







转载于“机器之心”专栏的介绍和剖析: https://zhuanlan.zhihu.com/p/27013861?utm_source=qq&utm_medium=social
对机器学习算法进行分类不是一件容易的事情,总的来看,有如下几种方式:生成与判别、参数与非参数、监督与非监督等等。
在机器学习中,有个定理被称为「没有免费的午餐」。简而言之,就是说没有一个算法可以完美解决所有问题,而且这对于监督学习(即对预测的建模)而言尤其如此。
在本次梳理中,我们将涵盖目前「三大」最常见机器学习任务:回归方法,分类方法,聚类方法。
1、回归方法
回归方法是一种对数值型连续随机变量进行预测和建模的监督学习算法。使用案例一般包括房价预测、股票走势或测试成绩等连续变化的案例。
回归任务的特点是标注的数据集具有数值型的目标变量。也就是说,每一个观察样本都有一个数值型的标注真值以监督算法。
1.1 线性回归(正则化)
线性回归是处理回归任务最常用的算法之一。该算法的形式十分简单,它期望使用一个超平面拟合数据集(只有两个变量的时候就是一条直线)。如果数据集中的变量存在线性关系,那么其就能拟合地非常好。

在实践中,简单的线性回归通常被使用正则化的回归方法(LASSO、Ridge 和 Elastic-Net)所代替。正则化其实就是一种对过多回归系数采取惩罚以减少过拟合风险的技术。当然,我们还得确定惩罚强度以让模型在欠拟合和过拟合之间达到平衡。
优点:线性回归的理解与解释都十分直观,并且还能通过正则化来降低过拟合的风险。另外,线性模型很容易使用随机梯度下降和新数据更新模型权重。
缺点:线性回归在变量是非线性关系的时候表现很差。并且其也不够灵活以捕捉更复杂的模式,添加正确的交互项或使用多项式很困难并需要大量时间。
1.2 回归树(集成方法)
回归树(决策树的一种)通过将数据集重复分割为不同的分支而实现分层学习,分割的标准是最大化每一次分离的信息增益。这种分支结构让回归树很自然地学习到非线性关系。
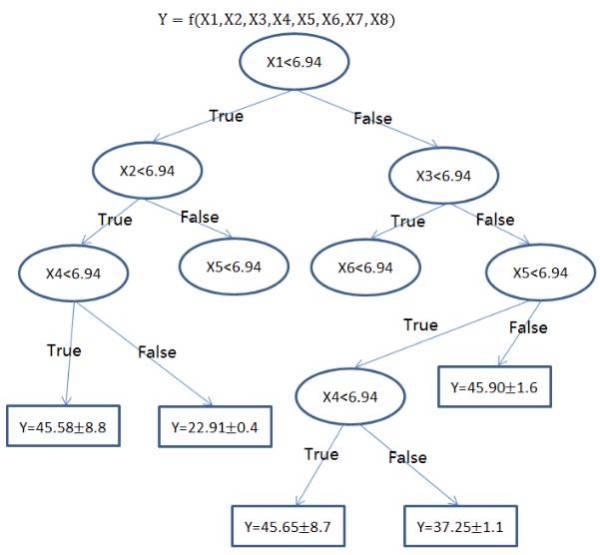
集成方法,如随机森林(RF)或梯度提升树(GBM)则组合了许多独立训练的树。这种算法的主要思想就是组合多个弱学习算法而成为一种强学习算法,不过这里并不会具体地展开。在实践中 RF 通常很容易有出色的表现,而 GBM 则更难调参,不过通常梯度提升树具有更高的性能上限。
优点:决策树能学习非线性关系,对异常值也具有很强的鲁棒性。集成学习在实践中表现非常好,其经常赢得许多经典的(非深度学习)机器学习竞赛。
缺点:无约束的,单棵树很容易过拟合,因为单棵树可以保留分支(不剪枝),并直到其记住了训练数据。集成方法可以削弱这一缺点的影响。
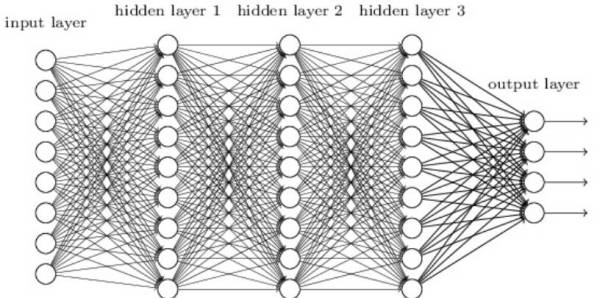
1.3 深度学习
深度学习是指能学习极其复杂模式的多层神经网络。该算法使用在输入层和输出层之间的隐藏层对数据的中间表征建模,这也是其他算法很难学到的部分。
深度学习还有其他几个重要的机制,如卷积和 drop-out 等,这些机制令该算法能有效地学习到高维数据。然而深度学习相对于其他算法需要更多的数据,因为其有更大数量级的参数需要估计。
优点:深度学习是目前某些领域最先进的技术,如计算机视觉和语音识别等。深度神经网络在图像、音频和文本等数据上表现优异,并且该算法也很容易对新数据使用反向传播算法更新模型参数。它们的架构(即层级的数量和结构)能够适应于多种问题,并且隐藏层也减少了算法对特征工程的依赖。
缺点:深度学习算法通常不适合作为通用目的的算法,因为其需要大量的数据。实际上,深度学习通常在经典机器学习问题上并没有集成方法表现得好。另外,其在训练上是计算密集型的,所以这就需要更富经验的人进行调参(即设置架构和超参数)以减少训练时间。















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









