



昨天通义千问又又又开源了两个小尺寸模型,分别是Qwen3-4B-Instruct-2507 和 Qwen3-4B-Thinking-2507。
并且在非推理领域,Qwen3-4B-Instruct-2507 全面超越了闭源的 GPT4.1-Nano。
既然只有4B,我就想在我的IOS手机上安装一下,于是我上网搜了一下有哪些现成的App可以在IOS上部署开源大模型,果然被我找到了一个可用的。
有一个开源项目pocketpal:https://github.com/a-ghorbani/pocketpal-ai
PocketPal AI 是一款由小型语言模型驱动的口袋式 AI 助手,可直接在您的手机上运行。并且IOS和Android都可以运行。
目前在IOS的AppStore和Android的谷歌商店都能搜索到。
整个过程也很简单,只需要三步:
- 下载App
- 从huggingface上下载对应的大模型
- 选择模型
这三步走完就能够在手机上和小模型进行对话。因为官方没提供量化版本的模型,用的是其他人提供的。
下载完App后,具体操作步骤截图如下:
点击模型下载
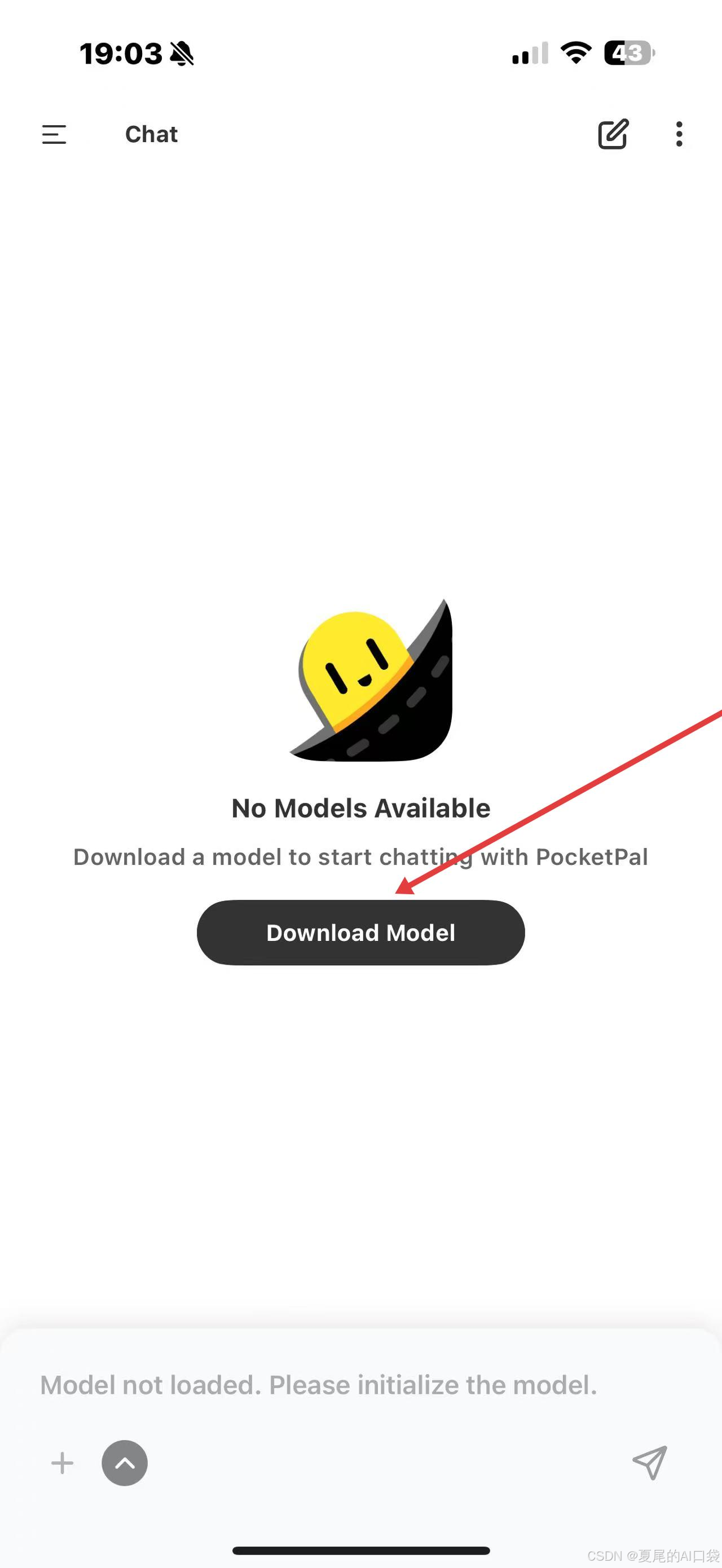
