 K近邻算法(KNN)详解与实战
K近邻算法(KNN)详解与实战








 本文介绍了K近邻算法的基本思想,即通过寻找与新实例最邻近的K个训练实例进行分类,并探讨了K值选择、距离度量和分类决策规则的重要性。还分享了基于《机器学习实战》中的KNN约会分析的实战代码,以及算法的优缺点,指出KNN精度高、对异常值不敏感,但存在K值选择和计算复杂度高的问题。
本文介绍了K近邻算法的基本思想,即通过寻找与新实例最邻近的K个训练实例进行分类,并探讨了K值选择、距离度量和分类决策规则的重要性。还分享了基于《机器学习实战》中的KNN约会分析的实战代码,以及算法的优缺点,指出KNN精度高、对异常值不敏感,但存在K值选择和计算复杂度高的问题。
一.基本思想
K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。如下面的图:
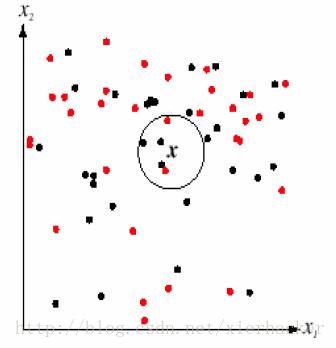
通俗一点来说,就是找最“邻近”的伙伴,通过这些伙伴的类别来看自己的类别。比如以性格和做过的事情为判断特征,和你最邻近的10个人中(这里暂且设k=10),有8个是医生,有2个是强盗。那么你是医生的可能性更加大,就把你划到医生的类别里面去,这就算是K近邻的思想。
K近邻思想是非常非常简单直观的思想。非常符合人类的直觉,易于理解。
至此,K近邻算法的核心思想就这么多了。
K值选择,距离度量,分类决策规则是K近邻法的三个基本要素.
从K近邻的思想可以知道,K近邻算法是离不开对于特征之间“距离”的表征的,至于一些常见的距离,参考:
机器学习笔记八:常见“距离”归纳
二.实战
这一部分的数据集《机器学习实战》中的KNN约会分析,代码按照自己的风格改了一部分内容。
首先是读取数据部分(data.py):
import numpy as np
def creatData(filename):
#打开文件,并且读入整个文件到一个字符串里面
file=open(filename)
lines=file.readlines()
sizeOfRecord=len(lines)
#开始初始化数据集矩阵和标签
group=np.zeros((sizeOfRecord,3))
labels=[]
row=0
#这里从文件读取存到二维数组的手法记住
for line in lines:
line=line.strip()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









