何写?
DWORD WINAPI funcName(void* ThreadParameter) {
return 0;
}
虽然感觉好像写死 如果执行完,返回点东西 那么是没法子的 要么只能定义结构体 包含功能性返回值 参数设置修改等等 但也只能这样用 因为早期的也没有一些模版 啊什么的 当然就算模版 也不这么自由 要想达到恐怕得用全新的CPU 架构协议 到时候未必是所有的程序语言能够开发 应用系统 应用程序… 哈哈想太远了但CPU架构(x86,ARM … ) 这些 架构体系恐怕就是历史 硅芯片可能不复存在,取而代之的是可能是量子架构芯片系列 … 也许到哪全新的时代开始之后…
虽然C++11 有线程库但不能设置以下这些:
指定安全属性的指针
指定线程的初始堆栈大小
指定线程的创建标志,
不能灵活的 只能是 提供好 所有的函数类型(函数,成员函数,lambda 函数等等) 都可以使用线程类创建线程
//并行搜索
DWORD WINAPI ParallelSearch(void* ThreadParameter) {
for (int i = 0; i < 10; i++) {
cout << "并行搜索 线程 来了\n" ;
}
return 0;
}
int main(void) {
//创建线程
//创建线程ID1 相当于线程的身份证
DWORD threadId1;
//创建线程ID2 相当于线程的身份证
DWORD threadId2;
//创建线程
// CreateThread 返回这个线程的标识 可以理解 使用这个标识符就相当于操控线程
HANDLE Hthread1 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId1);
// Hthread1 创建标识
HANDLE Hthread2 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId2);
system("pause");
return 0;
}
输出结果 由于CPU执行过快 明细体现出线程的
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
并行搜索 线程 来了
请按任意键继续. . .
所以需要修改一下
让停顿一会在输出
//并行搜索
DWORD WINAPI ParallelSearch(void* ThreadParameter) {
for (int i = 0; i < 2; i++) {
printf("并行搜索 线程 来了\n");
Sleep(1000);
}
return 0;
}
并行搜索 线程 来了
并行搜索 线程 来了
请按任意键继续. . . 并行搜索 线程 来了
并行搜索 线程 来了
诶嘿 你会发现 两个线程 虽然都是同时发生 当然现在肯定看不到同时发生的 画个图就知道了
