







 本文深入解读DeepLab系列,尤其是DeepLabV3,探讨其在语义图像分割中的创新技术,如空洞卷积、ASPP模块、多尺度处理,以及如何应对DCNN在语义分割中的挑战。DeepLabV3通过空洞卷积和ASPP捕获多尺度信息,改善了分辨率降低和空间细节丢失的问题。在DeepLabV3+中,采用了更深的Xception结构和改进的解码器,进一步提升了模型性能。
本文深入解读DeepLab系列,尤其是DeepLabV3,探讨其在语义图像分割中的创新技术,如空洞卷积、ASPP模块、多尺度处理,以及如何应对DCNN在语义分割中的挑战。DeepLabV3通过空洞卷积和ASPP捕获多尺度信息,改善了分辨率降低和空间细节丢失的问题。在DeepLabV3+中,采用了更深的Xception结构和改进的解码器,进一步提升了模型性能。
DeepLabV3深入解读
DeepLabV3(以及一般的深度卷积神经网络,DCNNs)在图像级别的分类任务上表现优秀,因为它们通过多层的卷积、池化和全连接层,能够学习到图像中的抽象特征表示,这种表示通常对图像的平移和尺度变化具有不变性。
然而,当涉及到像素级别的分类任务(如姿态估计、语义分割等)时,这种平移不变性可能会成为问题。因为这些任务需要模型能够精确地区分图像中不同像素或区域的类别,而这通常需要保留更多的空间细节信息。
DeepLabV3 及其前身 DeepLabV1 和 DeepLabV2 为了解决这一问题,引入了一些创新的技术:
空洞卷积(Atrous Convolution):也被称为扩张卷积或带孔卷积,它在卷积核中引入了“空洞”(即零值),从而在不减少特征图空间尺寸的情况下,增加了卷积核的感受野。这有助于模型捕获更多的上下文信息,同时保持较高的空间分辨率。
空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP):ASPP 模块并行地采用了多个不同采样率的空洞卷积来探测不同尺度的信息,然后将这些信息融合起来。这有助于模型处理不同大小的目标。
条件随机场(Conditional Random Field, CRF):虽然 DeepLabV3 本身并没有直接使用 CRF,但之前的版本(如 DeepLabV1)曾使用 CRF 作为后处理步骤来细化分割结果。CRF 是一种概率图模型,可以捕获像素之间的上下文关系,有助于提升分割的准确性和边界的平滑性。
编码器-解码器结构:虽然 DeepLabV3 主要关注于空洞卷积和 ASPP,但后续的版本(如 DeepLabV3+)采用了编码器-解码器结构,其中编码器使用 DeepLabV3 作为骨干网络,而解码器则用于恢复空间细节。这种结构有助于在保持高级语义信息的同时,恢复更多的空间细节。
通过这些技术,DeepLabV3 及其后续版本在语义分割等像素级别分类任务上取得了显著的性能提升。
1、DeepLab系列简介
1.1.DeepLabV1
作者发现Deep Convolutional Neural Networks (DCNNs) 能够很好的处理的图像级别的分类问题,因为它具有很好的平移不变性(空间细节信息已高度抽象),但是DCNNs很难处理像素级别的分类问题,例如姿态估计和语义分割,它们需要准确的位置信息。
1.1.1创新点:
- 将深度神经网络DCNN与全连接CRF结合起来,提高图像分割的分割精度。
- 提出空洞卷积的思想。
- 应用尝试了多尺度、多层次的信息融合。
1.1.2. 动机:
DCNN应用在语义分割任务上存在两个缺陷:
- 重复堆叠的池化和下采样操作导致分辨率大幅下降,位置信息丢失难以恢复。
- 从分类器获得以对象为中心的决策需要空间转换的不变性,忽略对细节处的把控,这从本质上限制了DCNN模型的空间准确性。
