







 文章讲述了如何在Excel中利用公式或Python的pandas库处理每隔15秒出现一次的时间数据,包括筛选法、替换法以及处理数据缺失情况的方法。最后给出了Python代码示例,用于提取并保存整分时间的行至新的Excel文件。
文章讲述了如何在Excel中利用公式或Python的pandas库处理每隔15秒出现一次的时间数据,包括筛选法、替换法以及处理数据缺失情况的方法。最后给出了Python代码示例,用于提取并保存整分时间的行至新的Excel文件。
任务:原excel文件第一列的时间每隔15s出现一次,如下图所示,现需要截取时间为整分的数据。
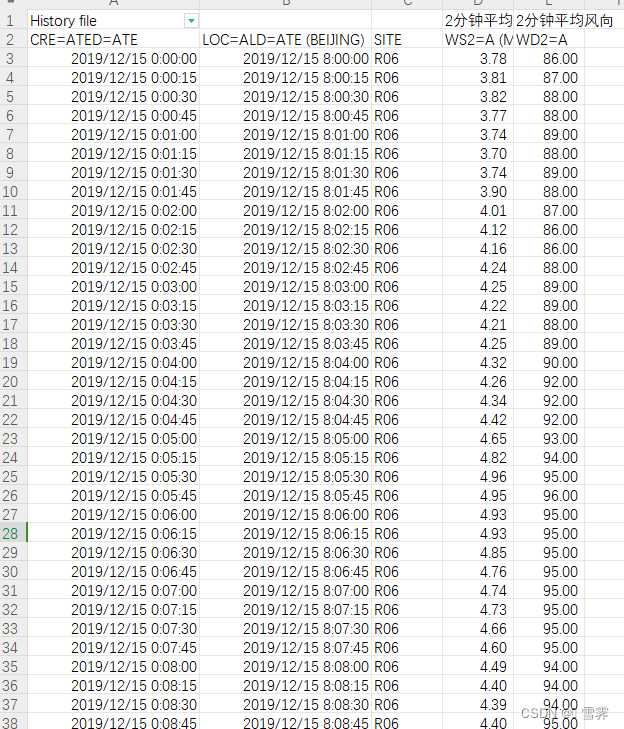
一、若数据严格按照15s出现一次,没有缺少数据,可按照以下方法进行处理
可以使用Excel的筛选功能来实现抽出一列数每隔4行一个数的操作。具体步骤如下:
第一种方法:=OFFSET(A$3,(ROW()-3)*4,0)
第二种方法:=INDEX(A$3:A$33,(ROW()-3)*4+1)
前两种方法选中空白处输入公式,然后选中该部分向下向右拖动即可。