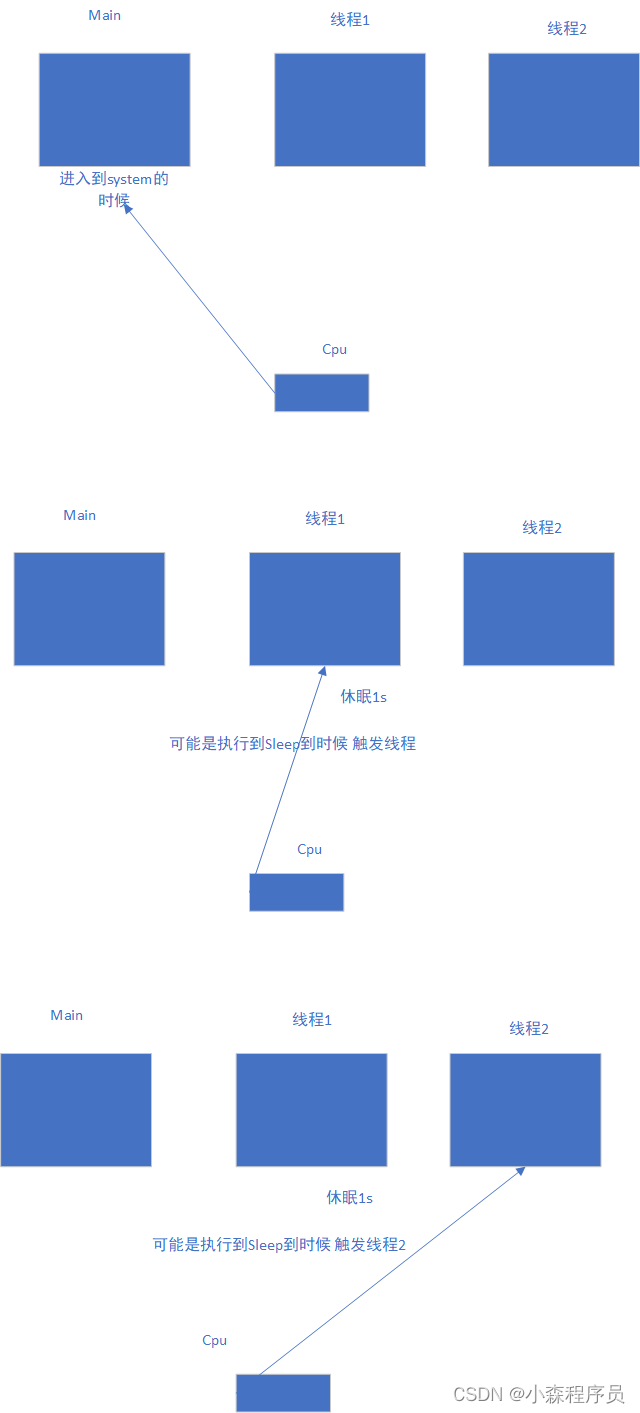
额,毕竟 我们又不是CPU 所以有点晕 不过没有关系 只要获取到他的线程1 的ID和线程2 的ID不就就可以了吗
获取线程ID函数是,GetCurrentThreadId() 返回值是无符号长整型
//并行搜索
DWORD WINAPI ParallelSearch(void* ThreadParameter) {
for (int i = 0; i < 2; i++) {
printf("并行搜索 线程id:%u 来了\n",GetCurrentThreadId());
Sleep(1000);
}
return 0;
}
输出 :
并行搜索 线程id:2720 来了
并行搜索 线程id:3016 来了
请按任意键继续. . . 并行搜索 线程id:3016 来了
并行搜索 线程id:2720 来了
有了线程ID后 还是会明显的很明显现在的输出,不是非常想要达到的效果
只需等待 一下 子线程 不就可以了吗
等待函数为 参数 线程标识 ,等待的秒数 INFINITE 是无论几秒钟直到线程执行完毕
WaitForSingleObject(Hthread, INFINITE);
#include <iostream>
#include<Windows.h>
using namespace std;
//并行搜索
DWORD WINAPI ParallelSearch(void* ThreadParameter) {
for (int i = 0; i < 2; i++) {
printf("并行搜索 线程id:%u 来了\n",GetCurrentThreadId());
Sleep(1000);
}
return 0;
}
int main(void) {
//创建线程
//创建线程ID1 相当于线程的身份证
DWORD threadId1;
//创建线程ID2 相当于线程的身份证
DWORD threadId2;
//创建线程
// CreateThread 返回这个线程的标识 可以理解 使用这个标识符就相当于操控线程
HANDLE Hthread1 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId1);
// Hthread1 创建标识
HANDLE Hthread2 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId2);
WaitForSingleObject(Hthread1, INFINITE);
WaitForSingleObject(Hthread2, INFINITE);
system("pause");
return 0;
}
输出;
并行搜索 线程id:15756 来了
并行搜索 线程id:2764 来了
并行搜索 线程id:15756 来了
并行搜索 线程id:2764 来了
请按任意键继续. . .