分类任务具有空间不变性,图像的仿射变换不会影响最后的分类结果,而且恰恰通过仿射变换等操作(数据增广)可以增加数据量,提高模型的精度;但是像分割和检测这类问题,不具有空间不变性。
1.1.3. 应对策略:
- 空洞卷积
- Fully-connected Conditional Random Field (CRF)
1.2.DeepLabV2
1.2.1.创新点:
- 空洞卷积,作为密集预测任务的强大工具。空洞卷积能够明确地控制DCNN内计算特征响应的分辨率。它还允许我们有效地扩大滤波器的视野以并入较大的上下文,而不增加参数的数量或计算量。
- 提出了空洞空间卷积池化金字塔(atrous spatial pyramid pooling (ASPP)),以多尺度的信息得到更精确的分割结果。ASPP并行的采用多个采样率的空洞卷积层来探测,以多个比例捕捉对象以及图像上下文。
- 通过组合DCNN和概率图模型(CRF),改进分割边界结果。在DCNN中最大池化和下采样组合实现可平移不变性,但这对精度是有影响的。通过将最终的DCNN层响应与全连接的CRF结合来克服这个问题。
1.2.2.动机
DCNNs中语义分割存在三个挑战:
- 连续下采样和池化操作,导致最后特征图分辨率低。
- 图像中存在多尺度的物体(相比V1而言提出的新的挑战)
- 空间不变性导致细节信息丢失
1.2.3. 应对策略:
- 移除部分池化操作,使用空洞卷积。
- 利用不同膨胀因子的空洞卷积融合多尺度信息—atrous spatial pyramid pooling(ASPP)(新的创新点)
- 全连接CRF。
1.3.DeepLabV3
1.3.1创新点:
- 增加了多尺度(multiple scales)分割物体的模块
- 设计了串行和并行的空洞卷积模块,采用多种不同的atrous rates(采样率)来获取多尺度的内容信息
1.3.2. 动机:
DCNN中语义分割存在三个挑战:
- 连续下采用和重复池化,导致最后特征图分辨率低
- 图像中存在多尺度的物体
1.3.3. 应对策略:
- 使用空洞卷积,防止分辨率过低情况
- 串联不同膨胀率的空洞卷积或者并行不同膨胀率的空洞卷积(v2的ASPP),来获取更多上下文信息
1.3.4. 主要贡献:
- 重新讨论了空洞卷积的使用,这让我们在级联模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息
- 改进了ASPP模块:由不同采样率的空洞卷积和BN层组成,我们尝试以级联或并行的方式布局模块
- 讨论了一个重要问题:使用大采样率的3×3的空洞卷积,因为图像边界的原因无法捕捉远距离信息,会退化为1×1的卷积, 作者提出将图像级特征融合到ASPP模块中
- 阐述了训练细节并分享了训练经验,论文提出的"DeepLabv3"改进了以前的工作,获得了很好的结果
1.4.DeepLabV3+
1.4.1.创新点:
- 更深的Xception结构,不同的地方在于不修改entry flow network的结构,为了快速计算和有效的使用内存
- 所有的max pooling结构被stride=2的深度可分离卷积代替
- 每个3x3的depthwise convolution都跟BN和Relu
- 将改进后的Xception作为encodet主干网络,替换原本DeepLabv3的ResNet101
1.4.2. 动机:
语义分割主要面临两个问题:
- 物体的多尺度问题(DeepLabV3解决)
- DCNN的多次下采样会造成特征图分辨率变小,导致预测精度降低,边界信息丢失(DeepLabV3+解决目标)
1.4.3. 应对策略:
- 改进Xception,层数增加
