







目录
一、引言:开启机器学习之门
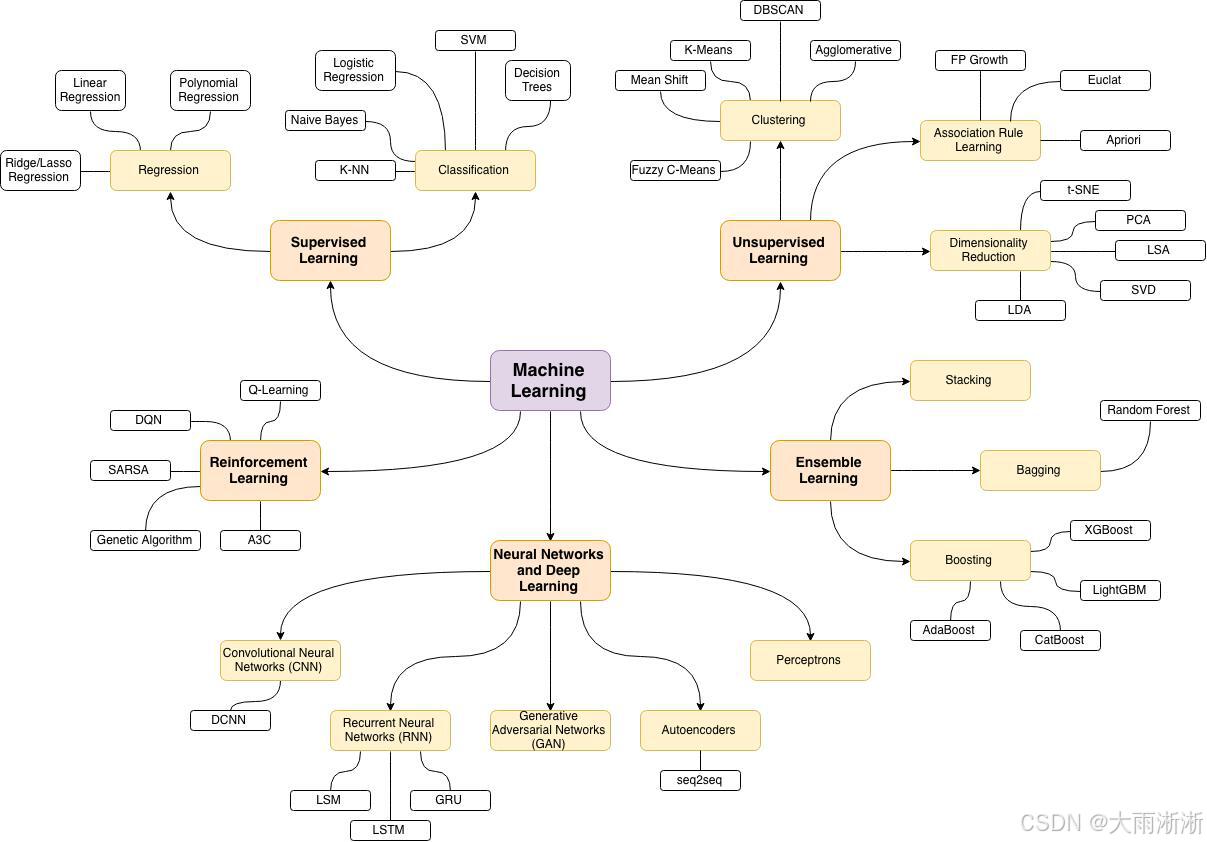
在当今数字化时代,机器学习已不再是一个陌生的词汇,它如同一位无形的助手,悄然融入我们生活的方方面面。你是否想过,为什么购物平台总能精准推荐你心仪的商品?为什么搜索引擎能瞬间呈现出你想要的信息?又为什么智能语音助手能够理解你的指令并给出准确回应?答案就是机器学习。
简单来说,机器学习是人工智能的一个分支,它让计算机通过数据学习模式和规律,从而实现对未知数据的预测和决策 。打个比方,就像我们小时候学习识别水果,父母会指着苹果、香蕉、橘子等水果告诉我们它们的名字和特征,我们通过不断观察和记忆这些信息,以后再看到这些水果就能准确识别出来。机器学习也是如此,计算机通过大量的数据进行 “学习”,然后利用学到的知识来处理新的数据。
而在机器学习的广阔领域中,Scikit-learn 无疑是一颗璀璨的明星。它是一个基于 Python 语言的开源机器学习库,为我们提供了丰富而强大的工具和算法,使得机器学习的实现变得更加简单和高效。无论是数据预处理、模型选择、训练还是评估,Scikit-learn 都能一站式搞定。可以说,Scikit-learn 是开启机器学习大门的一把关键钥匙,帮助无数开发者和数据科学家在机器学习的道路上畅通前行。接下来,就让我们一起深入探索 Scikit-learn 的奇妙世界吧!