注意:(1)要在上边fx的地方输入公式;(2)若格式有问题,可以使用格式刷

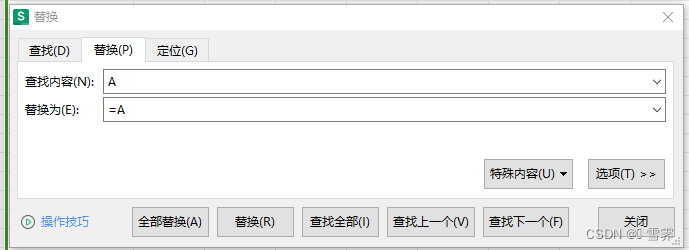
第三种方法:使用Ctrl+H,替换来激活公式实现
(1)先在I3和I4输入A3和A7,然后选中这两行下拉

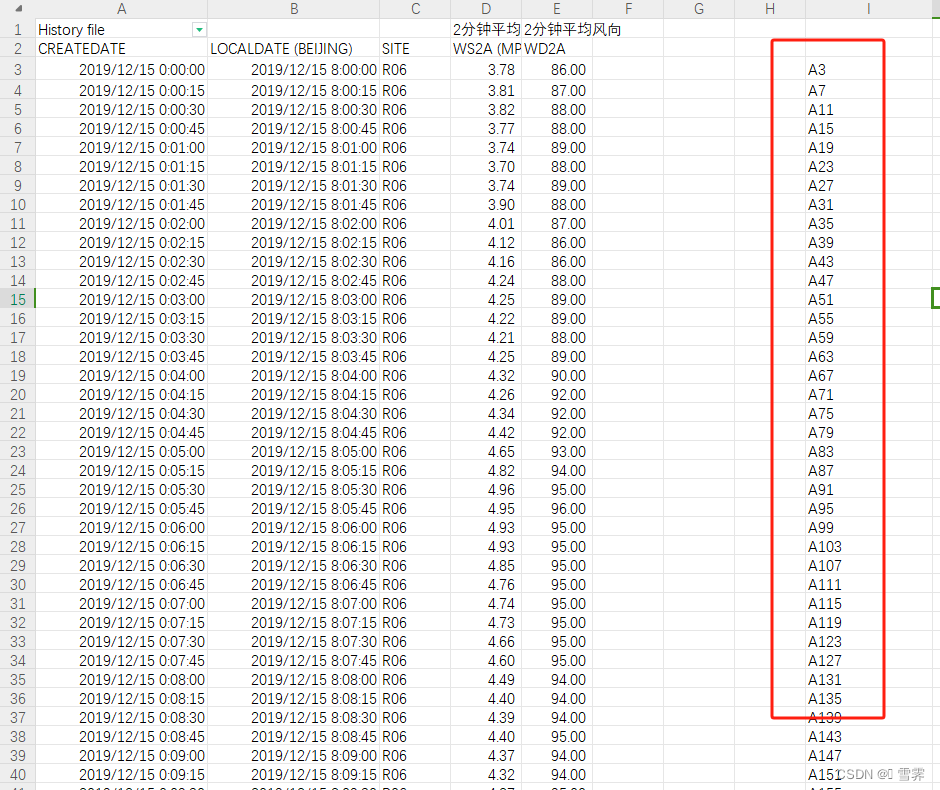
(2)使用Ctrl+H替换
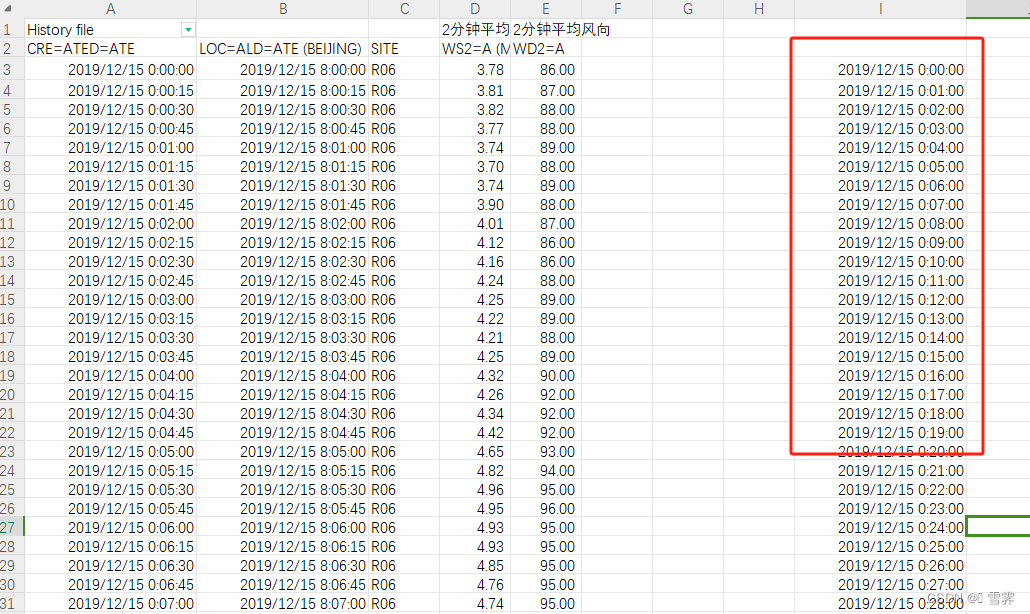
(3)可选中该列进行右拉,扩大操作范围
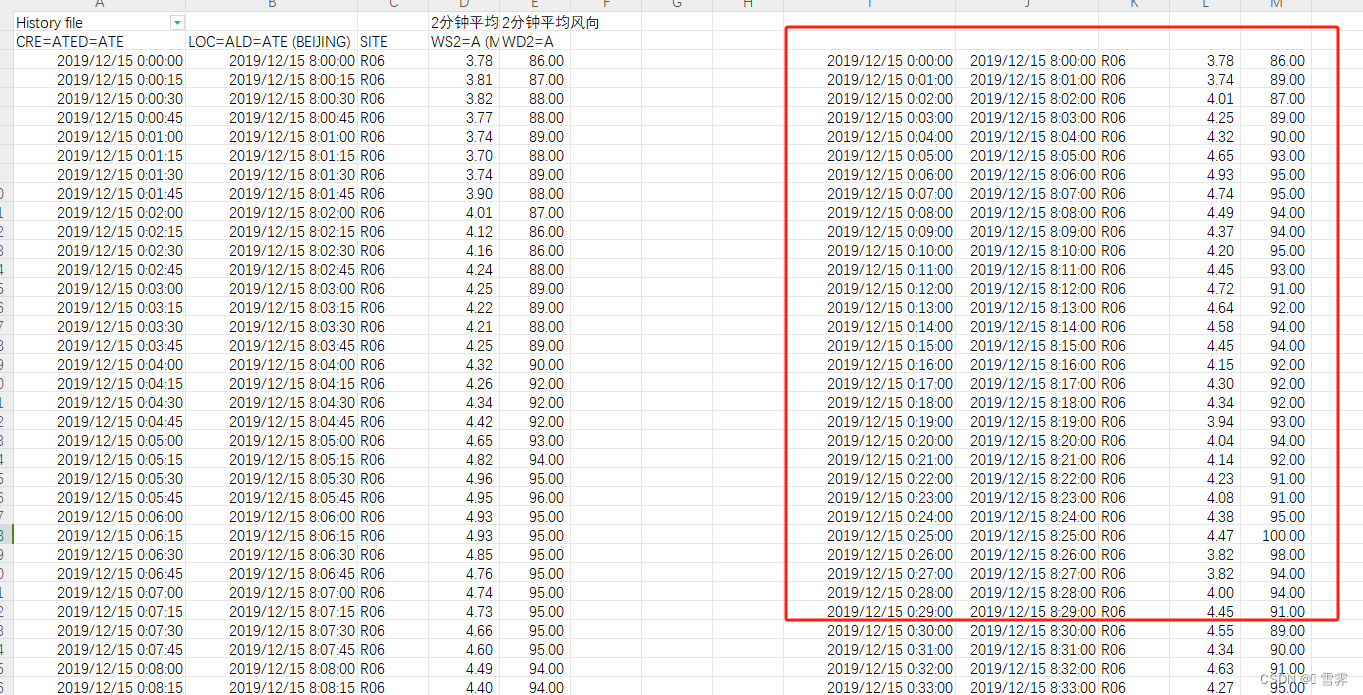
二、若数据有部分缺失,即并非每隔4次出现整分,可编写python代码对整分的数据进行提取
import pandas as pd
# 读取原始Excel文件
file_path = 'C:/Users/Administrator/Desktop/1.xlsx' # 替换为你的Excel文件路径
df = pd.read_excel(file_path, engine='openpyxl')