- 将所有最大值池化层替换为带步长的深度可分离卷积层
2、DeepLabV3详解
2.1.提出问题
首先,语义分割问题存在两大挑战:
- 第一个挑战:连续池化操作或卷积中的stride导致的特征分辨率降低。这使得DCNN能够学习更抽象的特征表示。然而,这种不变性可能会阻碍密集预测任务,因为不变性也导致了详细空间信息的不确定。为了克服这个问题,提倡使用空洞卷积。
- 第二个挑战:多尺度物体的存在。几种方法已经被提出来处理这个问题,在本文中我们主要考虑了这些工作中的四种类型,如图1所示。
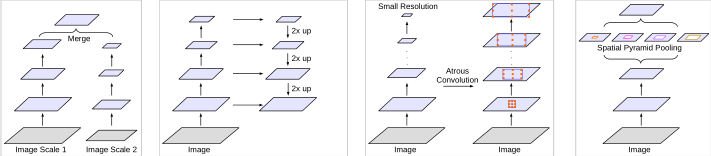
- 第一种:Image Pyramid,将输入图片放缩成不同比例,分别应用在DCNN上,将预测结果融合得到最终输出
- 第二种:Encoder-Decoder,将Encoder阶段的多尺度特征运用到Decoder阶段上来恢复空间分辨率
- 第三种:在原始模型的顶端叠加额外的模块,以捕捉像素间长距离信息。例如Dense CRF,或者叠加一些其他的卷积层
- 第四种:Spatial Pyramid Pooling空间金字塔池化,使用不同采样率和多种视野的卷积核,以捕捉多尺度对象
DeepLabV3的提出是为了解决多尺度下的目标分割问题。如图2所示,不同目标在图中的尺寸大小不同,这也导致模型考虑不同尺寸的分割精度。

2.2.提出解决方案
2.2.1.用级联的方式设计了空洞卷积模块
具体而言,DeepLabV3取ResNet中最后一个block(ResNet的block4),并将他们级联到了一起,如图3所示。
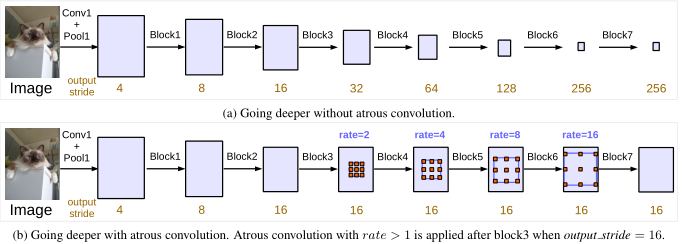
有三个3×3卷积在这些块中,除了最后一个块,其余的模块中最后的一个卷积步长为2,类似于原来的ResNet。这么做背后的动机是,引入的stride使得更深的模块更容易捕获长距离的信息。如图3(a),整个图像的特征都可以汇聚在最后一个小分辨率的特征图中。
然而,我们发现连续的stride对语义分割是有害的,会造成细节信息的丢失
从表中看得出,输出步长out_stride = 8时占用更多的内存,但同时带来了更好的性能。例如图3(b)中,输出步长为out_stride = 16。这样不增加参数量和计算量的同时有效的缩小了步幅。
2.2.2. 使用了Multi-Grid 策略
受到了采用不同大小网格层次结构的多重网格方法的启发,我们提出的模型在block4和block7中采用了不同的空洞率。
特别的,我们定义$ Multi_Grid = ({r_1},{r_2},{r_3}) 为 b l o c k 4 到 b l o c k 7 内三个卷积层的 u n i t r a t e s 。卷积层的最终空洞率等于 u n i t r a t e 和 c o r r e s p o n d i n g r a t e 的乘积。例如,当 为block4到block7内三个卷积层的unit rates。卷积层的最终空洞率等于unit rate和corresponding rate的乘积。例如,当 为block4到block7内三个卷积层的unitrates。卷积层的最终空洞率等于unitrate和correspondingrate的乘积。例如,当 output_stride = 16,Multi_Grid = (1,2,4) ,三个卷积就会在 b l o c k 4 有。 ,三个卷积就会在block4有。 ,三个卷积就会在block4有。 rates = 2 \cdot (1,2,4) = (2,4,8)$
2.2.3.将 batch normalization 加入到 ASPP模块.