现在很明显已经对味了 这就是线程同步 当然现在不需要理会 现在的需求是 并行搜索
所以需要定义结构
所以你懂的
struct Search{
int* data; //需要查找 数据集
int startIdx;//起始位置
int endIdx;//结束位置
int count;// 统计
};
定义完结构体后
创建数据
//1)创建搜索的数据
int* data = new int[Size];
for (int i = 0; i < Size; ++i) {
data[i] = i;
}
创建两个线程
//2)创建线程
//创建线程ID1 相当于线程的身份证
DWORD threadId1;
//创建线程ID2 相当于线程的身份证
DWORD threadId2;
//创建线程
// CreateThread 返回这个线程的标识 可以理解 使用这个标识符就相当于操控线程
// Hthread1 创建标识
HANDLE Hthread1 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId1);
// Hthread2 创建标识
HANDLE Hthread2 = CreateThread(NULL, 0, ParallelSearch, NULL, 0, &threadId2);
//等待线程1,线程2 执行完毕
WaitForSingleObject(Hthread1, INFINITE);
WaitForSingleObject(Hthread2, INFINITE);
创建搜索结构体变量
int mid = Size / 2;
创建搜索结构体变量
Search s1;
Search s2;
初始化搜索结构体变量
s1.data = data;
s1.startIdx = 0;
s1.endIdx = mid;
s1.count = 0;
s2.data = data;
s2.startIdx = mid+1;
s2.endIdx = Size-1;
s2.count = 0;
将s1变量 传递到线程1
将s2变量 传递到线程2
// 5 )ParallelSearch 参数 传递
HANDLE Hthread1 = CreateThread(NULL, 0, ParallelSearch, &s1, 0, &threadId1);
// Hthread2 创建标识
HANDLE Hthread2 = CreateThread(NULL, 0, ParallelSearch, &s2, 0, &threadId2);
ParallelSearch线程函数 接收参数
//并行搜索
DWORD WINAPI ParallelSearch(void* ThreadParameter) {
printf("并行搜索 线程id:%u 来了\n", GetCurrentThreadId());
Search* s = (Search*)ThreadParameter;
time_t start;
time_t end;
time(&start);
for (int j = 0; j < 10; j++) {
for (int i = s->startIdx; i < s->endIdx; i++) {
if (s->data[i] == maindata) {
s->count++;
}
}
}
time(&end);
cout << "并行搜索一共花费多少时间(" << end - start << ")秒\n";
return 0;
}
完整代码
const int Size = 1024 * 1024 * 200; // 两亿数据量
const int maindata = 20;//搜索主要的数据
struct Search {
int* data;//搜索的数据集
int startIdx;//搜索元素的起始下标
int endIdx;//搜索元素的结束下标
int count;//统计数据出现的次数
};
//并行搜索
DWORD WINAPI ParallelSearch(void* ThreadParameter) {
printf("并行搜索 线程id:%u 来了\n", GetCurrentThreadId());
//接收参数
Search* s = (Search*)ThreadParameter;
time_t start;
time_t end;
time(&start);
for (int j = 0; j < 10; j++) {
for (int i = s->startIdx; i < s->endIdx; i++) {
if (s->data[i] == maindata) {
s->count++;
}
}
}
time(&end);
cout << "并行搜索一共花费多少时间(" << end - start << ")秒\n";
return 0;
}
int main(void) {
//1)创建搜索的数据
int* data = new int[Size];
for (int i = 0; i < Size; ++i) {
data[i] = i;
}
int mid = Size / 2;
//3)创建搜索结构体变量
Search s1;
Search s2;
//4 ) 初始化搜索结构体变量
s1.data = data;
s1.startIdx = 0;
s1.endIdx = mid;
s1.count = 0;
s2.data = data;
s2.startIdx = mid+1;
s2.endIdx = Size-1;
s2.count = 0;
//2)创建线程
//创建线程ID1 相当于线程的身份证
DWORD threadId1;
//创建线程ID2 相当于线程的身份证
DWORD threadId2;
//创建线程
// CreateThread 返回这个线程的标识 可以理解 使用这个标识符就相当于操控线程
// Hthread1 创建标识
// 5 )ParallelSearch 参数 传递
HANDLE Hthread1 = CreateThread(NULL, 0, ParallelSearch, &s1, 0, &threadId1);
// Hthread2 创建标识
HANDLE Hthread2 = CreateThread(NULL, 0, ParallelSearch, &s2, 0, &threadId2);
//等待线程1,线程2 执行完毕
WaitForSingleObject(Hthread1, INFINITE);
WaitForSingleObject(Hthread2, INFINITE);
//7 输出统计次数
cout << "并行搜索统计数据出现的次数:" << s1.count+s2.count << endl;
system("pause");
return 0;
}
输出:
并行搜索 线程id:18464 来了
并行搜索 线程id:6948 来了
并行搜索一共花费多少时间(5)秒
并行搜索一共花费多少时间(5)秒
并行搜索统计数据出现的次数:10
请按任意键继续. . .
















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











