 深度学习语义分割:DeepLabV3改进与多尺度处理
深度学习语义分割:DeepLabV3改进与多尺度处理





一、待解决的问题
- 连续下采样和重复池化,导致最后特征图分辨率低
- 图像中存在多尺度问题
- 空间不变性导致细节信息丢失(v3未采用CRF)
二、创新点
- 增加多尺度分割物体的模块,设计了串行和并行的空洞卷积模块,采用不同的膨胀率atrous rates来获取多尺度的信息
- 优化ASPP模块,加入1*1卷积和编码了全局信息的图像层特征image pooling,进一步挖掘不同尺寸的特征,提升分割效果。
- 不再需要DenseCRF作为后处理
三、具体细节
1.总结多尺度问题的四个解决方案:
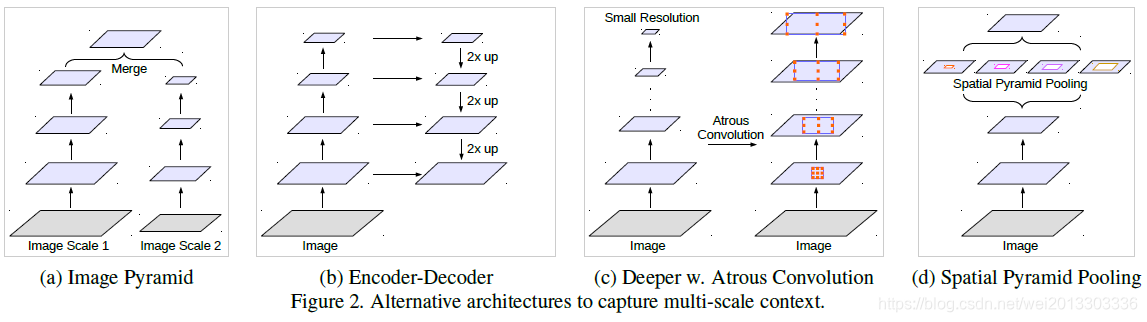
- 方案a: 图像金字塔,把图像Resize到不同尺寸,输入到同一个网络中,最后把不同尺寸输入图像得到的特征图Merge到一起作为输出;
- 方案b:编解码结构,在解码网络不同阶段融合编码网络不同阶段的特征(同时保证低维度的信息不丢失)
- 方案c:在原始网络输出后添加额外的context后处理模块,例如DenseCRF。或者串联不同膨胀率的空洞卷积模块,来获取不同尺度的信息(图c为后者)。
- 方案d:ASPP,空洞卷积空间金字塔池化,在输入特征上平行地获取不同尺度的信息,融合后最为输出。
2.更深结构下的空洞卷积
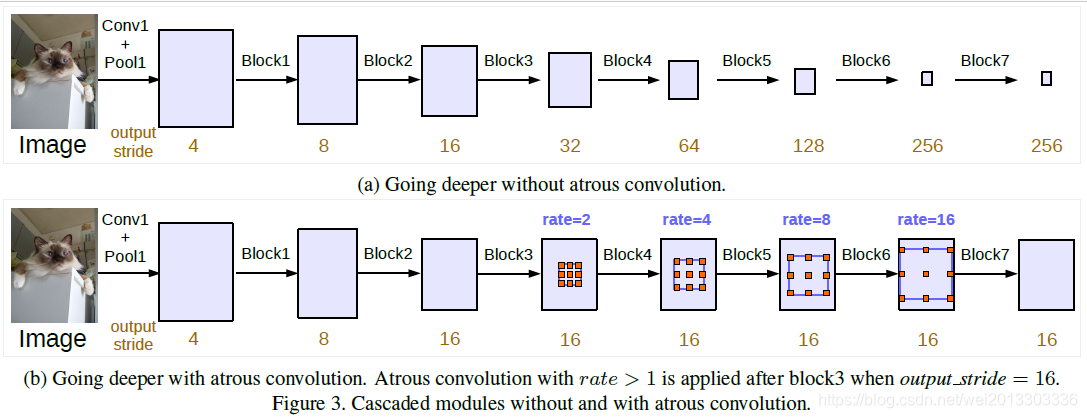
图a在更深的网络后,连续的下采样虽然增加了感受野,但是会导致最后特征图的分辨率很低,丢失了大量的细节信息,不利于语义分割。
图b采用串联空洞卷积,保持输出步幅在out_stride=16的情况下,保证分辨率,逐步增加感受野。
3.优化ASPP
作者通过实验发现,膨胀率越大,卷积核中的有效权重越少,当膨胀率足够大时,只有卷积核最中间的权重有效,即退化成了1x1卷积核,并不能获取到全局的context信息。3x3的卷积核中有效权重与膨胀率的对应如下:
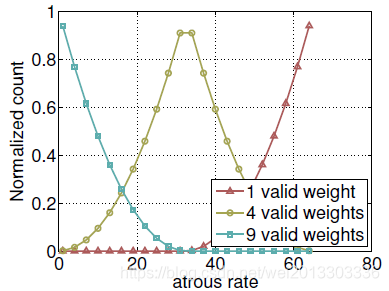
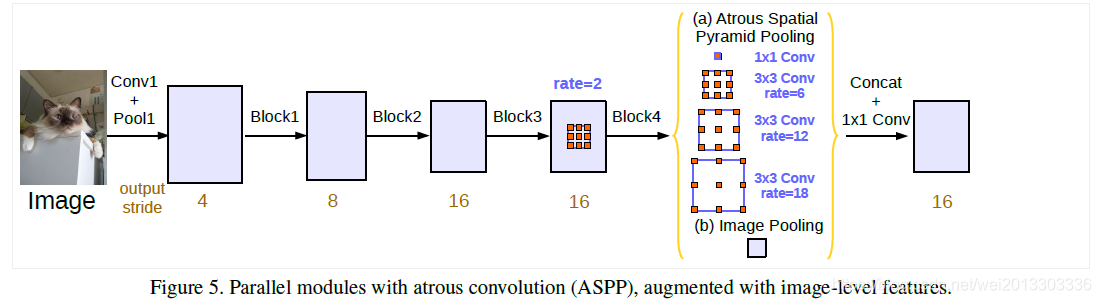
为了克服这个问题,作者考虑使用图片级特征。具体来说,在模型最后的特征映射上应用全局平均,将结果经过1×1的卷积,再双线性上采样得到所需的空间维度。最终,作者改进的ASPP包括:
- 使用了Multi-Grid策略,即在模型后端多加几层不同rate的空洞卷积。每个block中的三个卷积有各自unit rate,例如Multi Grid = (1, 2, 4),block的dilate rate=2,则block中每个卷积的实际膨胀率=2* (1, 2, 4)=(2,4,8)
- 一个1×1卷积和三个3×3的采样率为rates={6,12,18}的空洞卷积
- 将BN层加到了ASPP模块中
- 图像级特征,即将特征做全局平均池化,如下图(b)部分Image Pooling
- 得到的图像级特征Concat后输入到一个 1×1 convolution with 256 filters(1*1 256滤波器),然后将特征进行双线性上采样(bilinearly upsample)到特定的空间维度。
从代码中看上述几点的具体实现,见注释:
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _ASPP(nn.Module):
"""
Atrous spatial pyramid pooling with image-level feature
"""
def __init__(self, in_ch, out_ch, rates):
super(_ASPP, self).__init__()
self.stages = nn.Module()
