







在回归问题中使用训练集估计模型的参数的原则一般都是使得我们的损失函数在训练集达到最小值,其实在实际问题中我们是可以让损失函数在训练集最小化为0。
但是我们的目的是让模型在测试集上也表现优异!
我们的模型并不能预测任意的情况。
建立机器学习的目的并不是为了在已有的数据集,也就是训练集上效果表现非常优异,我们希望建立的机器学习模型在未知且情况复杂的测试数据上表现优异,我们称这样的未出现在训练集的未知数据集成为测试数据集,简称测试集。我们希望模型在测试集上表现优异!因为假如我们根据股票市场前六个月的数据拟合一个预测模型,我们的目的不是为了预测以前这六个月越准越好,而是预测明天乃至未来的股价变化。
(a) 训练均方误差与测试均方误差:
在回归中,我们最常用的评价指标为均方误差,即: 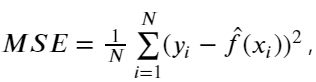

如果我们所用的数据是训练集上的数据,那么这个误差为训练均方误差,如果我们使用测试集的数据计算的均方误差,我们称为测试均方误差。
如何选择一个测试误差最小的模型呢
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3039
3039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