二、Scikit-learn 初相识
(一)什么是 Scikit-learn
Scikit-learn,又简称为 sklearn,是基于 Python 语言开发的机器学习库 。它诞生于 2007 年,凝聚了众多开发者的心血,经过多年的发展和完善,已经成为 Python 机器学习领域的中流砥柱。
Scikit-learn 是基于 NumPy、SciPy 和 matplotlib 构建。NumPy 提供了高效的多维数组操作能力,为 Scikit-learn 的数据处理奠定了基础;SciPy 则包含了丰富的数学算法和函数,助力 Scikit-learn 实现各种复杂的计算;而 matplotlib 作为强大的绘图库,让 Scikit-learn 能够将数据和模型以直观的图表形式展现出来。
Scikit-learn 提供了丰富的机器学习算法和工具,涵盖了分类、回归、聚类、降维等多种机器学习任务。在分类任务中,它拥有像逻辑回归、支持向量机、决策树、随机森林等经典算法,可以准确地将数据划分到不同的类别中。比如在垃圾邮件识别中,利用逻辑回归算法对邮件内容进行分析,判断其是否为垃圾邮件;在回归任务里,线性回归、岭回归、Lasso 回归等算法大显身手,能够对连续型数据进行预测,预测房屋价格,根据房屋的面积、房龄、地理位置等特征,运用线性回归算法预测出合理的价格;聚类算法如 K-Means、DBSCAN 等,可以在无监督的情况下,将数据按照相似性进行分组,对用户行为数据进行聚类分析,找出具有相似行为模式的用户群体;降维算法主成分分析(PCA)、线性判别分析(LDA)等,则能帮助我们在保留数据主要特征的同时,降低数据的维度,减少计算量和存储空间,在图像识别中,使用 PCA 算法对图像数据进行降维处理,提高处理效率。
(二)为何选择 Scikit-learn
Scikit-learn 之所以备受青睐,是因为它具有诸多显著的优势,易用性便是其一。Scikit-learn 拥有简洁而一致的 API 设计,这使得无论是机器学习的新手还是经验丰富的专家,都能快速上手。以构建一个简单的分类模型为例,只需要短短几行代码,就能完成从数据加载、模型训练到预测的整个流程。假设我们要对鸢尾花数据集进行分类,使用 Scikit-learn 的代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归模型并训练
model = LogisticRegression()
model.fit(X_train, y_train)
# 进行预测并评估准确率
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"分类准确率: {accuracy}")这段代码清晰地展示了 Scikit-learn 的易用性,即使是没有深厚机器学习基础的人,也能轻松理解和掌握。
Scikit-learn 还拥有丰富的算法和工具。它几乎涵盖了所有常见的机器学习算法,从简单的线性回归到复杂的深度学习模型(虽然对深度学习的支持相对有限,但在传统机器学习领域非常全面),以及各种数据预处理、模型评估和调优的工具。无论面对何种机器学习任务,都能在 Scikit-learn 中找到合适的算法和工具。比如在处理文本数据时,它提供了词袋模型、TF-IDF 等文本特征提取方法,以及朴素贝叶斯、支持向量机等适合文本分类的算法;在处理图像数据时,虽然它不像专门的深度学习框架那样强大,但也能通过一些传统的图像处理算法和机器学习算法相结合的方式,实现简单的图像识别任务。
在机器学习的学习和实践过程中,遇到问题是不可避免的,而 Scikit-learn 拥有活跃的社区和丰富的文档,这为用户提供了强大的支持。当我们在使用 Scikit-learn 时遇到问题,可以在社区论坛上提问,众多的开发者和数据科学家会热情地提供帮助和建议。同时,Scikit-learn 官方网站上的文档非常详细,包括 API 文档、用户指南、教程和示例代码等,这些资源能够帮助我们快速了解和掌握 Scikit-learn 的使用方法。
此外,Scikit-learn 还具有广泛的应用场景,在金融领域,它可以用于风险评估、信用评分、股票价格预测等;在医疗领域,能够辅助疾病诊断、预测疾病发展趋势、分析药物疗效等;在电商领域,常用于用户行为分析、商品推荐、精准营销等;在工业领域,可用于设备故障预测、质量控制、生产优化等。可以说,只要有数据和机器学习需求的地方,Scikit-learn 都能发挥重要作用。
三、核心功能大揭秘
(一)数据预处理
在机器学习中,数据预处理就像是烹饪前的准备工作,将原始数据清洗、转换,使其成为适合模型 “消化” 的形式,直接影响着后续模型的性能和效果。Scikit-learn 提供了一系列强大的数据预处理工具,能够帮助我们轻松应对各种数据问题。
标准化(Standardization)是一种常用的数据预处理方法,它通过将数据转换为均值为 0、标准差为 1 的分布,使得不同特征之间具有可比性。在 Scikit-learn 中,我们可以使用StandardScaler来实现标准化。例如:
from sklearn.preprocessing import StandardScaler
import numpy as np
# 生成一些示例数据
data = np.array([[1, 2], [3, 4], [5, 6]])
# 创建StandardScaler对象并进行标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)这段代码中,StandardScaler的fit_transform方法首先计算数据的均值和标准差,然后根据这些统计量对数据进行标准化转换。
归一化(Normalization)则是将数据缩放到一个特定的区间,通常是 [0, 1] 或 [-1, 1]。Scikit-learn 中的MinMaxScaler可以实现这一功能。示例如下:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6]])
# 创建MinMaxScaler对象并进行归一化
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
print(normalized_data)在这个例子中,MinMaxScaler将数据的每个特征缩放到 [0, 1] 区间,使得数据的取值范围更加统一。
现实世界中的数据往往存在缺失值,这些缺失值如果不处理,可能会影响模型的训练和预测效果。Scikit-learn 提供了SimpleImputer来处理缺失值。它可以使用指定的策略(如均值、中位数、众数等)来填充缺失值。比如:
from sklearn.impute import SimpleImputer
import numpy as np
# 包含缺失值的示例数据
data = np.array([[1, np.nan], [3, 4], [np.nan, 6]])
# 使用均值策略填充缺失值
imputer = SimpleImputer(strategy='mean')
imputed_dat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