Atrous Spatial Pyramid Pooling(ASPP):
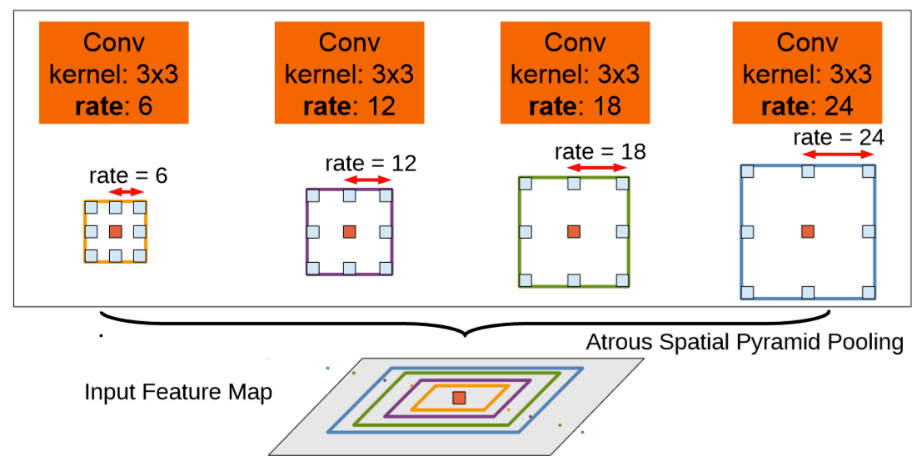
上图是DeeplabV2中的ASPP,在特征顶部映射图使用了四中不同采样率的空洞卷积。我这表明以不同尺度采样时有效的,在Deeolabv3中向ASPP中添加了BN层。不同采样率的空洞卷积可以有效捕获多尺度信息,但会发现随着采样率的增加,滤波器有效权重(权重有效的应用在特征区域,而不是填充0)逐渐变小。
当output_stride=8时,加倍了采样率。所有特征通过1x1级联到一起,生成最终的分数。
ASPPModule代码:
class ASPPModule(nn.Layer):
"""
Atrous Spatial Pyramid Pooling.
Args:
aspp_ratios (tuple): The dilation rate using in ASSP module.
in_channels (int): The number of input channels.
out_channels (int): The number of output channels.
align_corners (bool): An argument of F.interpolate. It should be set to False when the output size of feature
is even, e.g. 1024x512, otherwise it is True, e.g. 769x769.
use_sep_conv (bool, optional): If using separable conv in ASPP module. Default: False.
image_pooling (bool, optional): If augmented with image-level features. Default: False
"""
def __init__(self,
aspp_ratios,
in_channels,
out_channels,
align_corners,
use_sep_conv=False,
image_pooling=False,
data_format='NCHW'):
super().__init__()
self.align_corners = align_corners
self.data_format = data_format
self.aspp_blocks = nn.LayerList()
for ratio in aspp_ratios:
if use_sep_conv and ratio > 1:
conv_func = layers.SeparableConvBNReLU
else:
conv_func = layers.ConvBNReLU
block = conv_func(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1 if ratio == 1 else 3,
dilation=ratio,
padding=0 if ratio == 1 else ratio,
data_format=data_format)
self.aspp_blocks.append(block)
out_size = len(self.aspp_blocks)
if image_pooling:
self.global_avg_pool = nn.Sequential(
nn.AdaptiveAvgPool2D(
output_size=(1, 1), data_format=data_format),
layers.ConvBNReLU(
in_channels,
out_channels,
kernel_size=1,
bias_attr=False,
data_format=data_format))
out_size += 1
self.image_pooling = image_pooling
self.conv_bn_relu = layers.ConvBNReLU(
in_channels=out_channels * out_size,
out_channels=out_channels,
kernel_size=1,
data_format=data_format)
self.dropout = nn.Dropout(p=0.1) # drop rate
def forward(self, x) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