# 将日期时间列解析为datetime对象
df['History file'] = pd.to_datetime(df['History file'], format='%Y/%m/%d %H:%M:%S', errors='coerce')
# 提取时间部分为整分的行
filtered_data = df[df['History file'].dt.second == 0]
# 创建一个新的Excel文件并将数据保存到其中
output_file_path = 'C:/Users/Administrator/Desktop/output_excel_file.xlsx' # 新Excel文件的路径
filtered_data.to_excel(output_file_path, index=False, engine='openpyxl')
print(f"提取的数据已保存到 {output_file_path}")
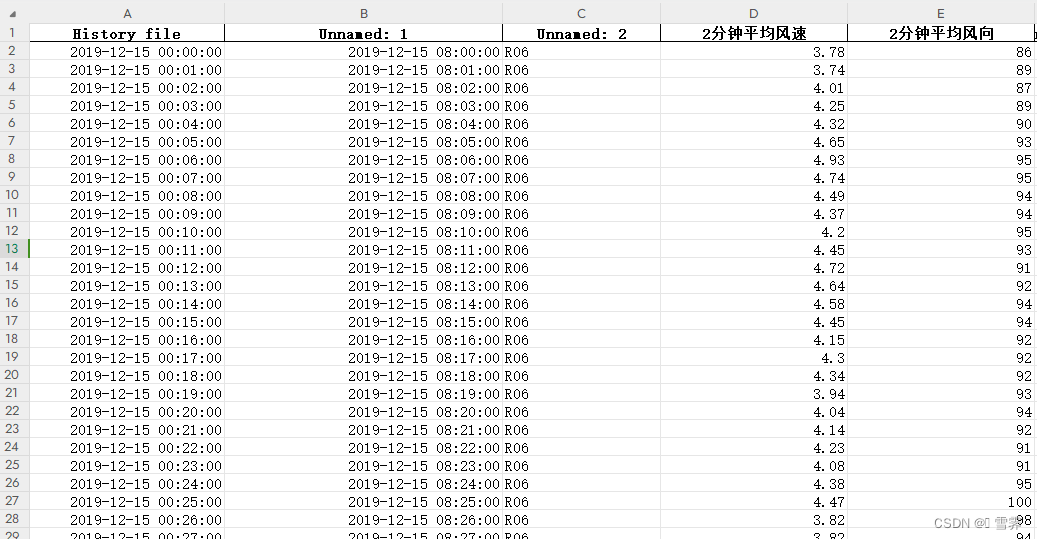
效果图下:

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









