







一.最简单的方法,如果安装好了digits,则直接可以使用digits来制作。
二.则是自己制作,制作步骤如下:
1.收集数据,以mnist数据集为例,下面有两个文件夹,分别为train和val;

train和val分别有10类数据
2.使用脚本制作label;
应该注意,这两个txt文件具体应该怎么填写,要和train、val文件夹里是怎么放图像的一一对应起来。实际上train.txt与val.txt存放的正是各幅图像的“相对路径+label”。
import os.path
import glob
path = "pics/mnist/train" #此处为数据集(train和val)的绝对路径
labellist = os.listdir(path)
for label in labellist:
newpath = os.path.join(path, label)
# print newpath, label
for root, dirs, files in os.walk(newpath):
for file in files:
print root, file
f = open(os.path.join(path, "train.txt"), "a")
f.write(os.path.join(label, file) + " " + label + "\n")脚本制作完成后,会出现如下两个文件,train.txt与val.txt。
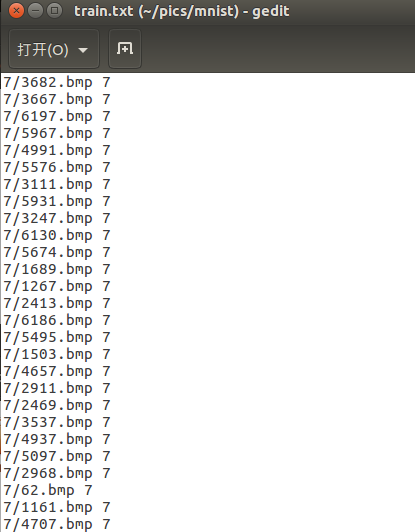
train.txt部分截图如下所示:
3.制作lmdb文件;
例用CAFFE_ROOT\examples\imagenet下的create_imagenet.sh脚本。然后对里面的路径进行设定。
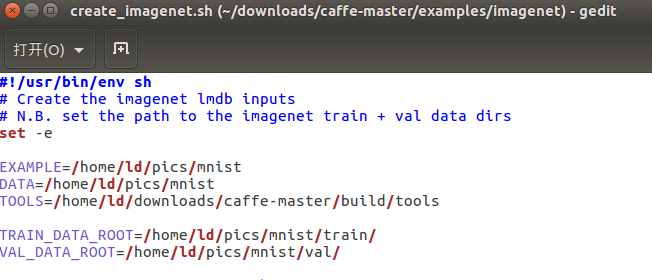
完成路径设定之后,运行该sh文件,即可在pic/mnist文件夹下生成imagenet_train_lmdb与 imagenet_val_lmdb文件夹。
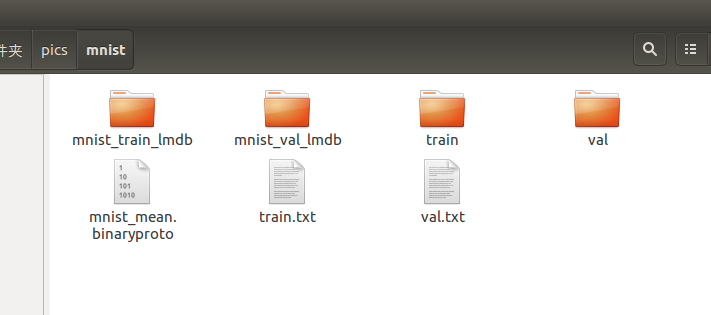
至此,caffe需要的数据集就制作好了。















 3481
3481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









