







这篇文章来自于谷歌的《Rethinking Atrous Convolution for Semantic Image Segmentation》,发表于2017年。
1. 研究问题
研究空洞卷积在语义分割中的作用。
2. 研究方法
DeepLabV3提出级联不同空洞率的空洞卷积来提取多尺度上下文,减小由于池化或跨步卷积引起的细节特征丢失,又提出了采用图像级特征来增强ASPP模块,来解决由于空洞率增加导致的卷积核退化问题。并且经过实验发现,在空洞卷积中加入BN可以提升网络性能。
2.1 多尺度架构回顾
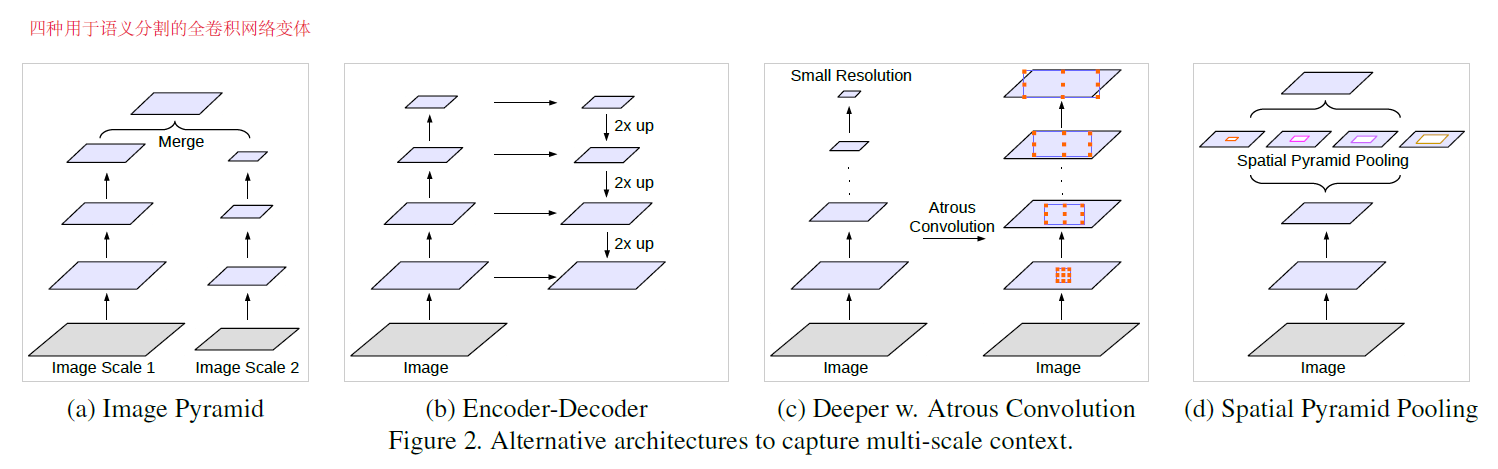
除了以上四种,还有一种Context module,就是级联DenseCRF模块捕获远程上下文,一般用于后处理。
2.2 级联空洞卷积
空洞卷积实际上相当于在卷积核中插入空洞,如下图所示,空洞率控制着空洞的数量,空洞率越大,感受野也越大,当rate=1时,就是普通卷积。

下图是采用级联多空洞率的空洞卷积代替池化或跨步卷积,可以看到,空洞卷积可以扩大感受野,但可以不进行降采样,这样就能保留很多细节特征。
output_stride是指输入图像核输出特征图的分辨率之比。文中提出一种Multi-grid method,其实就是级联空洞率的设置,下图的空洞率就是(2,4,8,16).

2.3 改进ASPP
既然空洞卷积这么好,那我们是不是可以将空洞率无限增加呢?并不是,文章给出了解释,当空洞率增加到与输入特征图分辨率相等时,任何大小的卷积核都退化为1*1卷积核了。这只是一种极限情况,这说明了空洞卷积可能导致提取不到期望的全局上下文,如下图所示。

文章针对ASPP提出了解决卷积核退化的一个方法,就是往ASPP中加入一个全局池化的图像级特征,来补偿由于大空洞率导致的无法提取全局上下文问题。如下图所示。同时,相比于原始ASPP来说,还加入了BN,也改进了ASPP。

3. 实验结果
训练策略:
- 数据集:PASCAL VOC 2012,1464 (train), 1449 (val), and1456 (test)
- 数据增强
[29]:随机剪裁和随机左右翻转,导致10582个训练样本 - 学习率:poly learning rate
- 图片裁剪:裁剪到513*513,训练和测试都是
- BN:训练到一定代数的时候固定BN,再继续训练。这里还提出训练到一定程度的时候改变空洞率的设置。
- 上采样逻辑:将输出上采样而不是将groundtruth下采样,这样会保证反向传播中能学习到细节特征

3.1 更深的空洞卷积




3.2 ASPP


上面的改进ASPP模块已经超越了DeepLabV2中的ASPP with DenseCRF的性能。

Figure 6. Visualization results on the val set when employing our best ASPP model. The last row shows a failure mode.

Figure 8. Visualization results on Cityscapes val set when training with only train_fine set.
4. 结论
(1)在没有DenseCRF后处理的时候,在PASCAL VOC 2012测试集上获得85.7%的准确率。
(2)级联多空洞率的空洞卷积可以增加感受野,同时减小细节丢失。
(3)ASPP中加入全局池化可以解决卷积核退化问题。















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