self.stages.add_module("c0", _ConvBnReLU(in_ch, out_ch, 1, 1, 0, 1)) # 1 * 1 卷积
for i, rate in enumerate(rates):
self.stages.add_module(
"c{}".format(i + 1),
_ConvBnReLU(in_ch, out_ch, 3, 1, padding=rate, dilation=rate),
) # rates = [6, 12, 18] 空洞卷积, BN层添加到ASPP中(v2只有卷积层)
self.stages.add_module("imagepool", ASPPPooling(in_ch, out_ch)) # globel image pooling, 其输入也是网络提取到的特征
def forward(self, x):
return torch.cat([stage(x) for stage in self.stages.children()], dim=1)
class DeepLabV3(nn.Sequential):
"""
DeepLab v3: Dilated ResNet with multi-grid + improved ASPP
"""
def __init__(self, n_classes, n_blocks, atrous_rates, multi_grids, output_stride):
super(DeepLabV3, self).__init__()
# Stride and dilation
if output_stride == 8:
s = [1, 2, 1, 1]
d = [1, 1, 2, 4]
elif output_stride == 16:
s = [1, 2, 2, 1]
d = [1, 1, 1, 2]
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], s[0], d[0]))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], s[1], d[1]))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], s[2], d[2]))
self.add_module(
"layer5", _ResLayer(n_blocks[3], ch[4], ch[5], s[3], d[3], multi_grids)
) # output_stride=16时,d[3] = 2,通过multi_grids,实际bootleneck中空洞卷积dilate rate = d[3] * multi_grides[i]
self.add_module("aspp", _ASPP(ch[5], 256, atrous_rates))
concat_ch = 256 * (len(atrous_rates) + 2)
self.add_module("fc1", _ConvBnReLU(concat_ch, 256, 1, 1, 0, 1)) # 1 * 1 256滤波器
self.add_module("fc2", nn.Conv2d(256, n_classes, kernel_size=1))
model = DeepLabV3(
n_classes=21,
n_blocks=[3, 4, 23, 3], # 4个block对应的bottleneck数量
atrous_rates=[6, 12, 18], # ASPP空洞卷积rates
multi_grids=[1, 2, 4], # 最后一个block中每个bottleneck对应的grid
output_stride=16,
)

















 4180
4180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









