






1、数据简介
国家创新型城市试点政策是中国建设创新型国家、实施创新驱动发展战略的重要体现。为应对改革开放以来科技创新能力不足的挑战,国务院于2005年颁布了《国家中长期科学和技术发展规划纲要(2006—2020)》(国发[2005]44号),提出要把建设创新型国家作为面向未来的重大战略选择。
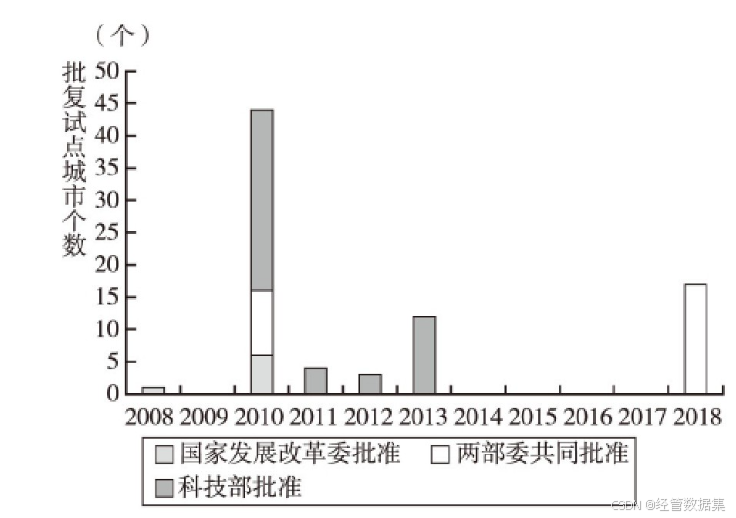
2008年开始“试点先行、积累经验、逐步推开”渐进式创新型城市建设的实践尝试,批准深圳-这一依托改革开放具有先行体制优势的城市作为全国首个国家创新型城市试点。2010年,科学技术部(简称“科技部”)颁布的《关于进一步推进创新型城市试点工作的指导意见》(国科发体[2010]155号,简称《意见》)指出,城市是区域经济社会发展的中心,是各类创新要素和资源的集聚地,城市发展对区域和国家发展全局影响重大,要推动一批城市率先进入创新型城市行列,为更多城市走上创新发展道路形成示范引导作用。
从图中可以看出,2010年国家创新型城市试点批准量达到整个渐进式改革进程的最大规模,其中,国家发展和改革委员会(简称“国家发展改革委”)批准大连等16个城市,科技部批准北京市海淀区等第一批20个城市(区)、河北石家庄等第二批18个城市(区)为国家创新型试点城市(区)。2016年底,科技部、国家发展改革委联合印发《建设创新型城市工作指引》(国科发创[2016]370号,简称《指引》),将科技部、国家发展改革委前期批准的创新型城市(区)进行整合,形成了61个创新型城市试点名单。2017年,61个创新型城市试点均通过了实地验收。目前,两部委累计批准78个国家创新型试点城市(区),包括72个地级市、4个直辖市城区和2个县级市。
数据名称:创新型城市试点名单最新数据
数据年份:2006-2023年
2、指标
年份、省份编号、省份、城市、ID、城市编号、城市等级、municipalities(是否直辖市)、general(是否地级市(排除直辖、省会、副省级))、east(是否东部城市)、mid(是否中部城市)、west(是否西部城市)、northeast(是否东北部城市)、e_ne(是否东部+东北部城市)、innovation(是否创新试点城市)
3、数据截图
【下载→
方式一(推荐):主页 个人 简介
方式二:数据下载方式汇总-CSDN博客

















 2338
2338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