选择从Huggingface添加模型

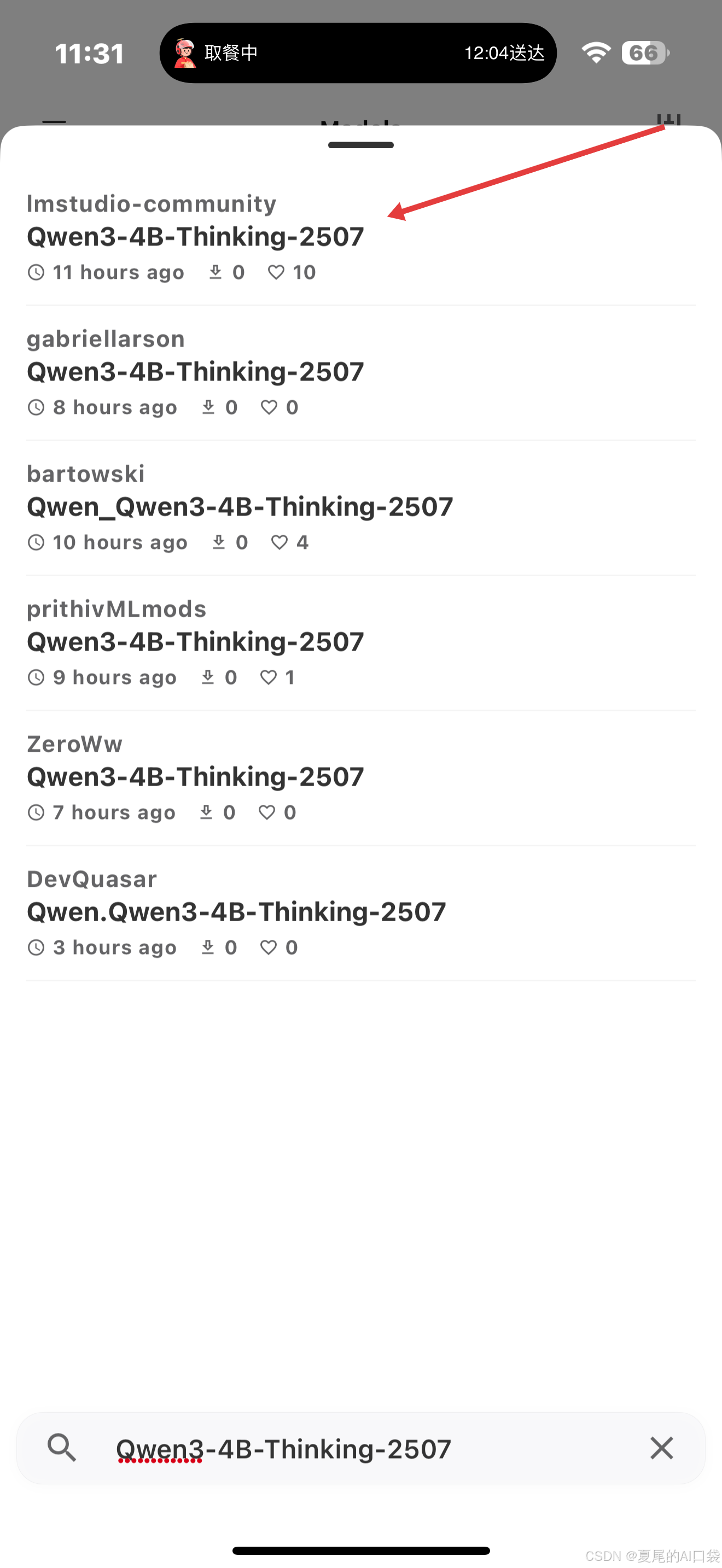
搜索Qwen3-4B相关的模型
下载模型文件
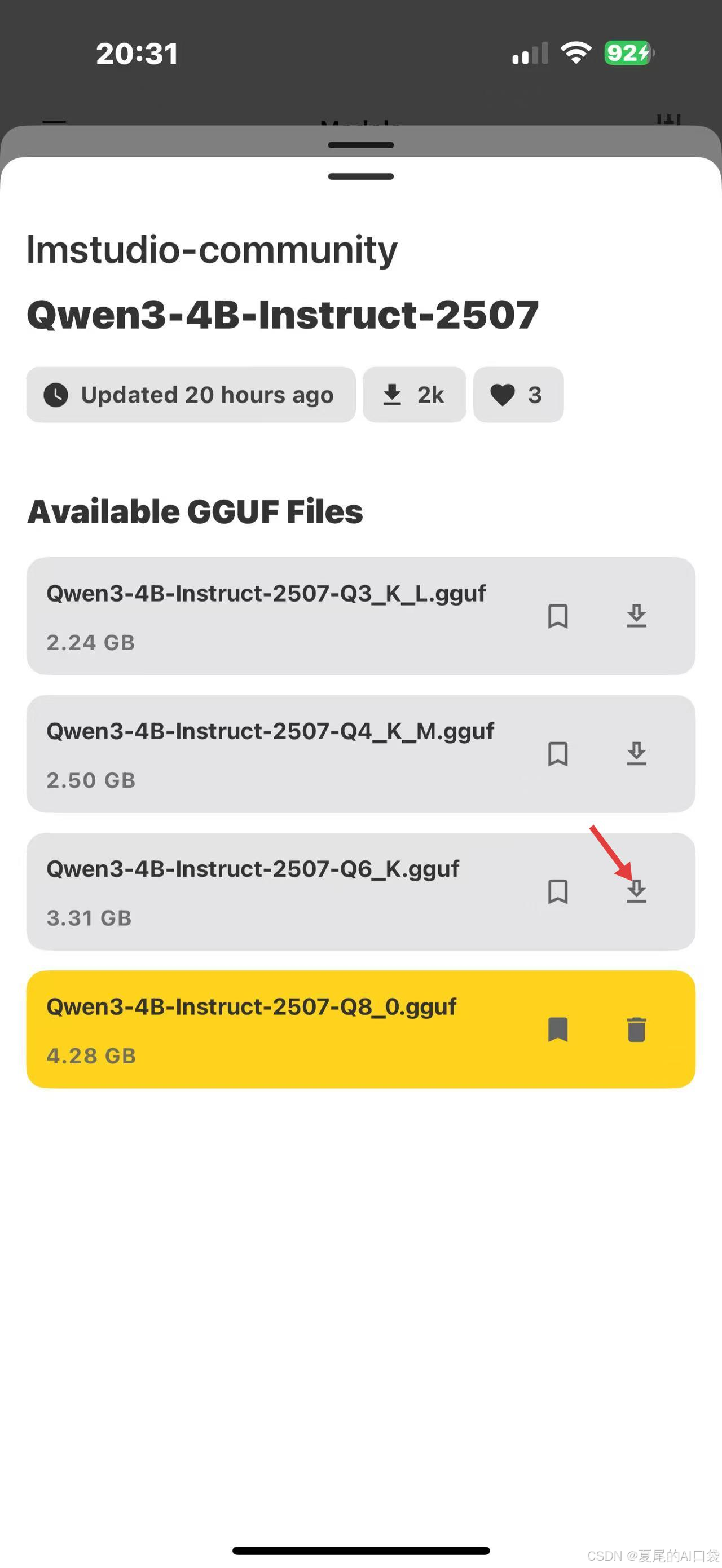
回到页面,选择模型后就能直接使用了

好啦,到这结束了,快去试试吧


















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









